

 Login
Login

 May 19, 2026
May 19, 2026|
Voiced by Amazon Polly |
Introduction
In today’s digital world, companies generate large amounts of data from websites, applications, customer transactions, finance systems, and operations. This raw data is often unorganized and difficult to use directly for reporting or business decisions. Before data becomes useful, it must be cleaned, structured, and transformed into a reliable format.
Organizations using AWS commonly choose Amazon Redshift as their cloud data warehouse because it offers high performance, scalability, and strong analytics capabilities. However, managing data transformation solely through large SQL scripts in Amazon Redshift can become difficult as projects grow.
This is where dbt (Data Build Tool) becomes valuable. dbt helps data teams transform raw data in Amazon Redshift using SQL while also bringing software engineering practices such as testing, documentation, version control, and modular development. It makes data transformation faster, cleaner, and easier to maintain.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Understanding dbt
DBT stands for Data Build Tool. It is a transformation tool designed mainly for analytics engineering. Unlike traditional ETL tools that extract, transform, and load data outside the warehouse, dbt follows the ELT approach.
In ELT, data is first extracted from source systems and loaded into Amazon Redshift. After loading, dbt performs the transformation directly inside Amazon Redshift using SQL. This reduces unnecessary data movement and improves overall performance.
DBT does not handle extraction or loading. Its main focus is the transformation layer, where raw tables are converted into trusted business-ready datasets.
Why dbt is Useful with Amazon Redshift?
Amazon Redshift is built for large-scale analytics, and dbt works efficiently with it because all transformation queries run directly inside the warehouse.
- Simple SQL-Based Development
Teams can write standard SQL instead of learning complex programming languages. This makes it easier for analysts and engineers to work together.
- Reusable Modular Models
Instead of writing a single large SQL query, dbt allows developers to split the logic into smaller models. These models are easier to manage and reuse.
- Better Data Quality
dbt provides built-in testing features such as null checks, uniqueness checks, and relationship validation to improve trust in reports.
- Automatic Documentation
dbt can generate documentation for tables, columns, and model relationships, helping teams understand the full data flow.
- Git and Version Control Support
Since dbt projects are code-based, teams can use Git for collaboration, reviews, and tracking every change.
- Faster Troubleshooting
Smaller models and clear dependencies make debugging much easier compared to traditional long SQL scripts.
How does DBT work in Amazon Redshift?
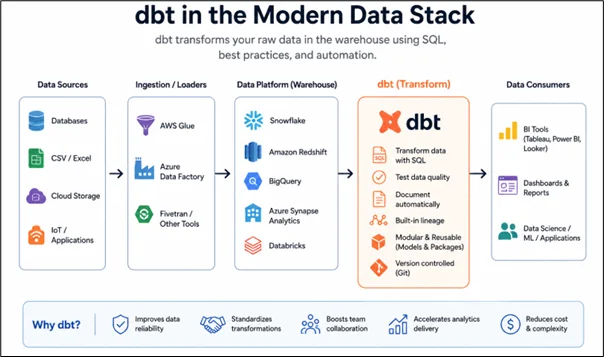
The process usually starts by loading raw data into Amazon Redshift using tools such as AWS Glue, AWS DMS, Lambda, or third-party ingestion platforms.
Once the raw data is available, dbt transforms it through multiple layers, such as:
- Staging models
- Intermediate models
- Reporting or mart models
For example, an order table may contain duplicate records, inconsistent date formats, and missing values. dbt can clean the data, standardize column names, and create a final reporting table for dashboards.
This final clean data can then be used in Amazon QuickSight, Power BI, or any reporting tool.
Important Features of dbt
- Models
Models are SQL files where transformation logic is written. Each model creates a table or view inside Redshift.
- Seeds
Seeds are CSV files loaded into Amazon Redshift using dbt. They are useful for small, static datasets such as state codes or business mappings.
- Snapshots
Snapshots help track historical changes in data over time, especially for slowly changing dimensions.
- Tests
Tests help validate important business rules, such as ensuring customer IDs are unique and that important fields are never null.
- Macros
Macros allow reusable SQL logic using Jinja templates. This reduces repeated code and improves project consistency.
- Incremental Models
Incremental models process only new or changed data instead of rebuilding the full table every time, improving performance.
Best Practices for dbt on Amazon Redshift
- Build a Strong Staging Layer
Always clean source data first before applying business rules. This creates a reliable foundation for reporting models.
- Use Clear Naming Standards
Consistent naming for models and columns improves readability and avoids confusion across teams.
- Add Tests for Critical Tables
Important business datasets should always be validated to prevent incorrect reporting.
- Use Incremental Loads for Large Tables
This reduces execution time and avoids unnecessary warehouse costs.
- Automate Execution
Use orchestration tools like Airflow, AWS Step Functions, or CI/CD pipelines to schedule and monitor dbt runs.
Real Business Example
Consider a retail company storing sales transactions in Amazon Redshift.
The raw table may contain duplicate orders, missing customer details, and inconsistent timestamps. With dbt, the team can:
- Clean duplicate records
- Standardize date formats
- Join the customer master data
- Create daily revenue reports
- Validate data before dashboards are published
This improves reporting accuracy and saves manual effort for analysts.
Conclusion
dbt and Amazon Redshift together create a strong foundation for modern data transformation. Amazon Redshift provides scalable warehouse performance, while dbt adds structure, testing, documentation, and maintainability to the transformation process.
Instead of handling large SQL scripts manually, teams can build reliable and scalable pipelines using modular models and automated validation. This improves data quality, reduces operational effort, and supports faster business decisions.
Drop a query if you have any questions regarding Amazon Redshift, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Is dbt a complete ETL tool?
ANS: – No, dbt mainly handles the transformation part after data is loaded into the warehouse. It focuses on the “T” in ELT.
2. Can dbt work only with Amazon Redshift?
ANS: – No, dbt also supports Snowflake, BigQuery, Databricks, PostgreSQL, and several other modern data platforms.
3. Do I need Python to use dbt?
ANS: – Basic dbt usage mainly requires SQL knowledge. Python is helpful for advanced customization, but it is not mandatory for starting.

WRITTEN BY Anusha
Anusha works as a Subject Matter Expert at CloudThat. She handles AWS-based data engineering tasks such as building data pipelines, automating workflows, and creating dashboards. She focuses on developing efficient and reliable cloud solutions.











Comments