

 Login
Login

 September 1, 2025
September 1, 2025|
Voiced by Amazon Polly |
Overview
As the world is shifting more and more towards artificial intelligence and data-driven applications, the way we store and search data is also undergoing a big transformation.
Now, this raises a basic question: what is a vector database, and how is it different from the traditional database systems like MySQL or Oracle that we have used for decades?
In this blog, let us break down both types of databases, see how they differ, and understand where each one fits, especially in today’s AI-focused landscape.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Traditional Database
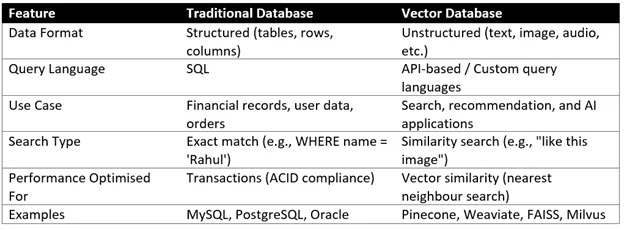
Most software engineers are already familiar with a traditional database, also known as a relational database. It stores data in tables, made up of rows and columns. You define a schema, like a table for users, with fields such as name, email, phone number, and you store the data accordingly.
Examples of popular traditional databases include:
- MySQL
- PostgreSQL
- Oracle Database
- Microsoft SQL Server
These databases work well for structured data, where the data format is known in advance. You can write SQL queries to insert, update, delete, or fetch information. For example, you can ask:
“Give me all users who signed up in the last 7 days”, and you’ll get a list.
This works beautifully for most enterprise applications, like:
- Banking software
- E-commerce platforms
- Inventory management
- HR systems
However, the relational model begins to fall short when you step into applications that deal with unstructured data like text, images, videos, voice, or sensor data.
Vector Database
Now, let us come to vector databases designed to handle a different kind of problem. These databases store data in vectors, that is, arrays of numbers representing things like meaning, context, or features of unstructured data.
But how does that work?
Suppose you have a sentence:
“How to cook biryani?”
When you feed this to an AI model like a transformer, it doesn’t treat it as just words. Instead, it converts the entire sentence into a vector, maybe 384 or 768 numbers long, that represents the meaning of the sentence in a mathematical way.
Now, if someone searches for “biryani recipe”, a good vector database can recognise that both queries are similar in meaning and show relevant results, even though the exact words do not match.
Popular vector databases include:
- FAISS (by Facebook)
- Pinecone
- Weaviate
- Milvus
- Qdrant
These systems are used where semantic search, recommendation systems, image recognition, or large language models (LLMs) are involved.
Why Vector Databases Are Gaining Popularity
Earlier, when people searched for something on an app or website, they typed exact keywords. But nowadays, we talk to systems in natural language. For example:
- “Show me T-shirts under ₹500 with good reviews”
- “Find documents similar to this one”
- “Which movies are like Dangal?”
To answer such queries, systems need to understand the intent behind your words, not just match them. This is only possible when your data is represented in vectors, so a traditional database is insufficient.
Also, apps now deal with millions of images, voice clips, and long paragraphs of content. Vector databases are becoming essential for comparing and searching through them efficiently.
Key Differences Between Vector and Traditional Databases
Conclusion
To sum up, traditional databases and vector databases are not competitors, they are complementary.
Drop a query if you have any questions regarding Vector databases and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Can a vector database completely replace a traditional database?
ANS: – No, a vector database is not meant to replace traditional databases. They serve different purposes. A traditional database is best for storing and managing structured data like customer records, transactions, and reports. A vector database is designed for storing and searching high-dimensional vector representations of unstructured data such as text, images, and audio. In most real-world applications, both are used together, traditional databases for transactional operations and vector databases for AI-driven search or recommendations.
2. Is it necessary to learn machine learning to use a vector database?
ANS: – Not necessarily. While vector databases are built around AI concepts like embeddings and similarity search, many offer user-friendly APIs and integrations with popular ML models. You can use pre-trained models to generate vectors from text or images and store them in a vector database without deep machine learning knowledge. However, understanding basic ML concepts like embeddings and similarity scoring will help you better use these databases.

WRITTEN BY Hridya Hari
Hridya Hari is a Subject Matter Expert in Data and AIoT at CloudThat. She is a passionate data science enthusiast with expertise in Python, SQL, AWS, and exploratory data analysis.











Comments