

 Login
Login

 May 15, 2026
May 15, 2026|
Voiced by Amazon Polly |
Overview
This is Part 3 of our series on Slowly Changing Dimensions on AWS. Part 1 covered SCD types and core AWS patterns. Part 2 addressed limitations, edge cases, and advanced modeling. This installment walks through five real industry scenarios where SCD decisions have concrete business consequences, and ties together the considerations from both previous guides.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Why is real-world SCD harder than the textbook?
In theory, picking an SCD type is a clean decision. Does history matter? Use Type 2. Does only the current value matter? Use Type 1. In practice, the same dimension table often contains attributes that belong to different SCD types, source systems behave badly, business requirements change after data is already in production, and the query patterns analysts actually use don’t match the patterns the pipeline was designed for.
The five scenarios below each expose a different class of production friction, and the architectural decisions that resolve it.
Scenario 1: E-commerce — customer address and loyalty tier
A single dim_customer table routinely mixes all four SCD types across its columns. shipping_address must be Type 2 because revenue attribution models ask “what region was this customer in when they placed this order?”, a question that becomes unanswerable if addresses are overwritten. loyalty_tier is also Type 2 because the discount rate depends on the tier that was active at the time of the order. But email and preferred_name are Type 1: no historical query ever needs to know what someone’s email was in 2022.
The critical production consideration here is the metadata-driven framework from Part 2. Hardcoding Type 1 vs Type 2 logic per column means every new attribute requires a pipeline code change and deployment. Storing the mapping in a control table and having the AWS Glue job read it at runtime reduces dimension onboarding from a sprint ticket to a config change.

Key consideration: Any attribute classified as Type 1 should require sign-off from both engineering and analytics. Once history is gone, a retrospective cohort study that depends on that attribute becomes impossible. This is not a recoverable mistake.
Scenario 2: Telecom — subscriber plan changes and billing accuracy
The telecom billing scenario exposes the most common SCD Type 2 production mistake: joining on the natural key rather than the surrogate key during the fact load. If fact_billing stores subscriber_id instead of subscriber_sk, every historical billing query will resolve to the current plan version, making it appear that every customer was always on their latest plan. Revenue by plan becomes completely wrong.
The AWS Glue job must resolve the natural key to the active surrogate key (where is_current = true) at load time, before writing the fact row. This is a one-way door: once fact rows are written with the wrong key, correcting them requires a full restatement of the fact table.

Key consideration: Add a pipeline data quality check that verifies subscriber_sk in every incoming fact batch resolves to a current dimension row. Orphaned surrogate keys that appear when a fact arrives before the corresponding dimension update are silent and corrupt downstream reports.
Scenario 3: Financial services — account status with bitemporal requirements
This is where standard SCD Type 2 hits a regulatory wall. Financial regulators routinely request account history as it was understood at a specific past date, not as it is understood today, with corrections applied. A standard Type 2 table conflates these two concepts.
The diagram makes the difference concrete. In January, the account appeared Active, which was the truth as understood at that time. A correction loaded in June revealed the account was actually suspended from March through May. A regulator asking “what did your system show in January?” needs the pre-correction answer. A risk model asking “what was the actual account status in April?” needs the post-correction answer. Standard Type 2 collapses both into a single timeline and can answer only one.

Key consideration: On AWS, Apache Iceberg on S3 partially handles the transaction-time axis via snapshot metadata, you can time-travel to a past snapshot to see what the table contained at that load timestamp. But if you need to query across the transaction-time axis in SQL (filtering by load_from and load_to), you still need explicit columns. Iceberg time-travel and explicit bitemporal columns solve slightly different problems and can be combined.
Scenario 4: Retail — product category reassignment and surrogate key collision on retry
Retail product catalog pipelines are particularly vulnerable to retry-induced surrogate key collisions because product category changes frequently coincide with promotional campaigns, exactly when pipelines are under load and most likely to fail and retry. The diagram shows why generating surrogate keys inside the AWS Glue job using Python’s uuid() is unsafe. Each retry generates a new UUID, producing duplicate dimension rows that fan out against fact table joins and silently double-count revenue.
The fix is to let Amazon Redshift’s IDENTITY column generate the surrogate key inside the atomic BEGIN/COMMIT block. A retry will attempt the insert again, but the unique constraint on (product_id, effective_date) will reject it, preventing a duplicate without requiring any retry-detection logic in the AWS Glue job itself.
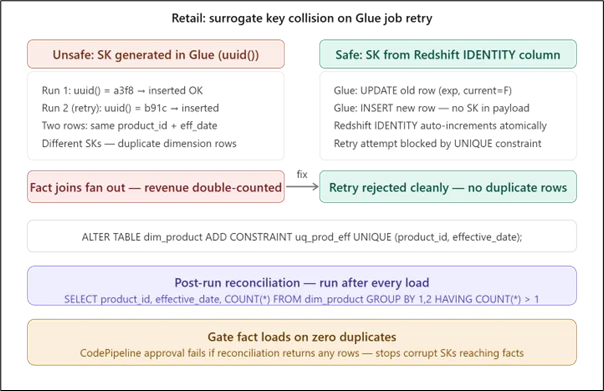
Key consideration: The post-run reconciliation query should be a mandatory pipeline step, not an optional audit. Wire it into the AWS CodePipeline stage between the dimension load and the fact table load. If it returns any rows, stop the pipeline. A duplicate SK in the dimension table is invisible until an analyst notices inflated revenue figures, at which point the damage has propagated into every downstream report.
Scenario 5: Healthcare — patient demographic changes with late-arriving records
This is the scenario where all three advanced concepts converge: bitemporal modeling for auditability, late-arrival handling for source data quality, and the record_type = DELETED pattern for patient record merges.
Healthcare adds two constraints that don’t appear in other industries. First, patient records are legally regulated, and audit trails must demonstrate what data was in the system at every point in time, independent of subsequent corrections. This makes the source_event_time column non-negotiable: the pipeline must carry it through from the EHR source system, and the late-arrival detection logic must compare it against the current effective date on every load.
Second, patient record merges, when two medical record numbers (MRNs) are discovered to belong to the same patient, must not physically delete the retired MRN’s history. Instead, the retired record gets a final version row with record_type = MERGED and a merge_target_id pointing to the surviving MRN. Every historical encounter tied to the retired MRN remains intact and queryable; only new encounters are routed to the surviving record.
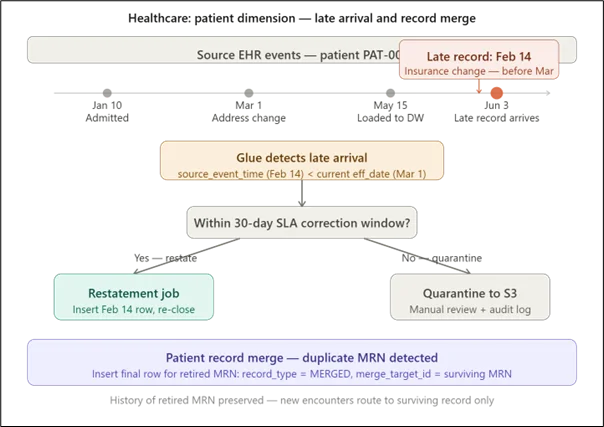
Key consideration: Late-arrival SLA windows must be defined and enforced at the pipeline level before go-live, not after the first incident. A 30-day correction window is reasonable for most healthcare source systems. Beyond that window, automatic restatement becomes dangerous, correcting one historical window may invalidate downstream report snapshots that compliance teams have already signed off. The quarantine-to-S3 path, with a manual review gate, is the safer default for out-of-window arrivals.
Cross-scenario production checklist
Pulling the considerations from all five scenarios together into a single reference:

Conclusion
The five scenarios above span very different industries, but the failure modes cluster around the same handful of root causes: Type 1 decisions made without fully considering future analytical needs, surrogate keys generated outside the database transaction, late-arriving data processed without a source event timestamp, and test suites that validate current state instead of historical sequence.
The common thread across all of them is that SCD correctness is a pipeline property, not a schema property. A perfectly designed dimension table can be silently corrupted by a Glue job that retries badly, a fact load that joins on the wrong key, or a hard delete that leaves no audit trail. The production checklist above is the gap between a working prototype and a warehouse you can trust to drive business decisions.
Drop a query if you have any questions regarding SCD, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is the biggest mistake when implementing SCD Type 2 in production?
ANS: – The most common mistake is joining fact tables using natural keys rather than surrogate keys, leading to incorrect historical reporting.
2. Why is SCD implementation more complex in real-world scenarios?
ANS: – Because a single dimension can contain multiple SCD types, source data can be inconsistent, and business requirements can evolve after deployment.
3. How can late-arriving data impact SCD pipelines?
ANS: – Late-arriving data can overwrite or misalign historical records if source event timestamps and proper validation logic are not enforced.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments