

 Login
Login

 July 29, 2025
July 29, 2025|
Voiced by Amazon Polly |
Introduction
Manual machine learning workflows may be manageable initially, but as datasets grow and collaboration increases, they often become inefficient and difficult to maintain. Delays, inconsistencies, and lack of reproducibility soon follow.
This blog delves into how AWS CodePipeline, Kubernetes Jobs, and MLflow can be combined to fully automate the ML training process, turning it into a scalable, consistent, and hands-free pipeline from trigger to tracking.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Why Automate the ML Training Workflow?
In dynamic machine learning environments, relying on manual processes to run scripts, adjust parameters, or track outcomes can quickly become a bottleneck. Automation addresses these limitations by offering:
- Consistency – Ensures every model is trained, evaluated, and logged using a standardized process
- Speed – Enables rapid retraining and deployment as soon as new data is available
- Scalability – Accommodates parallel experiments and growing team collaboration
- Reproducibility – Captures all experiment metadata, metrics, and artifacts for future reference
The end-to-end ML lifecycle becomes more efficient, scalable, and reliable by leveraging cloud-native services like AWS CodePipeline for orchestration, Kubernetes Jobs for clean and isolated training runs, and MLflow for comprehensive experiment tracking.
From Event to Execution: How the Automated Training Pipeline Works
The automation pipeline is designed to respond to events, execute model training in a clean environment, and record every detail of the experiment, all without manual involvement. Below is an overview of how each component fits together to make this possible.
Triggering via Pipeline:
The automation begins when a predefined source event occurs, such as an updated configuration pushed to a Git repository or Amazon S3. AWS CodePipeline detects this change and automatically kicks off the pipeline, eliminating the need for manual intervention.
Executing a Kubernetes Job
As part of the pipeline, a specific stage triggers a Kubernetes Job in an Amazon EKS cluster. This job spins up an isolated pod, pulls a Docker image that contains the ML training logic, and uses environment variables or config files to execute the training dynamically.
Logging with MLflow
Upon completion, the training script logs key outputs, including hyperparameters, evaluation metrics, and the model artifact, to MLflow. This provides full visibility into each run, enabling easy comparison and reproducibility across experiments.
This design ensures that model training is event-driven, environment-isolated, and fully trackable, all while reducing the need for human intervention.
Architecture Diagram:
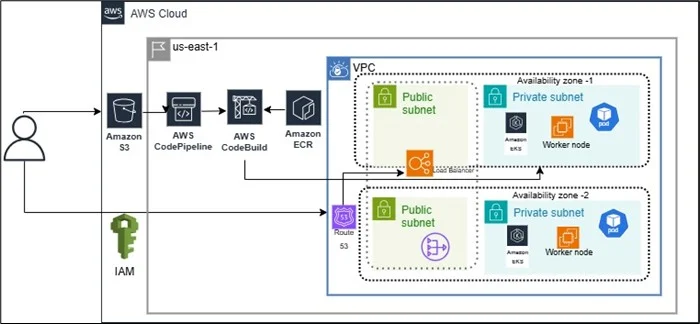
Conclusion
By combining AWS CodePipeline for automation, Kubernetes Jobs for clean and scalable execution, and MLflow for seamless tracking, teams can transform their ML operations to be:
- Easier to maintain
- Faster to deploy
- Robust at scale
This architecture significantly reduces manual intervention, improves consistency, and frees teams to concentrate on what truly matters: building impactful models and driving insights.
Drop a query if you have any questions regarding AWS CodePipeline and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. How secure is this setup for production environments?
ANS: – Security best practices such as using AWS IAM roles with least privilege, network policies in Amazon EKS, encrypted Amazon S3 buckets, and access-controlled MLflow tracking servers can all be implemented to meet enterprise-grade standards.
2. How are configurations passed to the training job?
ANS: – Configurations such as dataset paths, model type, and hyperparameters are typically passed as environment variables or mounted config files in the Kubernetes Job spec. This makes the training process fully dynamic and reusable.

WRITTEN BY Harsha Vardhini M
Harsha works as a Research Intern at CloudThat, passionate about cloud technologies and machine learning. She holds a degree in MSc Software Systems and is exploring innovative solutions in tech and continuously expanding her knowledge in AWS.











Comments