

 Login
Login

 September 23, 2025
September 23, 2025|
Voiced by Amazon Polly |
Overview
Recursive Common Table Expressions (CTEs) in Databricks SQL represent a significant leap in the platform’s data manipulation capabilities. This powerful feature allows you to process hierarchical or graph-like data structures directly within SQL, eliminating the need for complex procedural code or external processing. Before the introduction of recursive CTEs, tasks like traversing an organizational tree, finding all paths in a social network, or calculating multi-level bills of materials required external scripting languages or complex, multi-step queries. With recursive CTEs, Databricks SQL can now efficiently handle these iterative and recursive problems, making it a more versatile and robust tool for various data analytics and engineering tasks. This feature simplifies code and leverages the parallel processing power of the Databricks engine, ensuring high performance even on large datasets.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
At its core, a Common Table Expression (CTE) is a temporary, named result set that you can reference within a SELECT, INSERT, UPDATE, or DELETE statement. It’s defined using the WITH clause and exists only for the duration of the query. A recursive CTE takes this concept further by allowing the CTE to reference itself. This self-referential property enables it to perform iterative computations. The syntax blends a non-recursive “anchor” part and a recursive “member” part. The anchor establishes the starting point of the recursion, while the recursive member defines the logic for how the query progresses from one iteration to the next. The process continues until a condition is met that produces an empty result set, effectively terminating the recursion. This mechanism is foundational to solving problems that involve exploring a series of connected data points, where the output of one step becomes the input for the next.
How Recursive CTEs Work?
A recursive CTE in Databricks SQL operates step-by-step, much like a loop in a procedural language. The process can be broken down into three main stages:
- Anchor Member (Base Case): This initial query defines the first result set. It’s the non-recursive part and serves as the starting point. This query runs only once. For instance, if you’re traversing an employee hierarchy, the anchor member would typically select the top-level manager (the one with no direct report).
- Recursive Member (Iterative Step): This query references the CTE. It’s combined with the anchor member using UNION ALL. In each iteration, this query reads the rows generated by the previous iteration (both from the anchor and the previous recursive steps) and generates new rows. The process continues to loop as long as the recursive member produces new rows. For example, it would find all the direct reports of the manager from the previous step.
- Termination Condition: The recursion stops when the recursive member produces no new rows. This prevents an infinite loop and is critical to a well-defined recursive CTE. You must ensure your logic guarantees a termination point. The Databricks engine handles this termination automatically when the recursive query returns no new rows.
The Databricks query optimizer is highly efficient at processing recursive CTEs. It leverages its distributed architecture to parallelize the computation of each recursive step, ensuring that even large, complex hierarchies are processed quickly.
Key Features of Recursive CTE Support
Databricks’ implementation of recursive CTEs is robust and includes several key features that make it particularly powerful:
- Support for UNION ALL: The UNION ALL operator is essential for combining the anchor and recursive parts, allowing for accumulating results from each iteration. UNION is not supported in recursive CTEs because it would require sorting and de-duplication, which is computationally expensive and generally unnecessary for recursive data generation.
- Breadth-First Search (BFS) Order: By default, Databricks processes recursive CTEs in a breadth-first manner. This means all rows at one hierarchy level are processed before moving to the next level. This is often the most intuitive and efficient approach for many hierarchical problems.
- Automatic Loop Detection and Termination: The Databricks engine is designed to handle potential infinite loops. Suppose a recursive CTE’s logic causes it to produce a row that has already been processed in a previous iteration. In that case, the engine can detect this and terminate the query to prevent resource exhaustion.
- Integration with the Databricks Platform: Recursive CTEs seamlessly integrate with other Databricks features, including Delta Lake tables, external data sources, and the platform’s powerful query optimization engine. This lets you perform complex recursive queries directly on your existing data lakes.
Examples of Solving Iterative Tasks Using Recursive CTEs
Recursive CTEs are incredibly useful for a variety of real-world problems. Let’s look at a couple of common examples.
Example 1: Bill of Materials (BOM)
A classic manufacturing problem is a multi-level BOM, where a product is made of sub-assemblies, which in turn are made of components. You can use a recursive CTE to list all components required to build a final product.
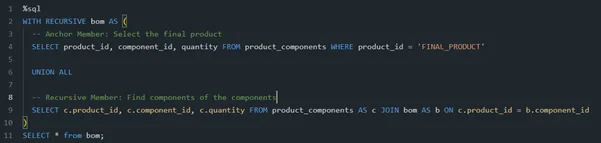
This query unravels the BOM, starting from the final product and recursively finding all its sub-components, regardless of how many levels deep they are.
Conclusion
Introducing recursive CTEs in Databricks SQL is more than just a new feature, it’s a paradigm shift approaching complex data problems. It empowers data professionals to handle hierarchical and graph-based data with native SQL, significantly reducing the need for external tools or complex procedural code. By bringing iterative processing capabilities directly into the SQL engine, Databricks enhances its position as a unified platform for data analytics and engineering. This powerful addition makes Databricks SQL a more expressive and capable language, allowing for cleaner, more efficient, and scalable solutions to some of the most challenging data processing tasks. Whether you’re analyzing supply chains, social networks, or organizational structures, recursive CTEs are indispensable in your Databricks toolkit.
Drop a query if you have any questions regarding Databricks and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Is Databricks SQL now Turing Complete?
ANS: – The introduction of recursive CTEs significantly enhances the computational power of Databricks SQL, allowing it to solve previously only possible problems with procedural languages. While it doesn’t make Databricks SQL “Turing Complete” in the strict theoretical sense, for all practical purposes, this feature allows you to solve a much broader range of problems, including any that involve a bounded number of iterations or hierarchical traversal.
2. Can I use DELETE or UPDATE statements within a recursive CTE?
ANS: – No, you cannot use DELETE or UPDATE within a recursive CTE. Whether recursive or not, a CTE is a read-only construct for a single query. It can only generate a temporary result set for a subsequent SELECT, INSERT, UPDATE, or DELETE statement. The results of the recursive CTE can then be used in a WHERE clause or as a source for an UPDATE or DELETE statement, but the recursive part itself is strictly for data retrieval.

WRITTEN BY Yaswanth Tippa
Yaswanth is a Data Engineer with over 4 years of experience in building scalable data pipelines, managing Azure and Databricks platforms, and leading data governance initiatives. He specializes in designing and optimizing enterprise analytics solutions, drawing on his experience supporting multiple clients across diverse industries. Passionate about knowledge sharing, Yaswanth writes about real-world challenges, architectural best practices, and lessons learned from delivering robust, data-driven products at scale.











Comments