

 Login
Login

 May 29, 2025
May 29, 2025|
Voiced by Amazon Polly |
Introduction
Generative AI models are artificial intelligence models that can create various forms of data, including text, images, video, and code. They learn patterns from existing data and use that knowledge to generate the results. In this blog, we have fine-tuned a preexisting model and then deployed it to the Amazon EKS cluster with Ray Serve and Argo Workflows.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Solution Overview
We will fine-tune a stability diffusion text to image model from a hugging face using Jupyter Notebook, upload it to Amazon S3, and deploy it to Amazon EKS using Argo Workflows by exposing it via Fast API behind Ray Serve.
Infrastructure setup
Complete the steps below before proceeding with the workflow steps.
- Amazon EKS Cluster with worker nodes and GPU nodes as model training will require GPU.
- Install Argo workflow.
- Install Nvidia Device Plugin. This plugin for Kubernetes is a Daemonset that allows you to automatically expose the number of GPUs in each node of the cluster.
- Install Kube Ray Operator, this operator is used to run the RayServe cluster on Amazon EKS. Ray Serve exposes the model in the backend via Fast APIs. Deploy it via helm or manifests.
- Generate a Hugging Face token. This token is required to download the model and data set from Hugging Face.
Steps
- Create a secret for hugging face token with the name hf-token.
- Create a secret with the name gitlab-creds.
- Create a secret with the name regcred for docker-registry.
- Create a service account (e.g., jupyter-sa) in the workflow namespace and add it to the AWS IAM role’s trust policy. The AWS IAM role must have Amazon S3 access for model upload/download and workflow tasks.
- Click on the workflow template and create a new workflow template. Attached is the template that I have used.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 |
apiVersion: argoproj.io/v1alpha1 kind: WorkflowTemplate metadata: name: jupyterhub namespace: jupyterhub spec: templates: - name: train dag: tasks: - name: git-clone template: git-clone - name: run-notebook template: run-notebook dependencies: [git-clone] arguments: parameters: - name: notebook_path value: /home/jovyan/notebook/dogbooth.ipynb - name: docker-push template: docker-push dependencies: [git-clone] - name: ray-serve-deploy template: ray-serve-deploy dependencies: [git-clone,train-model,docker-push] - name: git-clone script: name: '' image: alpine:latest command: - sh env: - name: GIT_USERNAME valueFrom: secretKeyRef: name: gitlab-creds key: GIT_USERNAME - name: GIT_PASSWORD valueFrom: secretKeyRef: name: gitlab-creds key: GIT_PASSWORD resources: {} volumeMounts: - name: workdir mountPath: /workingdir source: >- apk add --no-cache git git clone https://${GIT_USERNAME}:${GIT_PASSWORD}@<giturl> cp -r /genai-poc/ai-ml/terraform/src/* /workingdir - name: run-notebook inputs: parameters: - name: notebook_path container: name: '' image: <image url> command: - papermill args: - '{{inputs.parameters.notebook_path}}' - /workspace/output.ipynb - '--kernel' - python3 - '--log-output' env: - name: HUGGING_FACE_HUB_TOKEN valueFrom: secretKeyRef: name: hf-token key: token resources: limits: nvidia.com/gpu: '1' volumeMounts: - name: workdir mountPath: /home/jovyan/ - name: output mountPath: /workspace - name: shm-volume mountPath: /dev/shm volumes: - name: shm-volume emptyDir: medium: Memory - name: output emptyDir: {} - name: docker-push container: name: '' image: gcr.io/kaniko-project/executor:latest args: - '--context=/workingdir' - '--dockerfile=/workingdir/service/Dockerfile' - '--destination=<username>/<reponame>:rayservedogboothv3' - '--cache-repo==<username>/<reponame>:rayservedogboothv3-cache' - '--snapshot-mode=redo' - '--compressed-caching=false' volumeMounts: - name: workdir mountPath: /workingdir - name: docker-config mountPath: /kaniko/.docker volumes: - name: docker-config secret: secretName: regcred items: - key: .dockerconfigjson path: config.json - name: ray-serve-deploy script: name: '' image: alpine:latest command: - sh resources: {} volumeMounts: - name: workdir mountPath: /workingdir source: apk add --no-cache kubectl kubectl apply -f /workingdir/service/ray-service.yaml entrypoint: train arguments: {} serviceAccountName: jupyter-sa volumeClaimTemplates: - metadata: name: workdir creationTimestamp: null spec: accessModes: - ReadWriteOnce resources: requests: storage: 50Gi status: {} tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule ttlStrategy: secondsAfterCompletion: 600 secondsAfterSuccess: 600 secondsAfterFailure: 600 |
- After the workflow is completed, it will look like this:

- Run command kubectl get pods -n dogbooth to check the status of ray service. Created ray service in the dogbooth namespace.

Template Description
- I have used a DAG (Directed Acyclic Graph) alternative to steps in argo workflows.
- In the above example, I have used four tasks.
a. git-clone: Clones the git repo, copies the necessary data inside /workingdir, and uses this data in subsequent tasks.

b. run-notebook: Fine-tune the model via jupyter-notebook. Used custom Jupyter image, which jupyter notebook, papermill, and rest of the dependencies installed. ipynb handles training, dependency installation, and uploading model to Amazon S3.

c. docker-push: Pushes the image to the docker hub. This image will be used in RayServe manifest. Use –compressed-caching=false as Kaniko takes a snapshot after each step, causing pod memory to go high resulting in pod termination.
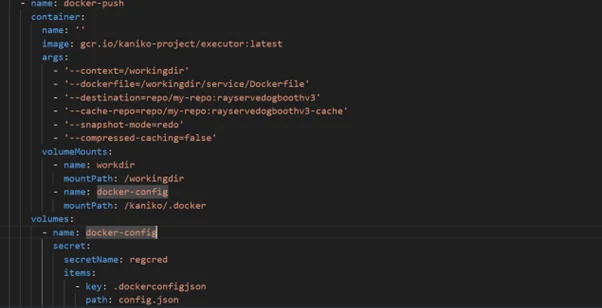
d. ray-serve-deploy: Deploys the built image to eks cluster using ray-service.yaml manifest.

- The Git clone will run first, and run-notebook and docker push will run in parallel as they depend on the git clone. Ray-serve-deploy is dependent on all three, so it will run on last.
- Use taint to taint the node and toleration to schedule all pods on the GPU node, as the run-notebook will require GPU for model training.
- The volume claim template will create a pvc and pv and associate it with the workflow.
Dogbooth.ipynb
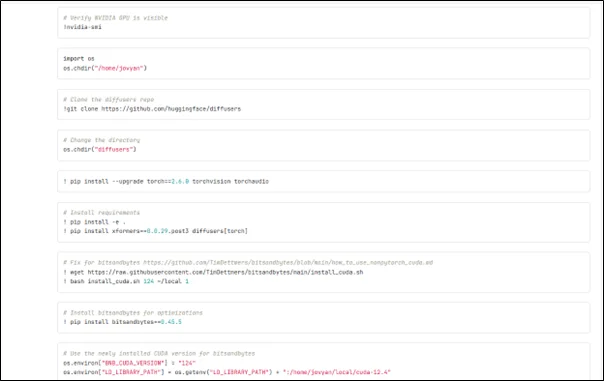
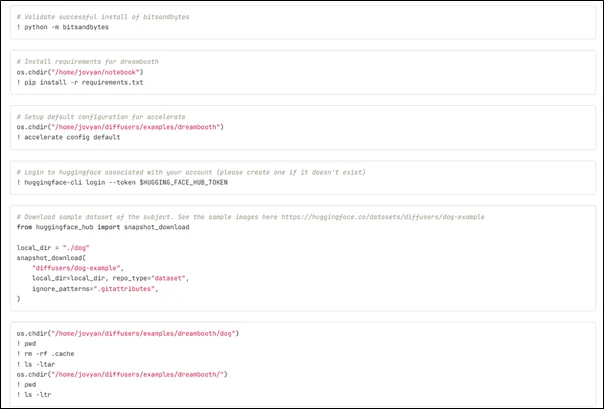
In the dogbooth.ipynb notebook Hugging face token created earlier is used for logging in to Hugging face.

Ray-service.yaml
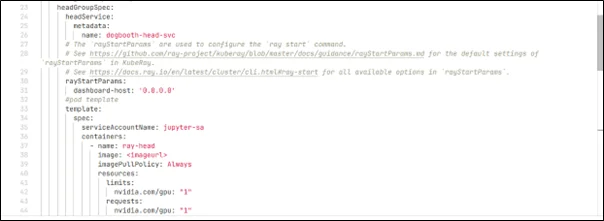
In the ray-service.yaml I have added an ingress section to access the ray dashboard via load balancer DNS or ingress URL. Add service account jupyter-sa in pod spec to download the model from Amazon S3 when the container starts.




Dockerfile
This Dockerfile copies dogbooth.py(FastAPI app) and installs model inference dependencies. It is used in the docker-push task to build rayservedogboothv3 image for ray serve manifests.

Dogbooth.py
In dogbooth.py, a fast API is written to serve the model, and the model is downloaded from Amazon S3 when the container starts.




Key Benefits
- Argo Workflows: Argo Workflow helps in completed CI/CD automation of the model from model training to deployment.
- Ray Serve: Helps expose the backend model via Fast API, enabling scalable, low latency inference. It automatically handles autoscaling based on incoming request volume, reducing operational overhead.
Conclusion
Drop a query if you have any questions regarding Argo Workflows and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. Can we use Argo Workflow for automation rather than ML model CI/CD?
ANS: – Yes, you can use Argo Workflow for any automation.
2. What are the benefits of using Argo Workflow rather than GitHub Actions or GitLab CI/CD?
ANS: – Argo Workflow is designed to run directly on Kubernetes, with each step being a pod. In GitHub Actions and GitLab CI/CD, we need to install custom runners on K8s to run. Argo Worfklow is mostly suitable for long running ML tasks, while the rest are not ideal.

WRITTEN BY Suryansh Srivastava
Suryansh is an experienced DevOps Consultant with a strong background in DevOps, Linux, Ansible, and AWS. He is passionate about optimizing software development processes, ensuring continuous improvement, and enhancing the scalability and security of cloud-based production systems. With a proven ability to bridge the gap between IT and development teams, Surayansh specializes in creating efficient CI/CD pipelines that drive process automation and enable seamless, reliable software delivery.











Comments