

 Login
Login

 September 8, 2025
September 8, 2025|
Voiced by Amazon Polly |
Introduction
Amazon S3 (Simple Storage Service) is a top cloud-based object storage platform. Amazon S3 offers metadata, or details about stored objects like size, modification date, and user-defined tags, in addition to raw data storage. Especially when combined with analytics engines like Apache Spark and Amazon Athena, this metadata is essential for improving the discoverability, queryability, and manageability of data.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Objective
This blog aims to clarify how integrating Amazon S3 metadata with Apache Spark and Amazon Athena improves data processing and analytics. Technical aspects, advantages, practical uses, and the prospects of metadata-driven analytics will all be discussed.
Types of Metadata
- System Metadata – Auto-generated by Amazon S3 (object key, size, timestamps, ETag, storage class).
- User-Defined Metadata – Custom key-value pairs (e.g., department, data source, sensitivity labels).
Apache Spark with Amazon S3 Metadata
Apache Spark is a distributed processing engine particularly good at big data analytics. Metadata aids Spark in workload optimization when working with data stored in Amazon S3:
- Effective File Finding: Before running queries, Spark depends on file listings. Spark can reduce I/O by pruning unnecessary files using metadata like partitioning keys, which are typically embedded in object names or user-defined metadata.
- Schema Inference: For structured data formats such as Parquet or ORC, Metadata can help Spark infer schema definitions. Partitioned directories (year=2023/month=08/), for instance, are frequently saved as metadata that Spark automatically detects.
- Data Tagging and Filtering: Custom metadata tags allow for selective processing in S3. For example, Spark jobs can be set up to read only objects with the env=production tag.
- Enhancements in Performance: Spark minimizes needless data scans, enhancing query performance and cutting expenses by utilizing Amazon S3 metadata for partition discovery and schema pruning.
Amazon Athena with Amazon S3 Metadata
Amazon Athena is a serverless query service that allows SQL queries to be run directly on Amazon S3 data. For Athena to properly organize and query datasets, metadata is essential:
- Connectivity to the AWS Glue Data Catalog: The AWS Glue Data Catalog serves as the main metadata repository for Amazon Athena. Amazon Athena can efficiently interpret and query data from the catalog’s metadata storage about Amazon S3 datasets, including schemas, partitions, and data formats.
- Pruning Partitions: By allowing Amazon Athena to scan only pertinent partitions rather than the complete dataset, metadata about partitioned data (e.g., date=2025-08-20/) significantly lowers query costs.
- Definitions of Tables and Schemas: Amazon S3 object locations, data types, and column definitions are provided by metadata. Amazon Athena is unable to transform raw data into queryable tables without metadata.
- Governance and Access Based on Tags: AWS Lake Formation can be integrated with Amazon S3 object tags (custom metadata) for more precise access control. For instance, queries may be limited to compliance tags or particular departments.
Principal Advantages
- Cost effectiveness by using fewer data scans.
- Improved performance through schema awareness and partition pruning.
- Improved governance through the use of access controls and tags.
- High scalability for data lakes of the size of petabytes.
Architectural Flow
Here’s the architectural flow to illustrate how Amazon S3, Spark, Amazon Athena, and AWS Glue Data Catalog interact:
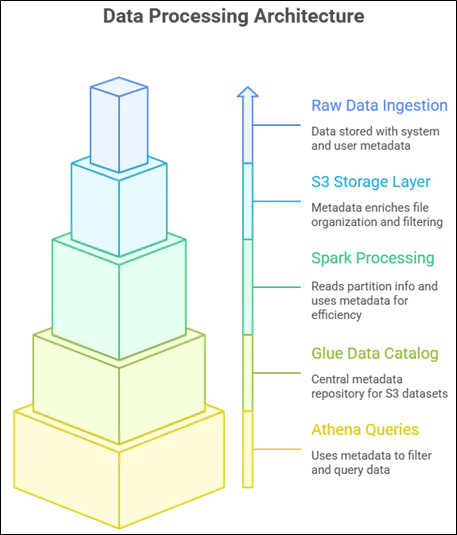
Flow Summary
- Amazon S3 is where data is kept (with metadata).
- Spark uses metadata to read and process data.
- AWS Glue Data Catalog keeps datasets’ structured metadata up to date.
- Amazon Athena makes SQL-like analytics possible by using AWS Glue Catalog to query Amazon S3 data.
Comparison with Alternatives
Presto
- Presto can directly query Amazon S3, just like Amazon Athena, but it needs more cluster management and setup.
- AWS Glue Data Catalog or Hive Metastore are typically used for metadata integration.
Benefit: Adaptable deployment that utilizes various data sources.
Hive
- For metadata, Hive has historically depended on the Hive Metastore.
- AWS Glue and Amazon S3 can be integrated more easily with Spark and Amazon Athena.
Benefit: Compared to Amazon Athena’s serverless SQL engine, Hive queries are typically slower.
Real-World Applications
- Log Analysis: Spark can quickly filter logs by date or service using Amazon S3 metadata.
- Data Lakehouse Architectures: Amazon Athena uses AWS Glue metadata to query partitioned datasets.
- Compliance and Security: Access restrictions are enforced, and sensitive data is categorized using metadata tags.
- ETL Pipelines: Partition discovery and schema evolution are managed with metadata.
What Happens Next?
Metadata will play an increasingly important role in analytics as data volumes increase. Future paths consist of:
- Machine learning-based automated metadata management.
- Interoperability through Cross-Tool Metadata Standards.
- Deeper incorporation of governance tools to ensure compliance.
- Metadata is updated in real time to facilitate streaming analytics.
Conclusion
Amazon S3 metadata is the foundation of effective, safe, and economical data analytics pipelines; it is more than auxiliary data. Metadata unlocks the full potential of contemporary data lakes by enabling faster queries, improved governance, and increased scalability through integration with Apache Spark and Amazon Athena.
Drop a query if you have any questions regarding Amazon S3 metadata and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What kinds of metadata are supported by Amazon S3?
ANS: – Both user-defined metadata (custom key-value pairs) and system metadata (size, last modified date) are supported by Amazon S3.
2. How does Amazon Athena's metadata lower query costs?
ANS: – Amazon Athena scans only pertinent datasets rather than the entire storage using partition pruning.
3. Is it possible for Spark to directly use Amazon S3 metadata?
ANS: – Indeed, Spark uses metadata for filtering, schema inference, and partition discovery.

WRITTEN BY Balaji M
Balaji works as a Research Associate in Data and AIoT at CloudThat, specializing in cloud computing and artificial intelligence–driven solutions. He is committed to utilizing advanced technologies to address complex challenges and drive innovation in the field.











Comments