

 Login
Login

 December 4, 2025
December 4, 2025|
Voiced by Amazon Polly |
Introduction
In many modern systems, such as search engines, recommendation platforms, image retrieval, and embedding-based NLP pipelines, the core problem is similarity search: given a query vector (representing a document, image, or user profile), we want to retrieve the most similar items from a large repository of vectors.
Two foundational methods that this series starts with are:
- The brute force approach of k-nearest neighbours (kNN).
- A more scalable method using the inverted file index (IVF). The article walks through both, explains trade-offs, and how large-scale systems make different choices.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
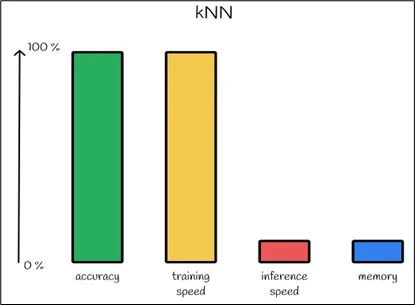
kNN (Brute‐Force Nearest Neighbour)
- Suppose you have a dataset of N vectors, each of dimension D (for example, 1 million vectors embedding images or documents).
- Given a query vector q, you compute the similarity (or distance) between q and each vector in the dataset (for example, Euclidean distance or inner product/cosine similarity).
- Then you pick the top k items with the smallest distances (or highest similarity) to return. This is the classical kNN search.
- Since you compare q to all N vectors, the time complexity is on the order of O(N × D) for one query.
Advantages
- Exactness: Because you inspect all vectors in the dataset, you guarantee you find the true nearest neighbours (no approximation).
- Simplicity: Implementation is straightforward: compute distances and sort. No complicated index training or clustering is needed.
When to use it
- For small datasets or prototypes (e.g., N up to a few hundred thousand, low dimension).
- When accuracy is paramount, and you cannot tolerate missing the true nearest neighbours (for example, fingerprint matching or forensic use‐cases).
- When the latency requirements and query volume are modest.
Inverted File Index (IVF)
- The inverted file index, in the context of vector search, is an indexing/truncation method where the dataset is partitioned into cells (clusters). At query time, you only search within a subset of those cells, instead of the full dataset.
- The “inverted list” concept comes from information retrieval (mapping term → list of documents), but here the analogy is: centroid (cluster region) → list of vectors belonging to that region.
- Implementation at a high level (as per the article):
- Training: Use a clustering algorithm (e.g., k-means) to choose nlist centroids in the vector space. Assign each dataset vector to its nearest centroid → thus we partition the data into nlist “cells” or “regions”.
- Indexing: For each region/cell, you maintain the list of vectors assigned to that cell (a posting list).
- Querying: Given a query vector q:
- Compute its distances to all centroids (O(nlist × D)).
- Identify the closest centroid(s) to q (often top m, where m = nprobe).
- Retrieve the vectors in those selected cells only (much smaller subset than all N).
- Compute exact distances between q and those candidate vectors; pick the top k from that subset.
- By doing this, you reduce the number of vectors you compare in step 4, thus reducing latency.
Advantages
- Speed/scalability: Because you only search within a fraction of the entire dataset, latency drops significantly compared to brute force. For example: N=10 M, nlist=100, each cell ~100k vectors, search cost becomes roughly ~100 + 100k instead of ~10M.
- Reasonable accuracy: If you probe enough cells (increase nprobe), you can approach the results of brute force, at a cost of search time.
- Memory-friendly: The index structure (centroids + inverted lists) is manageable and often integrated into systems like FAISS.
- Widely used in production: Many vector search systems use IVF (or variants) as a foundational method.
Practical considerations and best practices
- A common implementation in FAISS uses IndexIVFFlat (where no quantization/compression is applied) or IndexIVFPQ (with product quantization) for further compression.
- Choose nlist relatively high when you want faster searches (more partitions → fewer vectors per partition), but you must also set nprobe (how many partitions you check) appropriately so you don’t sacrifice too much recall.
- Monitor the “recall vs latency” trade‐off. More nprobe → higher recall but longer query time.
- If your query volume is high, or real‐time constraints are tight, you may accept some approximation for speed.
- Embedding dimension D matters: High-dimensional vectors often require dimensionality reduction or additional compression.
- Monitor cluster size distribution: Avoid having too many vectors in a single cell.
- Consider hierarchical indexing (IVF + further quantization) for very large N.
- For scenarios where accuracy is critical, maybe fallback to brute force or hybrid methods.
Conclusion
Similarity search is a foundational capability in many data/ML systems: from retrieving similar documents and images to powering recommendation engines and search features. The simple brute‐force kNN method is conceptually straightforward and produces exact results, but it doesn’t scale well for large-scale, high‐dimensional vector sets. The inverted file index (IVF) offers a practical compromise: by partitioning the dataset and limiting the search to a subset of vectors via clustering, you dramatically improve query latency and scalability, at the cost of some approximation.
Drop a query if you have any questions regarding kNN and we will get back to you quickly.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. What exactly does “nearest neighbour” mean in this context?
ANS: – Given a query vector q, the nearest neighbour(s) are the vector(s) in your dataset whose embeddings are closest (by chosen metric: e.g., Euclidean distance, inner product, cosine similarity) to q.
2. Why can’t we always just use brute‐force kNN?
ANS: – Because when the dataset size (N) is very large (millions or more) and the embedding dimension (D) is high, the computational cost O(N × D) for each query becomes too large for real-time or high‐throughput systems.

WRITTEN BY Venkata Kiran
Kiran works as an AI & Data Engineer with 4+ years of experience designing and deploying end-to-end AI/ML solutions across domains including healthcare, legal, and digital services. He is proficient in Generative AI, RAG frameworks, and LLM fine-tuning (GPT, LLaMA, Mistral, Claude, Titan) to drive automation and insights. Kiran is skilled in AWS ecosystem (Amazon SageMaker, Amazon Bedrock, AWS Glue) with expertise in MLOps, feature engineering, and real-time model deployment.











Comments