

 Login
Login

 July 29, 2025
July 29, 2025|
Voiced by Amazon Polly |
Overview
In recent years, Generative AI models like OpenAI’s GPT have transformed how enterprises think about automation, customer service, and internal knowledge access. While these models are powerful, they come with a key limitation they generate responses based only on the data they were trained on, which can become outdated or irrelevant for enterprise-specific needs. To bridge this gap, a more robust and accurate approach is gaining momentum: Retrieval-Augmented Generation (RAG). This hybrid technique combines the strengths of retrieval-based systems with generative models, making it especially useful for enterprise-level question-answering (Q&A).
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation is an advanced NLP technique that enhances the capabilities of LLMs by feeding them up-to-date, domain-specific knowledge at runtime. Rather than relying solely on pre-trained parameters, RAG works in two main steps:
- Retrieval: When a query is submitted, a retriever module fetches relevant documents or passages from a knowledge base (e.g., company wiki, documents, CRM data).
- Generation: These retrieved documents are then passed to a generative model like GPT, synthesizing a contextual and accurate response.
This results in responses that are fluent and natural and grounded in enterprise-specific knowledge.
Why GPT Alone Isn't Enough for Enterprise Q&A?
While GPT models are excellent at understanding natural language and generating human-like responses, they have a few enterprise-specific limitations:
- Stale Knowledge: GPT-4 and similar models have a training cut-off. They can’t access real-time or recently added company data unless specifically fine-tuned with it.
- Hallucination Risk: LLMs may generate factually incorrect or made-up information, which can be critical in enterprise environments.
- Lack of Personalization: Out-of-the-box models don’t have context about an organization’s unique workflows, terminology, or data architecture.
This is where RAG comes in, providing relevant context dynamically and allowing the model to generate more accurate, explainable, and trustworthy outputs.
How RAG Works in an Enterprise Context?
Imagine a scenario where an employee wants to ask, “What’s our company’s policy on international travel reimbursements?” A traditional GPT model might give a generic answer. But with RAG:
- The system searches internal HR policy documents.
- It retrieves the latest section relevant to international travel.
- The LLM then uses this information to generate a response grounded in company policy.
This ensures that employees, customers, or agents get real-time, policy-compliant, and trustworthy answers, without manual document searches or escalating tickets.
Enterprise Use Cases for RAG
- Internal Knowledge Assistants
Employees can get answers about HR policies, IT processes, onboarding procedures, etc., directly from internal documents. - Customer Support Automation
RAG can pull answers from product manuals, support tickets, and knowledge bases to accurately automate first-level customer queries. - Compliance & Legal Teams
Generate responses using specific clauses from legal documents or regulatory guidelines, reducing risk and time spent in manual review. - Sales Enablement
Equip sales reps with fast answers about product specs, pricing rules, or competitor comparisons using internal sales collateral.
Benefits of RAG for Enterprises
- Accuracy & Trustworthiness: Responses are backed by actual company data.
- Cost-Efficiency: Avoid retraining large models; keep your knowledge base updated.
- Real-Time Updates: Simply updating the underlying documents reflects immediately in responses.
- Explainability: The system can cite sources or show the document snippet it used to answer.
- Customization: Tailor answers to your industry, processes, and compliance standards.
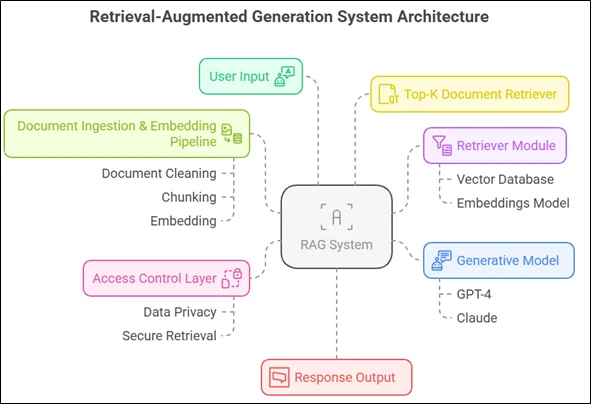
Implementing RAG in Your Organization
To deploy RAG effectively, organizations typically need the following components:
- Vector Database (like FAISS, Pinecone, or OpenSearch) to index and retrieve documents efficiently.
- Embeddings Model to convert documents and queries into semantic vectors.
- Generative Model (e.g., GPT-4, Claude, Mistral) to create the final natural-language response.
- Document Pipeline to ingest, clean, chunk, and embed internal documents.
- Access Control & Security Layers to ensure sensitive data is protected.
Cloud providers like AWS, Azure, and Google Cloud now offer managed services to build RAG pipelines, making enterprise adoption easier.
The Future: RAG as the Backbone of Intelligent Enterprise Assistants
As more companies look to build AI-powered copilots, RAG is emerging as the core architecture behind these systems. It brings context-awareness and up-to-date knowledge to language models and aligns AI outcomes with business objectives.
By combining the fluency of generative AI with the factual grounding of retrieval systems, RAG offers a scalable, flexible, and powerful approach to enterprise-grade question-answering.
Conclusion
If your organization is looking to move beyond the limitations of general-purpose LLMs and create intelligent, context-aware assistants, RAG is the way forward.
Drop a query if you have any questions regarding RAG and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. How does the RAG system ensure the answers are accurate and grounded in enterprise knowledge?
ANS: – The system retrieves content directly from company documents (stored in the Vector Store) before generating a response, ensuring the LLM stays aligned with internal policies and data.
2. What kind of documents can be used in the RAG pipeline?
ANS: – Any enterprise documents like PDFs, HR policies, training guides, knowledge base articles, or legal files can be ingested, chunked, and embedded into the system.

WRITTEN BY Jay Valaki
Jay is a Research Associate at CloudThat with a strong interest in AI, cloud computing, and modern software development. He enjoys exploring innovative technologies, solving real-world problems, and contributing to impactful research. In his free time, he works on personal projects and stays updated with the latest tech trends.











Comments