

 Login
Login

 April 20, 2026
April 20, 2026|
Voiced by Amazon Polly |
Introduction
In modern data engineering, one of the most persistent challenges is managing changes to dimension data over time. When a customer moves cities, a product changes category, or an employee shifts departments, the data warehouse must decide whether to overwrite the old value or preserve history. This decision defines what the industry calls Slowly Changing Dimensions, or SCDs. First formalized by Ralph Kimball, SCDs describe a family of strategies for tracking dimensional changes that support current reporting and historical analysis. This guide covers each SCD type with real AWS implementation patterns, SQL examples, and pipeline architecture.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Slowly Changing Dimensions
A dimension table provides descriptive context around measurable facts. Customer name, product category, and employee department are typical dimension attributes. Unlike fact data, these attributes change infrequently, but when they do, each change must be handled deliberately.
SCD Types with AWS Scenarios
Type 0: Fixed Attributes
Some attributes must never change once written. A customer’s original account-open year or a contract’s signing date should remain immutable regardless of what the source system sends. On AWS, this is enforced in AWS Glue by filtering update operations for designated columns before data reaches Redshift.
Type 1: Overwrite
Type 1 replaces the old value with the new one, discarding history entirely. This suits attributes like email addresses, where only the current value matters. A retail company that updates customer contact data simply overwrites the old record. In Redshift, this is implemented via a MERGE statement from a Glue-managed staging table:
|
1 2 3 4 |
MERGE INTO dim_customer USING staging_customer AS src ON dim_customer.customer_id = src.customer_id WHEN MATCHED THEN UPDATE SET email = src.email, city = src.city WHEN NOT MATCHED THEN INSERT (customer_id, name, email, city) VALUES (src.*); |
Type 2: Add a New Row
Type 2 is the most widely used SCD strategy. When an attribute changes, the current row is closed by setting an expiry date and flipping an is_current flag to false, and a new row is inserted with the updated values. A telecom company tracking subscriber plan changes needs this pattern to support historical billing analysis. The dimension table includes surrogate keys, effective and expiry dates, and a current flag:
|
1 2 3 4 5 6 7 8 |
CREATE TABLE dim_subscriber ( subscriber_sk BIGINT IDENTITY(1,1) PRIMARY KEY, subscriber_id VARCHAR(50), plan_name VARCHAR(100), effective_date DATE, expiry_date DATE, is_current BOOLEAN DEFAULT TRUE ); |
The AWS Glue job stages incoming data in Amazon S3, loads it to an Amazon Redshift staging table, then runs a transaction that closes the old row and inserts the new one. Atomicity is guaranteed by wrapping both operations in a BEGIN/COMMIT block.
Type 3: Add a New Column
Type 3 stores exactly one prior value by adding a previous value column alongside the current one. A logistics company restructuring sales territories may only need to compare current assignments with previous assignments. The ETL job shifts the current column value into the previous column before writing the new value. This is simple but inflexible, supporting only a single generation of change.
Type 6: Hybrid
Type 6 combines Types 1, 2, and 3. Each version row includes the new value (Type 2), a previous-value column (Type 3), and the denormalized current value across all historical rows (Type 1). This enables analysts to quickly filter current records, access historical context, and simplify reporting joins. It is common in customer analytics platforms.
AWS Architecture for SCD Pipelines
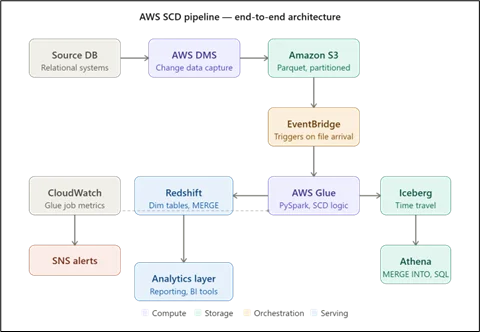

A production SCD pipeline on AWS follows a standard layered pattern. Raw data lands in Amazon S3 via AWS DMS change data capture from relational source systems, partitioned by entity and date. An EventBridge rule triggers an AWS Glue workflow on new data arrival. The Glue job, written in PySpark, reads the incoming delta, resolves the CDC operation type (INSERT, UPDATE, DELETE), compares against existing dimension records using the natural business key, and executes the appropriate SCD logic. For lakehouse architectures, Apache Iceberg on S3 with Athena supports MERGE INTO natively, adding time-travel query capability alongside the standard SCD version history. Redshift serves as the analytical serving layer, with dimension tables distributed by surrogate key and sorted on effective_date and is_current for optimized query performance.
End-to-End SCD Type 2 Pipeline Steps
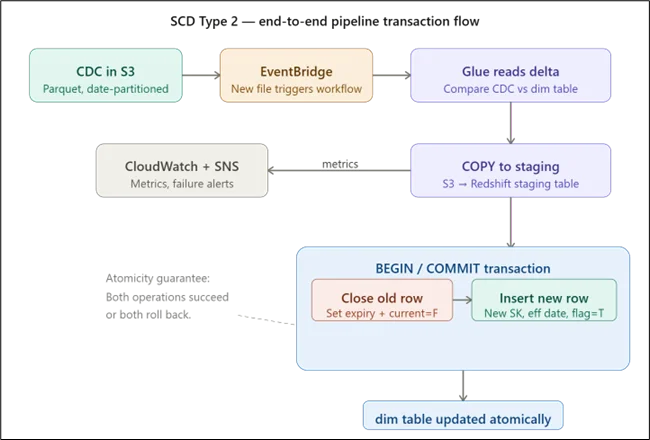
- Source CDC data lands in Amazon S3 in Parquet format, partitioned by date.
- Amazon EventBridge triggers an AWS Glue workflow when a new file arrives.
- Glue reads the delta, identifies UPDATE records, and compares tracked SCD columns against the current Amazon Redshift dimension row.
- Changed records are loaded to an Amazon Redshift staging table via a COPY command from Amazon S3.
- A transaction block closes the old row and inserts the new version with updated effective dates and surrogate key.
- Amazon CloudWatch captures Glue job metrics. Amazon SNS sends alerts on failure.
Conclusion
Slowly Changing Dimensions are fundamental to handling evolving data in a data warehouse, but the right approach depends on business needs, whether prioritizing simplicity, history, or performance. From Type 1 overwrites to Type 2 versioning and hybrid models, each strategy serves a specific purpose in balancing accuracy and efficiency.
On AWS, implementing SCD effectively requires a well-designed pipeline using services like Amazon S3, AWS Glue, and Amazon Redshift, along with clear handling of change detection and data consistency. Ultimately, choosing the right SCD type and architecture ensures reliable reporting, scalable pipelines, and meaningful historical insights.
Refer here for Part 2 and Part 3.
Drop a query if you have any questions regarding SCD and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. When should I use SCD Type 2 versus Iceberg time-travel for historical queries?
ANS: – Use Type 2 when queries need explicit effective_date and is_current columns for filtering and joining in standard SQL. Use Iceberg time travel when you need a full table snapshot at any point in the past without schema changes.
2. How do I handle late-arriving data that affects closed SCD Type 2 rows?
ANS: – Store a source_event_time column alongside load_timestamp. When the Glue job detects a source event time earlier than the current row’s effective_date, trigger a restatement job that corrects the affected historical window.
3. Does SCD Type 2 work with Amazon Redshift Serverless?
ANS: – Yes. Amazon Redshift Serverless supports MERGE, transactions, and staging tables identically to provisioned clusters. Size the base RPU for your largest SCD batch to avoid query queuing during ETL windows.
- Amazon Redshift dimension row.
- Changed records are loaded to an Amazon Redshift staging table via a COPY command from Amazon S3.
- A transaction block closes the old row and inserts the new version with updated effective dates and surrogate key.
- Amazon CloudWatch captures metrics for AWS Glue jobs. Amazon SNS sends alerts on failure.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments