

 Login
Login
 December 11, 2025
December 11, 2025|
Voiced by Amazon Polly |
Why Transformers Matter?

Transformers aren’t merely another buzzword for AI, they’re the underlying architecture of the strongest models today: GPT, BERT, LLaMA, Gemini and many more. Transformers, unveiled in 2017 within the now well-known paper “Attention Is All You Need”, entirely revolutionized natural language processing (NLP), allowing AI to learn, generate and even reason with language at scale. So, what makes them special compared to previous models, such as RNNs or LSTMs? Let’s dive deep in.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
The Limitations Before Transformers
Old sequence models such as RNNs and LSTMs process words one at a time, storing context in a “memory” state.
- This was great for short sentences.
- But for long sequences, context from earlier words tended to disappear.
- Training was also slow and laborious since computations could not be parallelized.
Example: The book that John borrowed from the library was very interesting; earlier models tended to struggle with linking “book” to “interesting.”
The Central Concept of Attention
Attention enables a model to determine which words to attend to while processing a sentence. Example: In “The cat sat on the mat because it was warm,” the word “it” would most likely refer to the “mat.” Previous models usually failed to relate “book” to “interesting.” With focus, the model doesn’t merely depend on word order; it acquires word relationships, regardless of space.
How Transformers Actually Work
Transformers consist of the following components.
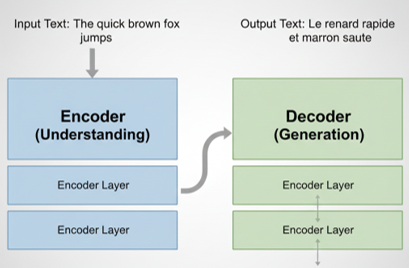
Encoder-Decoder structure in Transformers for understanding and generating language.
- Encoder & Decoder
Encoder reads the input text and creates a contextual representation of each word, and Decoder uses that representation to generate output (translation, summary, next word). Models like BERT only use the encoder (great for understanding). Models like GPT only use the decoder (great for generation).
- Self-Attention
Instead of looking at words one by one, self-attention allows each word to examine every other word in the sentence to understand the context. Each word is represented as a vector (embedding). The model calculates how much “attention” one word should pay to another. These weights determine meaning. So, in “He poured water into the glass because it was empty,” “it” will be strongly linked to “glass”, not “water.”
- Multi-Head Attention
Instead of a single attention mechanism, Transformers employ multiple “heads” simultaneously. Each head learns different relationships such as grammar, position or meaning. The results are then combined for a richer understanding.
- Positional Encoding
As opposed to RNNs, Transformers do not naturally grasp word order. Therefore, they include positional encodings (sine/cosine functions or learned embeddings) so that the model knows the word sequence.
Why Transformers Are a Game Changer
- Parallelization: In contrast to RNNs, they can process all words simultaneously, resulting in an enormous speed-up during training.
- Better Long-Range Understanding: Transformers can deal with lengthy phrases or documents much more effectively. Instead of forgetting earlier information like RNNs often do, they can look at any part of the input at any time, making them great at understanding context.
- Scalability & Performance: As we increase data and model size, transformers continue to perform better. This makes them ideal for building large-scale language models and real-world applications that demand high accuracy.
Looking Ahead
While Transformers dominate today, researchers are exploring:
- More efficient Transformers: smaller, faster models (great for mobile/edge devices).
- Alternatives like Mamba or State Space Models: aiming to reduce cost while retaining performance.
- But for now, the Transformer is the gold standard for AI across domains.
If you’d like to explore Transformers in deeper detail, from architecture to real-world applications, you can check out comprehensive resources provided by companies like CloudThat, such as Introduction to Transformer-Based Natural Language Processing and Generative AI & Prompt Engineering on Azure. It will help you understand how these models work under the hood and why they continue to shape the future of AI.
Engine of Today’s AI
Consider Transformers as the engine within contemporary AI. Just as the internal combustion engine drove automobiles for a century, Transformers are driving the AI revolution of today.
The next time you engage in conversation with GPT, translate words in real-time, or work with an AI writing tool, you’re enjoying the genius of Transformers in action.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Zeeshan A Bepari
Zeeshan A Bepari is a Research Associate at CloudThat, specializing in AI/ML, Generative AI, and Azure Fabric. With over 3 years of experience in the field, he has trained more than 1,500 professionals and students to upskill in cutting-edge technologies. Known for simplifying complex concepts through hands-on teaching, Zeeshan brings deep technical knowledge and practical application into every learning experience. His passion for continuous innovation reflects in his unique approach to learning and development.










Comments