

 Login
Login

 May 22, 2026
May 22, 2026|
Voiced by Amazon Polly |
Overview
Enterprise GenAI initiatives often fail not because of weak models, but because the underlying enterprise data lacks structure, quality, governance, and retrieval readiness. Successful AI applications require far more than model access, they depend on clean data pipelines, governed access controls, semantic retrieval layers, and vector-ready architectures that support reliable RAG workflows. This article explores the foundational pillars of GenAI data readiness and outlines a practical AWS-based architecture for building scalable, trustworthy enterprise AI applications.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
The model isn’t the problem. The data is.
Gartner’s 2025 survey puts it plainly: 85% of enterprise AI projects fail to move beyond the pilot stage. Not because foundation models lack capability, they’re remarkably powerful. The failure point is upstream. Inconsistent schemas, stale documents, ungoverned access, and poorly chunked content produce hallucinations that no amount of prompt engineering can fix. Organizations that succeed with GenAI in 2026 share one trait: they invested in data readiness before model selection.
Why is Data the Real Foundation?
GenAI models are pattern machines. They generate responses based on the patterns they find in the data you provide. Feed them inconsistent, outdated, or poorly structured data, and you get hallucinations dressed in confidence.
Here’s what enterprise data readiness actually looks like:
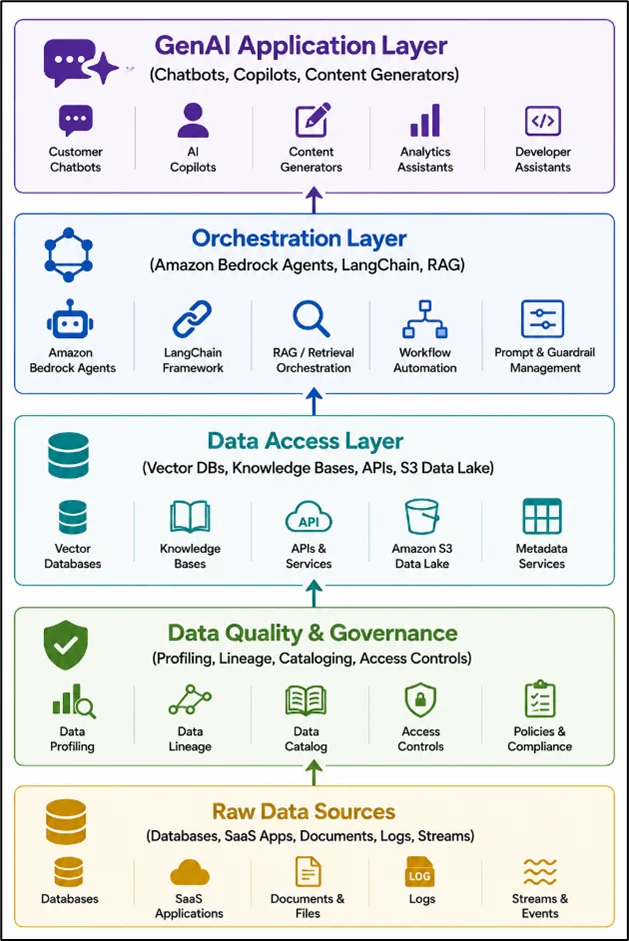
Most teams jump straight from raw data to the application layer. The middle three layers, where the real work lives, get skipped.
The Three Pillars of GenAI Data Readiness
- Data Quality Over Data Quantity
A RAG (Retrieval-Augmented Generation) pipeline that retrieves from a million poorly formatted documents will underperform one that retrieves from ten thousand clean, well-chunked documents.
Practical steps:
- Deduplication — Remove redundant records before they pollute embeddings.
- Freshness enforcement — Tag documents with last-verified dates. Expire stale content automatically.
- Chunking strategy — Split documents semantically (by section, paragraph, or topic) rather than by arbitrary token counts.
- Governance is Not Optional
When your GenAI application answers a compliance question using internal HR documents, you need to know: Who has access to them? Is this data current? Can it be cited?
AWS provides a governance stack that works:
- AWS Glue Data Catalog for metadata management
- AWS Lake Formation for fine-grained access control
- Amazon DataZone for data sharing with business context
- Vector-Ready Architecture
Traditional databases store rows. GenAI needs embeddings, numerical representations of meaning. Your architecture must support both.
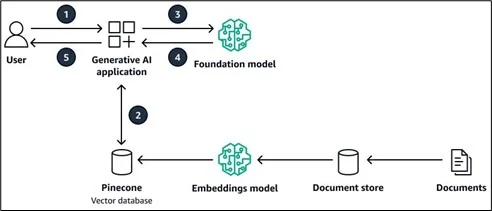
Amazon Bedrock Knowledge Bases handle this pipeline natively, ingesting from Amazon S3, chunking, embedding with Amazon Titan Embeddings, and storing in OpenSearch Serverless. But the data going into Amazon S3 still needs to be clean.
A Real-World Pattern That Works
A healthcare company needed its GenAI assistant to answer clinician questions using internal clinical guidelines. Here’s what worked:
- Curated a source-of-truth Amazon S3 bucket — Only approved, version-controlled documents landed here.
- Built a metadata layer — Each document tagged with department, approval date, and review cycle.
- Used Bedrock Knowledge Bases — Automated chunking and embedding with guardrails for sensitive content.
- Implemented feedback loops — Clinicians flagged bad answers, which triggered data reviews, not model retraining.
The result 92% answer accuracy within three months, with zero hallucination incidents on compliance-sensitive topics.
Conclusion
Drop a query if you have any questions regarding Amazon Bedrock Knowledge Bases and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Do I need a data lake before starting with GenAI?
ANS: – Not necessarily. You need organized, accessible, and quality-controlled data. A well-structured Amazon S3 bucket with proper metadata can serve as your starting point. A full data lake is ideal for scale, but not a prerequisite for a pilot.
2. How does RAG reduce hallucinations?
ANS: – RAG grounds the model’s responses in your actual data by retrieving relevant documents before generating an answer. The model synthesizes from retrieved content rather than relying solely on its training data, significantly reducing fabricated responses.
3. What's the minimum data governance needed for a GenAI pilot?
ANS: – At minimum: access controls (who can read what), data freshness tracking (when was this last verified), and a feedback mechanism (how do users report bad outputs back to the data team).
4. How do I measure data readiness for GenAI?
ANS: – Track three metrics: completeness (percentage of records with all required fields), freshness (percentage of documents updated within their review cycle), and retrievability (can your RAG pipeline find the right document for a given query at least 80% of the time).

WRITTEN BY Vignesh J
Vignesh Jagadeesan is the Head of Presales at CloudThat with 12+ years of experience driving digital transformation for Public Sector, SMB, and Enterprise customers across India and the USA. He specializes in Cloud Consulting, Data Management, MDM, Analytics, and enterprise modernization. Vignesh has led transformation engagements spanning cloud adoption, analytics, managed services, and enterprise solutioning across government, BFSI, healthcare, retail, manufacturing, and energy sectors, partnering with business stakeholders and cloud partners to deliver scalable, outcome-driven solutions.










Comments