

 Login
Login

 April 20, 2026
April 20, 2026|
Voiced by Amazon Polly |
Introduction
Part 1 covered SCD types and their AWS implementation patterns. In production, theoretical models meet real-world friction. Type 2 tables grow without bound. Source systems send data that violates pipeline assumptions. Late-arriving records corrupt historical windows. Surrogate key collisions appear after retries. This guide addresses those realities, covering limitations of each SCD type, common exception scenarios, AWS cost implications, and guidance on when SCD is the wrong choice. It also introduces bitemporal modeling and metadata-driven frameworks for teams managing SCD at scale.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Limitations of Each SCD Type
Type 1: Permanent Loss of History
Type 1’s core limitation is irreversibility: once a value is overwritten, it is gone. This creates risk when an attribute classified as Type 1 later proves analytically important. Customer address data treated as Type 1 for fulfillment cannot support a geographic cohort study requested eighteen months later. Every Type 1 classification should carry a documented business justification and be treated as a permanent historical data decision.
Type 2: Table Bloat and Query Performance
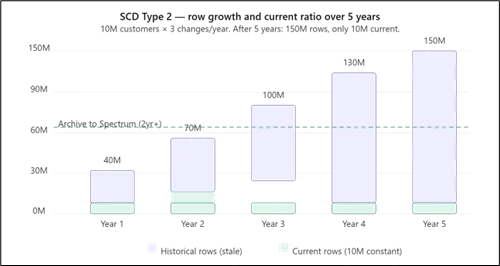
SCD Type 2 generates continuous row growth. A 10 million customer dimension with three changes per year adds 30 million rows annually. After five years, only 10 million of 150 million rows are current. Queries omitting is_current = true scan the full table, causing severe slowdowns in Amazon Redshift. Mitigation includes VACUUM and ANALYZE scheduling and tiering rows older than two years to Amazon S3 via Amazon Redshift Spectrum, which allows the same SQL queries to span hot and cold storage at lower cost.
Type 2: Surrogate Key Collisions on Retry
Generating surrogate keys in the AWS Glue ETL layer using uuid() or row numbers can cause collisions when pipelines retry, resulting in duplicate rows with identical business keys and effective dates. Surrogate key generation must happen inside the database using Amazon Redshift IDENTITY columns within the merge transaction, not in the ETL job.
Type 3: Schema Fragility
Type 3 embeds the maximum number of historical values into the schema as fixed columns. Changing that limit requires an Amazon Redshift ALTER TABLE, which forces a full table rebuild at large scale. Type 3 also fails silently: a third change overwrites the second previous value without any error or audit trail.
Type 6: Mass Update Overhead
Type 6 requires updating the denormalized current value across all historical rows on every new version insert. In Amazon Redshift, each UPDATE is internally a DELETE plus INSERT. For a customer with 20 historical rows, one attribute change triggers 20 row rewrites. This becomes a significant bottleneck across millions of customers.
Edge Cases and Exception Scenarios
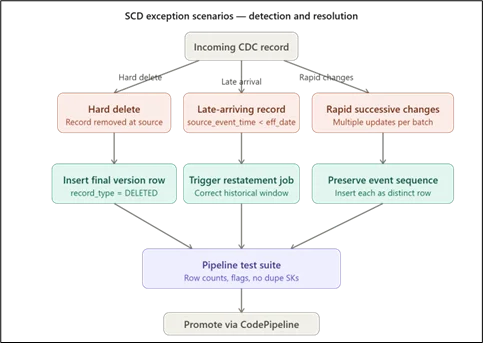
Rapid Successive Changes in One Batch
When a source system sends multiple updates for the same entity within one ETL batch window, standard SCD Type 2 logic may collapse them into a single change, discarding intermediate states. If those states have business value, the CDC pipeline must carry source-side event sequencing, and the Glue job must process each event as a distinct row insertion.
Hard Deletes from Source Systems
Hard deletes create a gap between the SCD table and the source. The preferred approach is to insert a final version row with record_type set to DELETED and a populated deletion_date, preserving version history while clearly marking entity termination.
Retroactive Corrections and Bitemporal Modeling
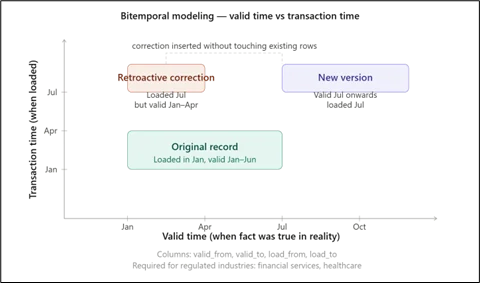
Standard SCD pipelines process data in arrival order and cannot handle retroactive corrections. Bitemporal modeling adds two time axes: valid time (when the fact was true in reality) and transaction time (when it was loaded). Columns such as valid_from, valid_to, load_from, and load_to enable retroactive inserts without corrupting the existing history, which is required in regulated industries such as financial services and healthcare.
Cost Implications on AWS
Type 2 row growth increases Amazon Redshift storage and compute costs. Tier rows older than two years to Amazon S3 via Amazon Redshift Spectrum, which charges per terabyte scanned rather than at the cluster level and supports the same SQL queries. AWS Glue Type 2 jobs are more compute-intensive than append jobs due to row-level comparison joins. Partitioning staging data by business key prefix before the join reduces shuffle and lowers DPU-hours. For Iceberg-based SCD, schedule compaction jobs via Glue or EMR to consolidate accumulated metadata files and reduce S3 request costs.
When Not to Use SCD
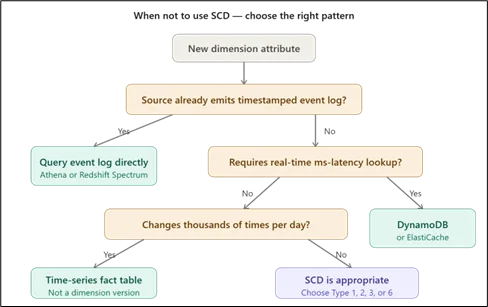
SCD is not always appropriate. If the source system already emits a complete event log with timestamps per state change, applying SCD duplicates storage and adds unnecessary complexity. Query the event log directly using Amazon Athena or Amazon Redshift Spectrum. For real-time dimension resolution requiring millisecond latency, SCD Type 2 surrogate key lookups are too slow; use Amazon DynamoDB or Amazon ElastiCache instead. Dimensions that change thousands of times per entity per day are not truly slowly changing and should be modeled as time-series facts rather than dimension versions.
Metadata-Driven SCD Frameworks
As dimension count grows, hand-coding SCD logic per table is unsustainable. A metadata-driven approach stores SCD configuration in a control table defining, per dimension, which columns are Type 1 or Type 2, the business key, and the effective date source. The AWS Glue job reads this at runtime and dynamically generates comparison and merge logic, reducing onboarding time and ensuring consistent behavior across the warehouse.
Testing SCD Pipelines
SCD correctness depends on the sequence of historical data, not just the current state. Key practices: unit tests for column-change detection with synthetic inputs; integration tests seeding a staging environment with known state and validating row counts and flags after each batch; row reconciliation checks verifying closed rows plus new rows balance against incoming changes; and duplicate surrogate key checks after every run to catch retry-induced collisions before they reach fact tables.
Conclusion
SCD design goes beyond choosing a type, it requires balancing history, performance, and cost in real-world conditions. Each approach comes with trade-offs, and production challenges such as data growth, retries, and late updates require careful handling through optimized pipelines and scalable patterns.
Refer here for Part 1 and Part 3.
Drop a query if you have any questions regarding SCD and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. How do I archive old SCD Type 2 rows without breaking existing reports?
ANS: – Move rows older than your retention threshold to an S3-backed Amazon Redshift Spectrum external table, then rebuild your dimension view as a UNION ALL of the Amazon Redshift and Spectrum tables. Existing report SQL requires no changes.
2. Can SCD Type 2 be implemented in a real-time streaming pipeline on AWS?
ANS: – Yes, using Apache Flink on Amazon Kinesis Data Analytics with a stateful processor that maintains current dimension state in memory or Amazon DynamoDB. Exactly-once semantics must be enforced to prevent duplicate version rows on retry.
3. What is the safest way to test SCD pipeline changes before production deployment?
ANS: – Maintain a staging Amazon Redshift environment seeded with a representative subset of production data. Run the updated AWS Glue job against a sample delta file, validate with reconciliation SQL, and promote via AWS CodePipeline only after all checks pass.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments