

 Login
Login

 May 8, 2026
May 8, 2026|
Voiced by Amazon Polly |
Overview
In simple terms, caching means storing frequently accessed data in a temporary storage layer so that future requests for that data can be served faster. Instead of going all the way to a database, API, or disk every time, we keep a copy closer to where it is needed.
Now imagine a system where thousands, or even millions, of users repeatedly request the same data. If each request hits the database, the system will slow down, costs will increase, and scalability will become a major problem. This is where caching comes into the picture.
Caching improves:
- Performance (faster responses)
- Scalability (reduced load on backend systems)
- Cost efficiency (less compute and database usage)
But, as you might already guess, caching is not free from complications. Keeping cached data consistent with the source of truth is always a challenge.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Common Caching Patterns
Let us now discuss some widely used caching patterns. Each pattern has its own advantages and trade-offs, so choosing the right one depends on your use case.
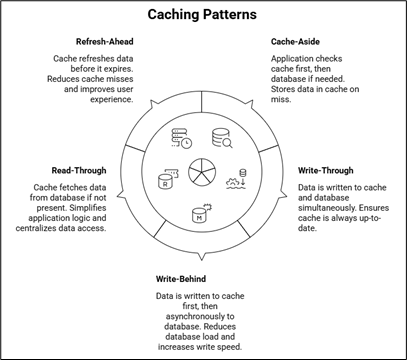
- Cache-Aside (Lazy Loading)
This is probably the most used caching pattern.
How it works:
- Application first checks the cache.
- If data is present → return it (cache hit).
- If data is not present → fetch from database, store it in cache, and return it (cache miss).
Example flow:
- Request comes for the user profile.
- Cache is checked → data not found.
- The database is queried.
- Data is returned and stored in cache.
Pros:
- Simple to implement
- Cache only stores data that is requested
Cons:
- First request is always slow (cache miss)
- Risk of stale data if not invalidated properly
This pattern is very useful when read operations are much more frequent than writes.
- Write-Through Cache
In this pattern, data is written to the cache and the database simultaneously.
How it works:
- Application writes data to cache.
- Cache then writes data to the database.
Pros:
- Cache is always up-to-date
- Read operations are very fast
Cons:
- Write latency increases
- Cache may store unnecessary data (even if never read)
This approach is useful in systems where data consistency is very important and read performance must be high.
- Write-Behind (Write-Back) Cache
Now this one is slightly more interesting.
How it works:
- The application writes data only to the cache.
- Cache asynchronously writes data to the database after some delay.
Pros:
- Very fast write operations
- Reduced database load
Cons:
- Risk of data loss if cache fails before writing to DB
- More complex to implement
This pattern is often used in high-performance systems where write speed is critical, such as logging or analytics platforms.
- Read-Through Cache
In this pattern, the cache itself is responsible for fetching data from the database.
How it works:
- Application directly queries the cache.
- If data is not present, cache fetches it from the database, stores it, and returns it.
Pros:
- Simplifies application logic
- Centralized data access through cache
Cons:
- Adds dependency on the cache layer
- Slightly complex cache configuration
This is useful when you want to abstract database access away from the application.
- Refresh-Ahead Cache
This pattern tries to solve the problem of cache expiration delays.
How it works:
- Cache refreshes data before it expires.
- If data is frequently accessed, it is proactively updated.
Pros:
- Reduces cache misses
- Improves user experience with consistent performance
Cons:
- May refresh unused data
- Additional overhead
This works well for data that is accessed frequently and must stay fresh.
Key Challenges in Caching
Even though caching sounds very beneficial, there are some common challenges:
- Cache Invalidation
This is the famous hard problem in computer science. Deciding when to remove or update cached data is tricky. - Stale Data
Users might see outdated information if the cache is not refreshed properly. - Cache Stampede
When many requests attempt to fetch missing data simultaneously, it can overload the database. - Memory Management
Cache storage is limited, so deciding what to evict (LRU, LFU, etc.) becomes important.
Conclusion
Caching is not just an optimization; in many systems, it becomes a necessity for handling scale and performance requirements. However, choosing the right caching pattern requires careful thinking about consistency, latency, and failure scenarios.
If you are starting, begin with a simple cache-aside approach and observe system behavior. As your application grows, you can introduce more sophisticated strategies, such as write-through or refresh-ahead.
One important thing to remember is that caching introduces its own complexity. So, do not add it blindly everywhere. First, understand your bottlenecks, then apply caching where it actually makes a meaningful difference.
At the end of the day, a well-designed caching strategy can make your system feel fast, responsive, and scalable, but a poorly designed one can create subtle bugs that are quite difficult to debug. So, always design it thoughtfully, test thoroughly, and monitor continuously.
Drop a query if you have any questions regarding Cache and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Which caching pattern should I use in most applications?
ANS: – To be very practical, most applications start with the Cache-Aside pattern because it is simple and flexible. You can gradually move to more advanced patterns, such as write-through or refresh-ahead, depending on performance and consistency requirements. There is no one-size-fits-all solution, so it depends on your system design.
2. How do I handle cache invalidation effectively?
ANS: – Cache invalidation depends on your use case. Some common strategies include:
- Time-based expiration (TTL)
- Event-based invalidation (on data update)
- Manual invalidation for critical flows

WRITTEN BY Hridya Hari
Hridya Hari is a Subject Matter Expert in Data and AIoT at CloudThat. She is a passionate data science enthusiast with expertise in Python, SQL, AWS, and exploratory data analysis.











Comments