

 Login
Login- Consulting
- Training
- Partners
- About Us
x
Cloud Computing, Data Analytics
 6 Mins Read
6 Mins Read

 August 9, 2022
August 9, 2022
Apache Spark, an open-source cluster framework, is an improvement over Hadoop. It leverages the use of in-memory computations to achieve high-speed data processing compared to Hadoop (MapReduce), which is slower as the I/O operations are done in HDFS (Hadoop Distributed File System). In Hadoop, the I/O operations in HDFS are necessarily required for coordination and fault tolerance, which are intermediate writes to HDFS. As the task grow and are coordinated (Via MapReduce) to achieve the results, the intermediate data must be written to the HDFS, which may not be required by the user and hence creating additional costs in terms of disk usage.
Spark addresses these issues using an abstraction known as “Resilient Distributed datasets” (RDDs) — data is distributed in the cluster and is stored and computed in the memory (RAM) of the nodes of that cluster, thus eliminating the intermediary disk writes. The total execution or the data flow takes the shape of a Directed Acyclic Graph (DAG), where each execution step represents a node and the edge of its transformation/action, resulting in the next execution step. As a result, through lazy evaluation, we can parallelize and optimize computations, particularly iterative calculations. In the following visualization, we can see a lineage or step of transformation done in stages using DAG, which makes it easier to track all the steps, and in case of a failure, we can roll back.

Foundation of the Spark, it provides distributed task dispatching, scheduling, and all the basic I/O operations, abstractions, and API for different languages such as Java, Python, Scala, .NET, and R.
It is a component built on top of the Spark core itself. An abstraction known as DataFrames is provided for the same to run Domain-specific language in Java, Scala, Python, and . NET. It provides full SQL language support.
Due to the fast-scheduling ability of the Spark Engine, streaming analytics is possible. The data is ingested in mini-batches, and RDD transformations are performed on those mini-batches.
Spark provides a machine learning library on top of its core and due to its fast computation processing, achieved through distributed in-memory architecture, it is much faster. It can run many ML algorithms such as logistic regression, linear regression, Random Forest, etc.
It is a component built on top of the core for faster-distributed graph processing. It provides two APIs for implementing algorithms such as PageRank through an abstraction known as Pregel abstraction.
Spark offers an essential abstraction, a collection of fault-tolerant and immutable objects. The records stored in an RDD are divided into partitions for parallel computations in the Spark cluster. The objects are distributed to each node of the Spark cluster for processing. Spark loads the data from a disk and keeps it in memory where it is processed, thereby achieving caching/persistence only to be reused later if needed. This makes data processing faster in Spark than in Hadoop. Spark RDD performs immutability in that when new transformations are applied on that RDD, Spark creates a new RDD and maintains the RDD Lineage and, in-effect achieving fault tolerance. In this blog, we will explore this abstraction.
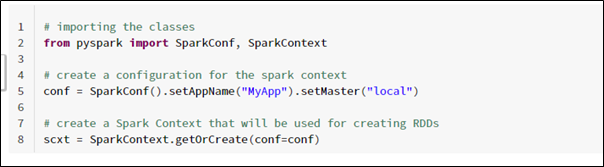
PySpark, an open-source framework, is the python API for Apache Spark. If you are familiar with python, it makes Spark easy to use.
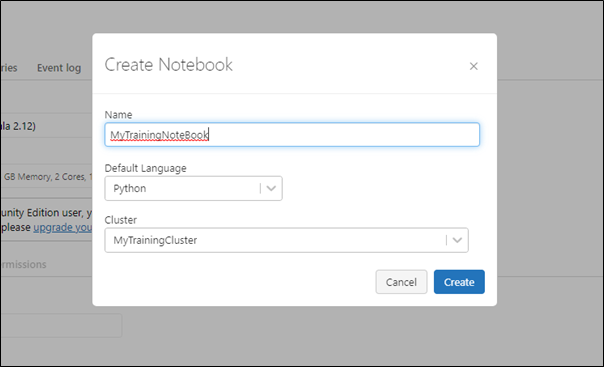
I will use PySpark Databricks Community Edition as it is free to use. We will explore all some common transformations on RDDs.


 To convert the RDD back to a python list, we can use the collect() method on that RDD
To convert the RDD back to a python list, we can use the collect() method on that RDD
RDDs transformations are a way to transform or update one RDD to another. Because of the immutable nature of the RDDs, transformations applied always create a new RDD without updating an existing one, and hence a lineage is created. They are also “Lazy evaluations” meaning that no transformations get executed until an action is called on RDD itself.
There are a couple of transformations that Spark provides. For example:
Map() – applies a function on the dataset and returns the transformation of the same dataset

FlatMap() – if the dataset contains an array, it will convert each element in that array as one, a long row

Filter() – returns a new RDD after applying a function to filter on a dataset

Union() – Similar to set operation, it combines two datasets together
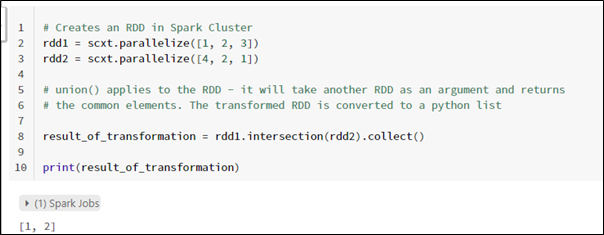
Intersection — Like set operation, it returns a dataset with similar elements

distinct() – it removes any duplicated elements in the dataset

Spark is an excellent enhancement over previous data analytics engines for large-scale data processing. It guarantees speed and fault tolerance, and its services can be used with Python, Scala, and Java. Spark provides both streaming services for streaming analytics and has built-in support for Kafka, Flume, and Kinesis. It includes Machine Learning libraries on top of its core, and since it runs on distributed computing, making the machine learning algorithm faster. Hence, it perfectly uses data streaming, analytics, and machine learning for large-scale datasets.
CloudThat is the official AWS (Amazon Web Services) Advanced Consulting Partner, Microsoft Gold Partner, Google Cloud Partner, and Training Partner helping people develop knowledge of the cloud and help their businesses aim for higher goals using best-in-industry cloud computing practices and expertise. We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Explore our consulting here.
If you have any queries regarding Apache Spark, PySpark, or Python programming, drop a line below the comments section. I will get back to you at the earliest.
|
Voiced by Amazon Polly |
Shahnawaz is a Research Associate at CloudThat. He is certified as a Microsoft Azure Administrator. He has experience working on Data Analytics, Machine Learning, and AI project migrations on the cloud for clients from various industry domains. He is interested to learn new technologies and write blogs on advanced tech topics.
SHARE



AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AWS, Cloud Training
By Himisha Raval
Jul 14, 2026

AWS, DevOps
By Himisha Raval
Jul 14, 2026



Artificial Intelligence, Data science
By Himisha Raval
Jul 14, 2026
Our support doesn't end here. We have monthly newsletters, study guides, practice questions, and more to assist you in upgrading your cloud career. Subscribe to get them all!

Anusha Shanbhag
Aug 18, 2022
Very informative