

 Login
Login
 April 29, 2014
April 29, 2014|
Voiced by Amazon Polly |
If you are considering MongoDB or any other NoSQL databases, its a must that you consider DynamoDB. In the MongoDB vs DynamoDB matchup, DynamoDB has a lot of brilliant features that help ease the pain of running NoSQL clusters. Below I give five reasons to choose DynamoDB over MongoDB.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Reason 1: People don’t like being woken up in the middle of the night
One sure-shot way to motivate someone to rethink their priorities in life, and reconsider their choice in becoming an IT professional, is to hand them pager-duty for a MongoDB cluster. Maintaining a MongoDB cluster requires keeping the servers up and running, keeping the MongoDB processes up and running, and performance monitoring for the cluster. Check this image for example (time there are in UTC).
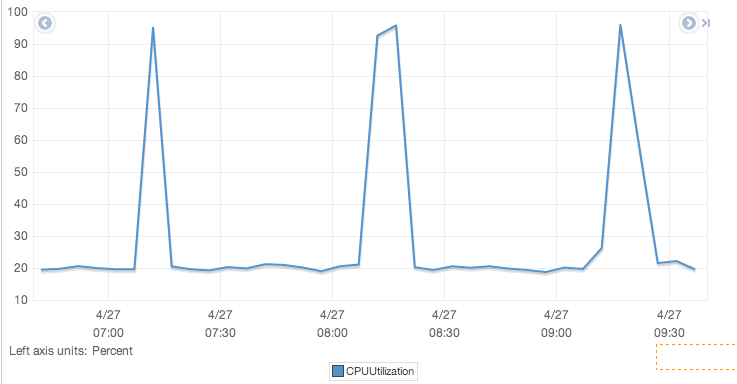
In the middle of the night, a client’s MongoDB Cluster generated few automated CloudWatch alarms. At 4 AM the conversation between a systems engineer and me is like following:
Engineer: Hey, got woken up by the pager, seems like CPU utilization is spiking, but requests are running fine. I looked around but found nothing. Can I just resolve this issue and look at it tomorrow?
Me: You woke me up to just ask this?
Why will you want your staff (or yourself) to have to go through this kind of conversation anytime during the day, let alone 4 in the morning? With DynamoDB, AWS engineers take care of such issues, not you. You still need monitoring for performance issues, but the things that need to be monitored are really few in numbers compared to MongoDB.
Reason 2: People don’t like to spend money on hardware (if they don’t have to)
I was in a meeting with a customer trying to understand their requirements to design the MongoDB cluster for them. They had about 1TB of data, and at peak they did about 1000 reads/second and 50 writes/second. They were growing like crazy and expecting 3 times traffic growth in next one year. They also wanted to avoid any downtime if and when they had to scale up, so preferred we pre-provisioned the capacity and started with capacity they would need at the end of the year when they had grown 3x. We designed a MongoDB cluster with three shards, and each shard having three replica-set thus 9 machines. Add 3 config servers to it, and you are looking at a 12 node cluster. The cost was about $3000 per month (this was before the recent price reductions).
If the DynamoDB was used, the starting capacity would have cost around $500, which is a huge reduction in cost. Also, unlike MongoDB, one does not need to preprovision a lot of capacity, as DynamoDB allows rapid scaling up (and down), so unlike MongoDB, we would not have to preprovision a lot of extra capacity (and thus cost).
Also in case you get official MongoDB support, it costs extra and costs are relatively high, based on the number of hosts. With DynamoDB the AWS support that works for all other AWS services works for DynamoDB without having to buy additional support, which in comparison usually ends up being much lower.
Reason 3: Updating MongoDB version on a production system is not a good way to spend a Sunday
MongoDB releases version 2.6, and calls it their “best version yet”. You get calls from all your clients asking for when you can upgrade their existing MongoDB clusters to this latest and greatest version. And as a seasoned professional you don’t want to make any changes to production during business hours, you know things can go wrong. Thus, you sacrifice your precious weekends to the altar of MongoDB upgrades. And as always, no upgrade is really as simple as the documentation states. Compare that to the two big upgrades DynamoDB did in last 12 months. It was all seamless, and I was just notified that new features and better performance is available without me doing any real work. Which option will you choose?
Reason 4: Have you checked out the DynamoDB features lately?
DynamoDB, in the classical AWS style, was released with just bare-bone features. It was not that much better than a glorified hosted Memcache cluster. You could not even have arbitrary indexing, the only index was the primary key. But since then DynamoDB has evolved rapidly with new feature like Local Secondary Indexes and recently Global Secondary Indexes that allow arbitrary keys to be indexed. Access controls to the tables and rows can now be controlled via IAM accounts which opens up so many usecases that are not possible in MongoDB.
The latest set of features improve querying by allowing to set filters. Thus, if you looked at DynamoDB a year ago, and found it severely limiting in features, its time to look again. The reason why you decided to not use DynamoDB then, might have been fixed now.
Reason 5: Finally QA can test the real deal.
You have heard this before from QA personals, “But it worked in the Test cluster”. This is also true for MongoDB, where for big production clusters with many shards and replicasets, most likely the QA cluster is just one machine. Many issues and bugs are only manifested when you test on the real deal. So either you need to fork out more money and get a test cluster that looks like production cluster in size and number of servers, or be ready for such bugs to slip though.
DynamoDB allows you to create the same cluster as prod but with lower throughput. Thus even with lesser costs, you can test the real deal. The phrase “But it worked in test cluster”, can be safely rejected.
If you are evaluating NoSQL databases, I suggest you give DynamoDB a sincere try. Your team will thank you when they can enjoy their sleep and weekends. If you have further questions about DynamoDB vs MongoDB, feel free to send me a comment below or at my email bhavesh at cloudthat.in.
If you liked the article please share it. Thanks!!
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Bhavesh Goswami
Bhavesh Goswami is the Founder & CEO of CloudThat Technologies. He is a leading expert in the Cloud Computing space with over a decade of experience. He was in the initial development team of Amazon Simple Storage Service (S3) at Amazon Web Services (AWS) in Seattle. and has been working in the Cloud Computing and Big Data fields for over 12 years now. He is a public speaker and has been the Keynote Speaker at the ‘International Conference on Computer Communication and Informatics’. He also has authored numerous research papers and patents in various fields.










Samantha
Jul 9, 2019
What a complete load of nonsense. Mongodb is a full featured database supporting real ad hock queries and real cursors and no fooling around with “query” vs “scan” or building your own cursor or ultra bizarre price model that makes most people either over provision or just go with on demand costs. Dynamodb is basically a key value store with delusions of grandeur. It has so many irregularities and gotchas that it is not fun at all trying to write reasonably reusable code for it.
Any database looks bad if you cherry pick being an idiot possibilities.
Bill
Apr 20, 2017
Aside from other valid criticisms above, the fact that DynamoDB is proprietary, costs money to use, and is hosted only by Amazon is a deal breaker for many. MongoDB is hosted as a maintained service in many places, and in fact you can instantiate it as an official Docker container if you want great ease of installation.
Adding to the query complaints, DynamoDB apparently requires a unique primary key for anything that you want to be indexed, and obviously not all NoSQL documents will have that.
Praful k
Apr 7, 2018
Agree with your comparison. However,for spring boot Java developers I see there is community version for mongodb.Can this be taken to prod.please suggest.
Peter
Apr 18, 2017
In short simple queries on DynamoDB are OK. Simple reliable.
BUT and it’s a really big BUT, quering records, sorting, getting filtered results, and moreover amount of all results matching the query is really bad.
Don’t go this way!
HateDynamodbToo
Mar 23, 2017
If I get you right, you think the dynamoDB is better than MongoDB mainly because Amazon takes care of it for you. How about the property of these two DB?
HateDynamodb
Mar 16, 2017
Querying records from Dynamodb is really bad. For developers it is nightmare. And one wrong thing can cost you like any thing. Scan works but too costly. Query is shit. So way to query for different columns. Simple example how can you get Upcoming events from Events table. in and other db we do EventDate > currentdate. Dynamodb sucks here..
Juan
Nov 24, 2016
You forgot the most important thing about databases. I want to query my data… In dynamo db you can only query by primary key and partition key…. What? Yeah, they forgot about the queries… You have implement yourself the filtering mechanism!
Mita
Nov 3, 2015
Useful points from the server admin point of view.But when your development server is localhost , then working with DynamoDB is not possible locally , only AWS is the only option in that case.
Glum
Apr 18, 2016
Not true, since Sept 2013, AWS offers DynamoDB Local exactly for this purpose – developing on local machine. https://aws.amazon.com/blogs/aws/dynamodb-local-for-desktop-development/
Vijay
Nov 15, 2014
Nice write up. Useful points