

 Login
Login

 August 18, 2025
August 18, 2025|
Voiced by Amazon Polly |
Introduction
As organizations increasingly rely on open table formats to manage large-scale data lakes, Apache Iceberg has emerged as a leader for building modern analytics platforms. It brings capabilities like ACID transactions, schema evolution, and hidden partitioning, perfect for the needs of scalable, cloud-native data lakes on Amazon S3.
AWS has introduced sort and Z-order compaction for Iceberg tables to enhance performance further. These new techniques optimize how data is organized in Amazon S3, significantly reducing query time and data scanned, without changing your existing queries or table structure.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Architecture Diagram
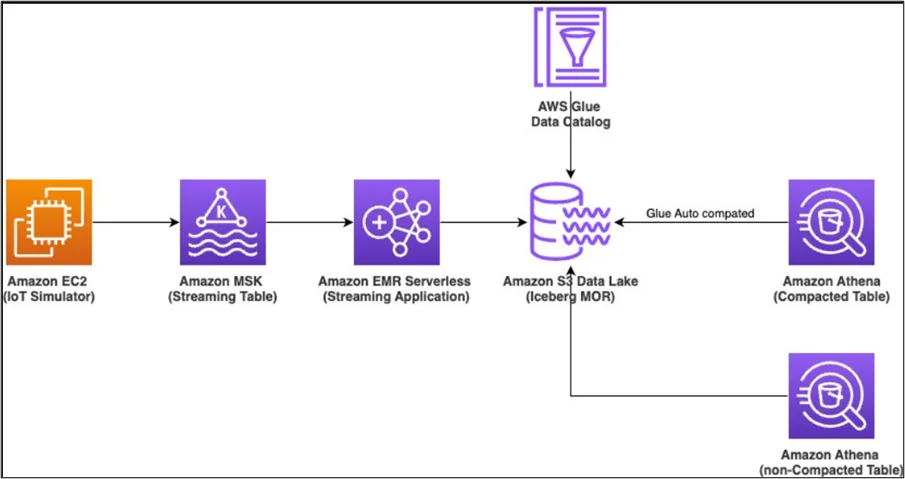
Key Features
Sort Compaction
- Organizes Iceberg table data by sorting it on one or more columns (e.g., date, user ID).
- Ideal for improving range-based filters, where queries focus on continuous values like time.
Z-Order Compaction
- Optimizes data layout by clustering multiple columns together.
- Greatly enhances performance when queries filter on multiple dimensions simultaneously (e.g., location, product ID, timestamp).
Seamless Integration
- Works with Amazon EMR, AWS Glue, and Amazon Athena for Apache Spark.
- No need to redesign schemas or re-architect pipelines, compaction happens in-place.
Transparent Optimization
- Queries automatically benefit from improved data layout without code or query changes.
Use Cases
- Time-Series Analytics
Compacting by time columns accelerates queries for logs, metrics, and clickstream data, which is critical for observability dashboards or operational analytics.
- Customer and Product Segmentation
Z-ordering on region, customer type, and product categories improves targeted analytics and A/B testing.
- IoT and Sensor Data
Sorting or clustering by device ID, region, and event time optimizes data access for millions of IoT devices sending continuous updates.
- Security and Compliance Monitoring
Compacting audit logs and system events by time and source improves incident response and regulatory reporting speed.
- Retail and E-Commerce
Z-ordering on user, product, and timestamp helps with real-time purchase analysis, recommendation models, and personalization engines.
- ML Feature Stores
Compacted Iceberg tables enable faster access to historical features used by machine learning models across batch and real-time pipelines.
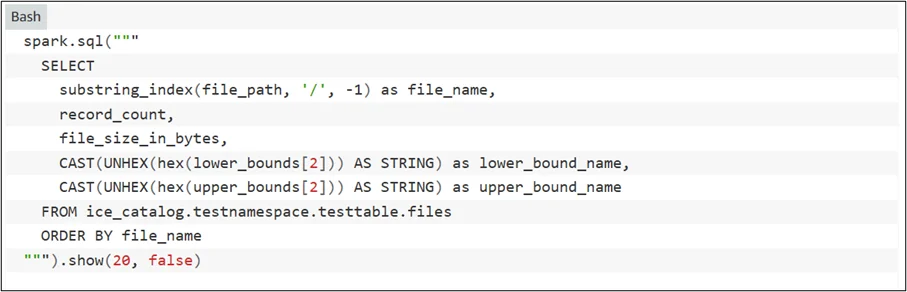
Steps to Implement Sort and Z-Order Compaction
You can begin using these performance-enhancing features with the following high-level steps:
- Assess Query Patterns
- Identify the most frequently queried columns or filters.
- Focus on columns often appearing in WHERE, JOIN, or ORDER BY clauses.
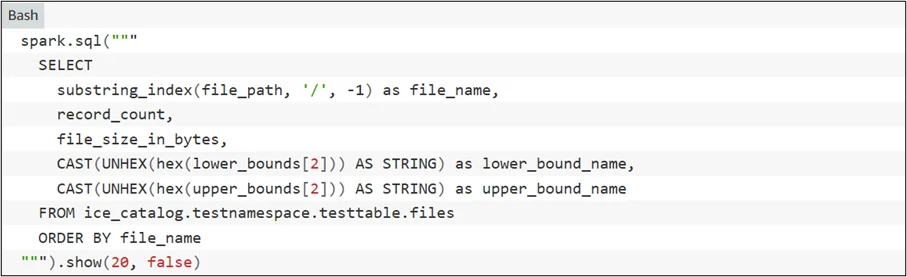
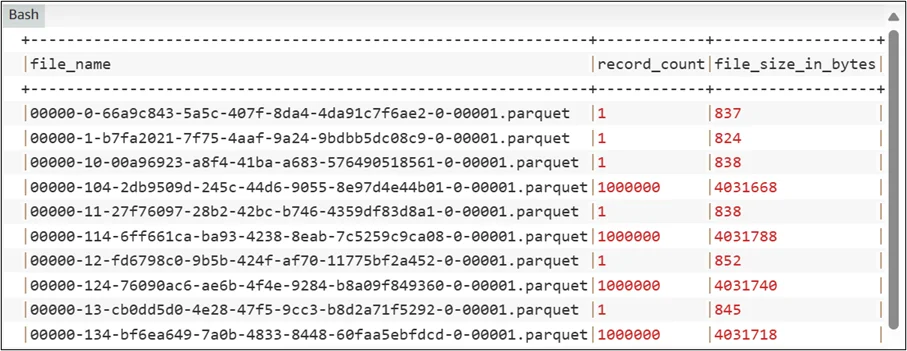
- Choose Compaction Strategy
- Use sort compaction if your queries typically filter on a single column (e.g., date, event ID).
- Use Z-order compaction if your workload involves filtering on multiple columns simultaneously.

- Run Compaction with AWS Services
- Launch compaction jobs using AWS Glue, Amazon EMR, or Amazon Athena Spark.
- These services support sort and Z-order compaction for Iceberg tables stored in Amazon S3.
- Automate and Schedule
- Set up scheduled jobs to periodically run compaction, especially for frequently updated tables.
- Align compaction frequency with your data ingestion rate (daily, weekly, or real-time).
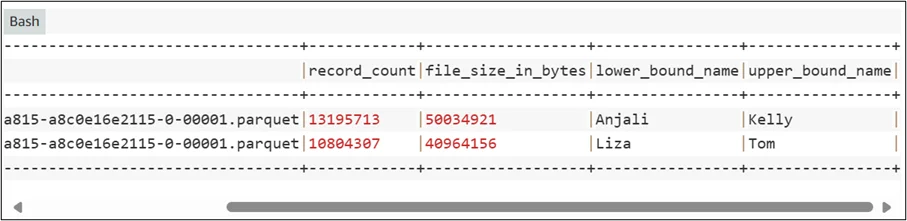
- Monitor Performance Improvements
- Test improvements using query engines like Amazon Athena, Trino, or Amazon EMR Spark.
- Leverage Amazon CloudWatch and built-in metrics from engines to measure reduced scan times and costs.
Best Practices
- Use sort compaction for range scans (timestamps, IDs).
- Use Z-order compaction when filtering on multiple dimensions.
- Avoid frequent compactions on streaming workloads to control costs.
- Monitor file size and count to determine optimal compaction intervals.
- Combine this with Iceberg’s hidden partitioning for the best performance and simplicity.
Performance Gains
- Up to 5x faster queries on sorted time-series data.
- 2–4x lower scan cost when filtering on multiple columns after Z-ordering.
- Reduced data shuffle during joins and aggregations.
- Improved cache efficiency and column pruning.
Conclusion
If you’re building a modern data platform on AWS, now is the perfect time to explore and implement compaction strategies for your Apache Iceberg tables.
Drop a query if you have any questions regarding Amazon S3 and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Do I need to change my queries to benefit from compaction?
ANS: – No. Once compaction is applied, performance improvements are automatic and transparent to users.
2. Is this supported on all AWS services that use Iceberg?
ANS: – Yes. Sort and Z-order compaction can be executed using Amazon EMR, AWS Glue (v4+), and Amazon Athena Spark.
3. Can I automate compaction?
ANS: – Yes. You can schedule compaction jobs using AWS Glue workflows, cron-based triggers, or Amazon EMR orchestration tools.

WRITTEN BY Neetika Gupta
Neetika Gupta works as a Subject Matter Expert at CloudThat with experience deploying multiple data science projects across various cloud platforms. She has successfully delivered end-to-end AI applications tailored to business requirements on cloud frameworks such as AWS, Azure, and GCP. Neetika also specializes in deploying scalable applications using CI/CD pipelines.











Comments