

 Login
Login

 March 9, 2026
March 9, 2026|
Voiced by Amazon Polly |
As generative AI adoption accelerates across industries, organizations are increasingly seeking ways to make foundation models behave more reliably, safely, and in alignment with business goals. While prompt engineering and supervised fine-tuning have improved model responses, they often fall short in enforcing long-term behavior, ensuring policy adherence, and maintaining decision quality.
This is where reinforcement fine-tuning comes into play.
With the launch of reinforcement fine-tuning capabilities in Amazon Bedrock, AWS has enabled enterprises to further refine foundation models using human or automated feedback loops. This allows models to continuously learn preferred behaviors and optimize their responses based on real-world usage and evaluation signals.
In this blog, we explore how reinforcement fine-tuning works in AWS Bedrock, its benefits, and how organizations can use it to build more trustworthy AI systems.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
What is Reinforcement Fine-Tuning?
Reinforcement fine-tuning is an advanced training approach inspired by reinforcement learning principles. Instead of learning from labelled examples, models learn from feedback signals that reward or penalize specific behaviors.
This approach is commonly referred to as Reinforcement Learning from Human Feedback (RLHF), where:
- The model generates responses
- Human or automated evaluators score those responses
- A reward model is trained on those evaluations
- The foundation model is further fine-tuned using those rewards
In simple terms, reinforcement fine-tuning teaches a model how to behave, not just what to say.
Why Reinforcement Fine-Tuning Matters
Traditional fine-tuning improves factual accuracy and domain knowledge, but reinforcement fine-tuning improves:
- Alignment with organizational policies
- Response quality and tone
- Safety and compliance
- Consistency in decision-making
- Ethical and responsible AI behavior
This makes it ideal for applications such as:
- AI customer support agents
- Healthcare assistants
- Financial advisory bots
- Compliance-driven chatbots
- Internal enterprise copilots
Reinforcement Fine-Tuning in AWS Bedrock
Amazon Bedrock is AWS’s fully managed service for building generative AI applications using foundation models from providers such as Anthropic, Meta, Mistral, Amazon, and others.
With reinforcement fine-tuning, Bedrock enables organizations to refine models using feedback-driven learning loops, all within AWS’s secure and scalable environment.
Key Capabilities
- Native integration with Bedrock foundation models
- Secure data handling and governance
- Scalable training pipelines
- Managed infrastructure
- Support for human feedback workflows
- Compatibility with AWS AI/ML ecosystem
How Reinforcement Fine-Tuning Works in Bedrock
To work with Reinforcement learning in Bedrock, then can set it up from custom models as given below:
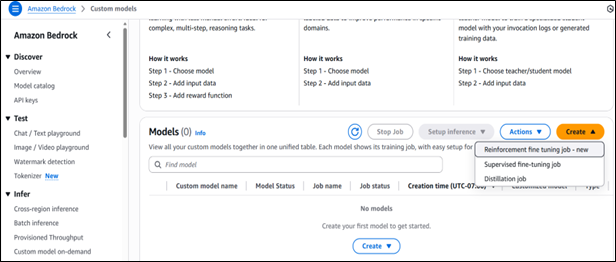
Fig 1: Setting up a reinforcement fine‑tuning job in Amazon Bedrock’s Custom Models interface.
In reinforcement learning, Feedback tells whether the model output is good or bad, which can come from:
- Human reviewers
- Domain experts
- Automated evaluation systems
- Business rule engines
For that, you can set up your reward function either by using Model as Judge or writing your own custom code.
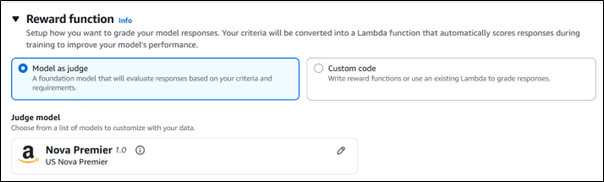
Fig 2: Configuring reward functions in Amazon Bedrock using model‑as‑judge or custom code.
Benefits of Reinforcement Fine-Tuning in Bedrock
- Better Alignment with Business Goals: You can train models to prioritize what matters most, whether that’s customer satisfaction, regulatory compliance, or operational efficiency.
- Improved Safety and Guardrails: Models can learn to avoid unsafe, biased, or policy-violating outputs.
- Higher Response Quality: Over time, models produce more accurate, relevant, and helpful answers.
- Scalable and Secure Training: Bedrock provides enterprise-grade security, monitoring, and governance.
- Reduced Hallucinations: Reward mechanisms can discourage speculative or unsupported responses.
Real-World Use Cases
Organizations across industries are adopting reinforcement fine-tuning for:
- Customer support automation – Training bots to resolve issues more effectively
- Healthcare assistants – Ensuring clinically safe responses
- Legal research bots – Maintaining compliance and accuracy
- HR copilots – Enforcing internal policies and tone
- Banking chatbots – Reducing risk and improving trust
Best Practices
To get the most value from reinforcement fine-tuning in Bedrock, consider these best practices:
- Define clear evaluation criteria
- Use domain experts for feedback
- Balance automation with human review
- Monitor drift and retrain periodically
- Track performance metrics continuously
Future of Aligned AI
Reinforcement fine-tuning in AWS Bedrock represents a powerful evolution in how enterprises build and govern generative AI systems. By allowing models to learn from feedback and optimize behavior over time, organizations can move beyond basic fine-tuning and build AI that is safer, smarter, and better aligned with real-world expectations.
As generative AI becomes more deeply embedded in business operations, reinforcement fine-tuning will play a critical role in ensuring long-term reliability, trust, and performance. With AWS Bedrock and expert partners like CloudThat, enterprises are well-positioned to lead the next wave of responsible AI innovation.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. Is reinforcement fine-tuning expensive?
ANS: – It depends on feedback volume, training frequency, and model size. However, Bedrock’s managed infrastructure helps optimize cost and scalability.
2. Can I use automated feedback instead of human reviewers?
ANS: – Yes. Many organizations combine automated scoring with human validation for efficiency and accuracy.

WRITTEN BY Swati Mathur
Swati Mathur is a Subject Matter Expert at CloudThat, specializing in Cloud Computing and ML\GenAI. With more than 15 years of experience in IT Training and consulting, she has trained over 1000+ professionals and students to upskill in multiple technologies. Known for simplifying complex concepts and delivering interactive, hands-on sessions, she brings deep technical knowledge and practical application into every learning experience. Swati's passion for public speaking and continuous learning reflects in her unique approach to learning and development.











Comments