

 Login
Login

 March 12, 2026
March 12, 2026|
Voiced by Amazon Polly |
Introduction
Enterprises today receive massive volumes of unstructured customer feedback through chat applications, emails, social media platforms, and voice-based contact centers. While traditional sentiment analysis systems focus primarily on text, real-world customer interactions often involve audio, where tone, pitch, and speaking pace convey critical emotional context. Relying on text alone can lead to incomplete or misleading interpretations of customer sentiment.
This blog explains how organizations can perform sentiment analysis across text and audio using AWS generative AI services. By combining transcription-based language understanding with audio-native emotion analysis, enterprises can build scalable, accurate, and production-ready sentiment analysis systems on AWS.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Approaches to Sentiment Analysis
Sentiment analysis can be implemented using multiple approaches depending on data availability, accuracy requirements, and operational constraints. The most common approaches are text-based sentiment analysis, audio-based sentiment analysis, and a hybrid multimodal approach that combines both.
In a text-based approach, sentiment is extracted directly from written content such as chat messages, emails, or transcripts. When the input is audio, Amazon Transcribe converts speech to text. The resulting text is then analyzed using natural language processing models available through Amazon Bedrock or managed services such as Amazon Comprehend. This approach is simple to deploy and cost-efficient, but it may miss emotional nuances such as sarcasm, frustration, or urgency that are present in a speaker’s voice.
A hybrid approach combines text-based and audio-based sentiment signals. Text analysis provides linguistic and contextual understanding, while audio analysis captures emotional tone. When combined, these signals produce more reliable sentiment predictions, especially in customer service and call center environments.
End-to-End Workflow Architecture
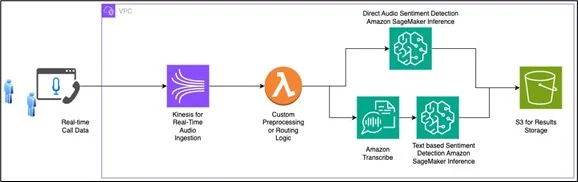
The sentiment analysis workflow begins with data ingestion from multiple sources, including customer chats, support tickets, and call center recordings. Both text and audio data are securely stored in Amazon Simple Storage Service (Amazon S3). For audio inputs, Amazon Transcribe converts speech into text while preserving timestamps and speaker information.
Preprocessing tasks, such as text normalization, filtering, and enrichment, are handled by AWS Lambda. The processed text is sent to Amazon Bedrock, where foundation models such as Amazon Titan or Anthropic Claude are used to classify sentiment. These models are well-suited for understanding ambiguity, context, and language variation.
For audio-based sentiment analysis, audio files are routed to custom machine learning models hosted on Amazon SageMaker AI endpoints. These models analyze acoustic features directly and output sentiment scores. AWS Step Functions can be used to orchestrate the workflow, ensuring reliable execution across services.
The final sentiment outputs are stored in data stores such as Amazon DynamoDB or Amazon Redshift. Visualization and reporting can be performed using Amazon QuickSight to identify sentiment trends and customer experience insights.
Challenges in Multimodal Sentiment Analysis
Text-based sentiment analysis faces challenges related to ambiguity, sarcasm, slang, emojis, and multilingual content. Language evolves rapidly, and models must continuously adapt to new expressions and cultural contexts.
Audio-based sentiment analysis introduces additional complexity, including inconsistent recording quality, background noise, overlapping speakers, and accent variation. Processing large volumes of audio data also requires careful cost and performance optimization.
Security and compliance are critical concerns when handling sensitive customer conversations. Organizations must ensure encryption, access control, and compliance with regional data protection regulations.
Solutions Using AWS Generative AI Services
AWS provides managed services that address these challenges at scale. Amazon Transcribe supports multiple languages, custom vocabularies, and speaker diarization. Amazon Bedrock offers secure access to powerful foundation models without requiring infrastructure management.
Amazon SageMaker AI enables training, tuning, and deployment of custom audio sentiment models. AWS Lambda and AWS Step Functions support event-driven and serverless orchestration, reducing operational overhead. Monitoring and logging are handled through Amazon CloudWatch, while AWS Key Management Service provides encryption and key management.
Conclusion
Combining text and audio sentiment analysis enables a deeper and more accurate understanding of customer emotions. By using AWS generative AI services such as Amazon Bedrock, Amazon Transcribe, and Amazon SageMaker AI, organizations can build scalable, secure, and production-ready sentiment analysis solutions. A hybrid multimodal approach ensures higher accuracy and better customer experience insights, making it a strong foundation for modern AI-driven analytics systems.
Drop a query if you have any questions regarding Amazon SageMaker AI and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is multimodal sentiment analysis?
ANS: – Multimodal sentiment analysis uses multiple data types, such as text and audio, to detect emotional tone more accurately.
2. Why use Amazon Bedrock for sentiment analysis?
ANS: – Amazon Bedrock provides access to advanced foundation models that understand context, nuance, and language variability at scale.
3. Is audio-based sentiment analysis better than text-based?
ANS: – Audio analysis captures emotional cues like tone and stress, but the best results are achieved by combining both approaches.

WRITTEN BY Ahmad Wani
Ahmad works as a Research Associate in the Data and AIoT Department at CloudThat. He specializes in Generative AI, Machine Learning, and Deep Learning, with hands-on experience in building intelligent solutions that leverage advanced AI technologies. Alongside his AI expertise, Ahmad also has a solid understanding of front-end development, working with technologies such as React.js, HTML, and CSS to create seamless and interactive user experiences. In his free time, Ahmad enjoys exploring emerging technologies, playing football, and continuously learning to expand his expertise.











Comments