

 Login
Login

 September 1, 2025
September 1, 2025|
Voiced by Amazon Polly |
Overview
Data is the new oil in today’s software ecosystem, and how you move it around in your system architecture matters more than ever. Apache Kafka and RabbitMQ are two of the most widely adopted messaging systems, each with strengths and trade-offs. If you’re building a scalable, real-time application or simply trying to decouple services in a microservices architecture, understanding the differences between Kafka and RabbitMQ is essential.
In this blog post, we’ll explore the core concepts, performance characteristics, use cases, and decision points between Kafka and RabbitMQ to help you choose the right tool for your needs.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Apache Kafka
Apache Kafka is a distributed event streaming platform originally developed by LinkedIn and now part of the Apache Software Foundation. Kafka excels at high-throughput, low-latency, fault-tolerant messaging and is designed for real-time analytics and event-driven architecture.
Kafka treats data as a stream of immutable events, which consumers can read from independently, even at different times. It uses a publish-subscribe model where producers write events to topics, and consumers subscribe to them.
Key Features of Kafka:
- Durability: Messages are persisted to disk and replicated across a cluster.
- Scalability: Kafka can handle millions of messages per second and scale across many brokers.
- Replayability: Consumers can replay messages from any point in time.
- Partitioning: Allows parallel processing and horizontal scaling.
RabbitMQ
RabbitMQ is a mature, general-purpose message broker that supports various messaging protocols, such as AMQP (Advanced Message Queuing Protocol). It’s ideal for complex routing, message acknowledgments, and guaranteed delivery in synchronous and asynchronous systems.
Key Features of RabbitMQ:
- Flexible Routing: Exchanges support routing based on keys, headers, topics, or fan-out.
- Acknowledgments & Dead-lettering: Messages can be requeued or dead-lettered if not acknowledged.
- Plugin Architecture: Add features like monitoring, management, or federation easily.
- Wide Protocol Support: Works with AMQP, MQTT, STOMP, HTTP, etc.
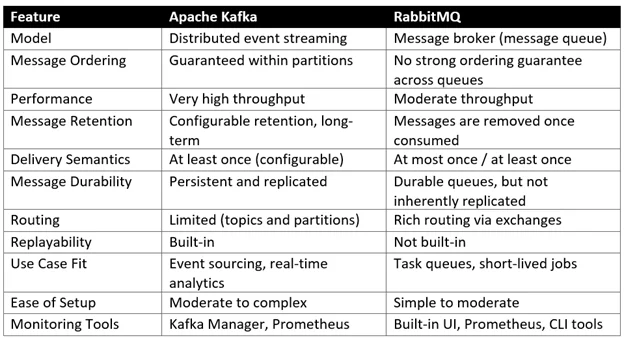
Kafka vs RabbitMQ: Comparison
When to Choose Kafka
- High throughput: Kafka can handle hundreds of thousands of messages per second.
- Persist and replay events: Kafka stores messages for a configurable period, even after they’re consumed.
- Building an event-driven system: Kafka supports multiple independent consumers reading the same data.
- Real-time data processing or stream analytics: Integration with tools like Apache Flink, ksqlDB, or Spark is seamless.
- Strong scalability and fault tolerance: Kafka shines in distributed, large-scale environments.
Common use cases
- Log aggregation
- Real-time fraud detection
- IoT telemetry pipelines
- Clickstream analysis
When to Choose RabbitMQ
- Complex routing: RabbitMQ’s exchange types allow for highly customized message routing.
- Low-latency task delivery: Great for systems where tasks must be executed ASAP (e.g., image processing queues).
- Dealing with legacy systems: RabbitMQ supports multiple protocols and integrates well with older architectures.
- Fine-grained delivery guarantees: Acknowledgments, retries, and dead-lettering are straightforward.
Common use cases
- Background job processing
- Order processing systems
- Inter-service communication in microservices
- Email or SMS notification systems
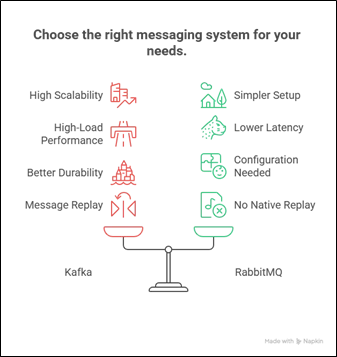
Key Trade-offs
- Scalability vs Simplicity: Kafka is built for scale and data-intensive applications, but has a steeper learning curve. RabbitMQ is easier to set up and operate for simpler workflows.
- Latency: RabbitMQ often has lower end-to-end latency for lightweight messages, but Kafka performs better under high load.
- Durability: Kafka provides better durability and fault tolerance. RabbitMQ requires careful configuration to achieve similar guarantees.
- Message Replay: Kafka allows historical events to be replayed. RabbitMQ does not natively support message replay after consumption.
Conclusion
Apache Kafka and RabbitMQ are powerful tools with overlapping but distinct use cases. Choosing between them depends on your system’s requirements around throughput, durability, message ordering, replayability, and routing complexity.
To summarize:
- Use Kafka for stream processing, high-scale event pipelines, or when replay and persistence are crucial.
- Use RabbitMQ for low-latency message passing, complex routing, or task queues in microservices.
Often, it’s not a matter of choosing one over the other, but using both where they fit best.
Drop a query if you have any questions regarding Apache Kafka or RabbitMQ and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Can Kafka and RabbitMQ be used together?
ANS: – Yes. In many architectures, Kafka and RabbitMQ are used side by side. For example, Kafka can be used as the main data pipeline for storing and analyzing events, while RabbitMQ can handle low-latency task distribution for microservices. Connectors and bridges are available to help with data synchronization between the two.
2. Is Kafka a drop-in replacement for RabbitMQ?
ANS: – No. Kafka and RabbitMQ are fundamentally different in how they handle messages. Kafka is optimized for event streaming and long-term storage, while RabbitMQ is built for transient messaging and task queues. Attempting to replace one with the other without rethinking your system architecture can lead to performance issues or data loss.
3. Which one is better for microservices?
ANS: – It depends on your use case. For simple request-response patterns, RabbitMQ is often a better choice due to its support for routing, acknowledgments, and dead-letter queues. Kafka is generally more suitable for event-driven architectures with multiple consumers or data replay requirements.

WRITTEN BY Hridya Hari
Hridya Hari is a Subject Matter Expert in Data and AIoT at CloudThat. She is a passionate data science enthusiast with expertise in Python, SQL, AWS, and exploratory data analysis.











Comments