

 Login
Login

 May 21, 2026
May 21, 2026|
Voiced by Amazon Polly |
Overview
At first, building an ETL (Extract, Transform, Load) pipeline looks very simple. You extract data from a source, clean it, and load it into a target system, such as a data warehouse. Many teams start with this basic idea and quickly build a working pipeline in just a few days.
But over time, what started as a simple pipeline slowly turns into a complex system that is hard to understand, hard to maintain, and even harder to fix when something breaks. This is why many data engineers say, “ETL starts simple but becomes a nightmare later.”
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Why ETL Pipelines Grow in Complexity
- Growing Data Sources Make Things Complicated
In the beginning, there is usually only one data source, like a database or a single API. But as the business grows, new sources keep getting added, CRM systems, payment gateways, logs, third-party APIs, IoT devices, and more.
Each new source brings:
- Different formats (JSON, CSV, XML)
- Different refresh times
- Different data quality issues
Soon, your simple ETL pipeline becomes a multi-source integration system that is difficult to manage.
- Business Rules Keep Increasing
At first, the transformation logic is simple:
- Remove null values
- Convert data types
- Load into a table
But business teams constantly ask for more:
- Add new KPIs
- Apply filters for regions
- Handle exceptions for specific customers
- Calculate historical comparisons
Each rule adds more layers of logic. Over time, transformation scripts become long and confusing, making debugging very difficult.
- Lack of Standard Design Early On
Many ETL pipelines are built quickly without proper architecture planning. Developers focus on “making it work” instead of “making it scalable.”
This leads to:
- No modular structure
- Hard-coded logic
- Repeated code in multiple jobs
- No proper naming conventions
When new developers join the team, they struggle to understand how everything is connected.
- Data Volume Suddenly Grows
A pipeline that worked fine with 1,000 records may start failing when it processes 10 million records.
Problems include:
- Slow execution
- Memory issues
- Timeout errors
- Increased cost in cloud services
To fix this, engineers add optimizations, partitions, caching, and parallel processing, but each fix adds another layer of complexity.
- Dependency Between Pipelines
In real-world systems, ETL pipelines are rarely independent. One pipeline depends on another.
For example:
- Pipeline A processes raw sales data
- Pipeline B uses the output of A for reporting
- Pipeline C aggregates B’s results
Now, if Pipeline A fails, everything downstream breaks. This chain dependency makes troubleshooting very difficult.
- Frequent Schema Changes
Source systems are not stable. Tables change frequently:
- New columns are added
- Old columns are removed
- Data types change without notice
Each schema change requires updates to the ETL logic. If not handled properly, it can break the entire pipeline or produce incorrect results silently.
- Multiple Teams Working on the Same System
In large organizations, different teams may work on the same data pipeline:
- Data engineers build ingestion
- Analysts modify transformations
- DevOps manages scheduling
Without proper coordination, changes made by one team can unintentionally break another part of the pipeline.
- Orchestration Adds Another Layer
Initially, ETL may run as a simple script. Later, tools like Airflow, Glue, or Step Functions are added for scheduling and monitoring.
While orchestration is useful, it introduces:
- DAG dependencies
- Retry mechanisms
- Logging systems
- Alerting rules
This makes the system more powerful but also more complex to understand.
- Debugging Becomes Time-Consuming
When something fails, finding the root cause is not easy.
You may need to check:
- Source data issues
- Transformation logic errors
- Infrastructure failures
- Downstream impact
A small issue can take hours or even days to identify because of multiple layers in the pipeline.
- No Proper Documentation
One of the biggest reasons ETL becomes a nightmare is the lack of documentation.
Without documentation:
- No one knows the full pipeline flow
- Logic is hidden in scripts
- New engineers take time to understand the system
Eventually, only a few people on the team understand the full system, creating dependency risk.
How Simple ETL Becomes Complex Over Time
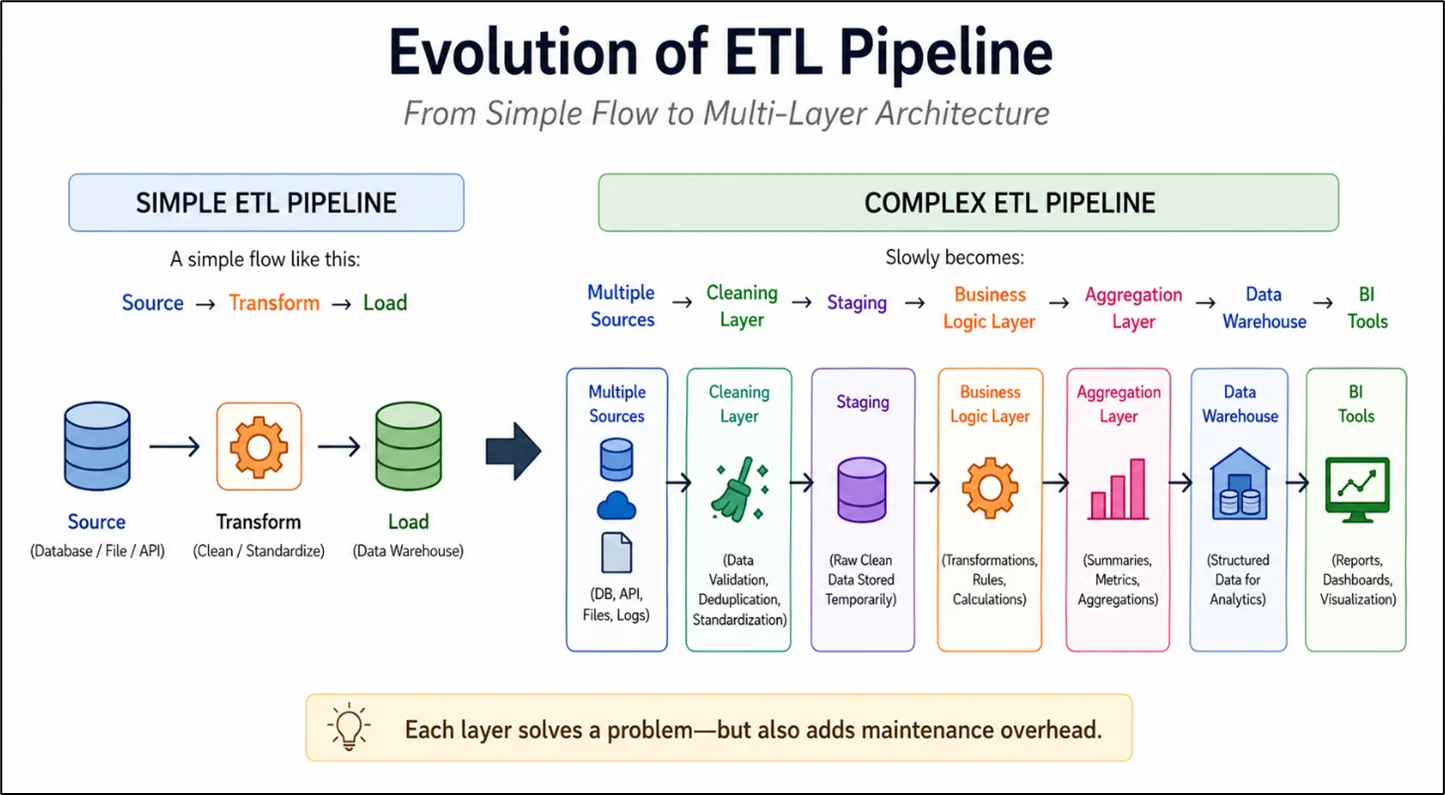
How to Prevent ETL Nightmares
Even though complexity is unavoidable, it can be controlled:
- Design modular pipelines from the start
- Keep transformation logic reusable
- Document every step clearly
- Monitor pipelines properly
- Use version control for ETL scripts
- Avoid over-engineering in the early stages
Good design decisions early can save a lot of pain later.
Conclusion
The key is not to avoid complexity completely, but to manage it in a structured way so that pipelines remain maintainable, scalable, and understandable over time.
Drop a query if you have any questions regarding ETL pipelines, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Why do ETL pipelines become so complex over time?
ANS: – Because data sources, business rules, and dependencies keep increasing, making the system becomes harder to manage.
2. How can we reduce ETL pipeline complexity?
ANS: – By using modular design, proper documentation, reusable logic, and avoiding unnecessary over-engineering early on.

WRITTEN BY Anusha
Anusha works as a Subject Matter Expert at CloudThat. She handles AWS-based data engineering tasks such as building data pipelines, automating workflows, and creating dashboards. She focuses on developing efficient and reliable cloud solutions.










Comments