

 Login
Login

 May 19, 2026
May 19, 2026|
Voiced by Amazon Polly |
Introduction
In modern information retrieval systems, especially those involving search, recommendation engines, or hybrid retrieval pipelines, combining results from multiple ranking models is a common challenge. Different models often capture different signals: keyword-based approaches emphasize lexical matching, while embedding-based models focus on semantic similarity. The question then becomes: how do we effectively merge these diverse rankings into a single, high-quality result list?
Reciprocal Rank Fusion (RRF) is a simple yet powerful algorithm designed to address this exact problem. It is widely used in hybrid search systems, including those combining traditional IR systems like BM25 with vector-based retrieval. Despite its simplicity, RRF consistently delivers strong performance and robustness without requiring complex tuning or training.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Reciprocal Rank Fusion
Reciprocal Rank Fusion is a rank aggregation technique that combines multiple ranked lists into a single unified ranking. Instead of relying on raw scores, which may not be directly comparable across systems, RRF uses the positions (ranks) of items in each list to compute a final score.
The core idea is straightforward: documents that appear higher in any ranking list are given greater importance, and documents that appear in multiple lists receive cumulative benefits.
The RRF scoring formula is:
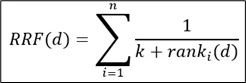
Where:
- is the document
- is the number of ranking lists
- is the position of document in the list
- is a constant (typically set to 60)
Why Use RRF?
Traditional score-based fusion methods often struggle because different ranking systems produce scores on different scales. Normalizing these scores can introduce complexity and instability. RRF avoids this problem entirely by focusing only on rank positions.
Key advantages include:
- Model-agnostic: Works with any ranking system regardless of scoring method
- Robustness: Less sensitive to outliers or noisy scores
- Simplicity: No training or normalization required
- Effectiveness: Performs well in real-world hybrid retrieval scenarios
How RRF Works: Step-by-Step
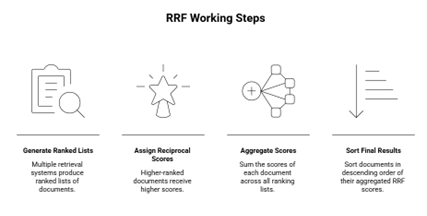
Let’s break down the process:
- Generate Ranked Lists
Assume you have multiple retrieval systems:
- BM25 (keyword-based)
- Dense vector search (semantic)
- Possibly a re-ranking model
Each system produces a ranked list of documents.
- Assign Reciprocal Scores
For each document in each list, compute:
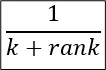
Higher-ranked documents (lower rank values) get higher scores.
- Aggregate Scores
For each document, sum the scores across all ranking lists.
- Sort Final Results
Documents are sorted in descending order of their aggregated RRF scores.
Example
Consider two ranking lists:
List A (BM25):
- Doc1
- Doc2
- Doc3
List B (Vector Search):
- Doc3
- Doc2
- Doc4
Using :
- Doc1:
- Doc2:
- Doc3:
- Doc4:
Even though Doc3 is ranked differently across lists, its combined score reflects both contributions, often pushing it higher in the final ranking.
Choosing the Parameter k
The constant controls how much weight is given to top-ranked documents.
- Smaller : Strong emphasis on top-ranked results
- Larger : More balanced contribution across ranks
In practice, is widely used and works well across many datasets. It dampens the impact of rank differences while still prioritizing top results.
RRF in Hybrid Search Systems
RRF has become a standard approach in hybrid search architectures, particularly in systems that combine:
- Lexical search (e.g., BM25 in Elasticsearch)
- Semantic search (e.g., vector embeddings using transformer models)
Instead of choosing one approach over the other, RRF allows both to contribute meaningfully.
Typical Pipeline:
- Retrieve top-N documents using BM25
- Retrieve top-N documents using vector search
- Apply RRF to merge results
- Optionally apply a re-ranker (e.g., cross-encoder)
This setup improves both recall (finding relevant documents) and precision (ranking them correctly).
Comparison with Other Fusion Techniques

RRF stands out by avoiding normalization and training while still achieving competitive performance.
Limitations of RRF
While RRF is effective, it is not perfect:
- Ignores actual scores: Only considers rank positions
- No query-specific adaptation: Same behavior across all queries
- Limited fine-tuning: Only one parameter ()
In scenarios where fine-grained optimization is required, learning-to-rank models may outperform RRF, but at the cost of complexity.
Best Practices
To get the most out of RRF:
- Use sufficiently large top-N lists (e.g., top 100–1000)
- Ensure diversity in retrieval methods (lexical + semantic)
- Avoid overly small unless you want aggressive ranking bias
- Consider combining RRF with a downstream re-ranking model
Real-World Use Cases
RRF is widely used in:
- Search engines (hybrid search)
- Question answering systems
- E-commerce ranking systems
- Enterprise knowledge retrieval
- RAG (Retrieval-Augmented Generation) pipelines
Its simplicity makes it especially appealing in production systems where reliability and interpretability matter.
Conclusion
Looking ahead, RRF is likely to remain a foundational component in hybrid retrieval pipelines. However, future advancements may involve combining RRF with adaptive weighting mechanisms, query-aware fusion strategies, or neural aggregation models. As retrieval systems become more complex, RRF may serve as a reliable baseline or fallback even in highly sophisticated architectures.
Drop a query if you have any questions regarding Reciprocal Rank Fusion and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What problem does Reciprocal Rank Fusion solve?
ANS: – It combines multiple ranked lists into a single ranking without needing score normalization or model-specific adjustments.
2. Why is RRF preferred over score-based fusion?
ANS: – Because it avoids inconsistencies in score scales and is more robust across different retrieval systems.
3. What is the role of the constant kin RRF?
ANS: – It controls how much importance is given to top-ranked results versus lower-ranked ones.

WRITTEN BY Daniya Muzammil
Daniya works as a Research Associate at CloudThat, specializing in backend development and cloud-native architectures. She designs scalable solutions leveraging AWS services with expertise in Amazon CloudWatch for monitoring and AWS CloudFormation for automation. Skilled in Python, React, HTML, and CSS, Daniya also experiments with IoT and Raspberry Pi projects, integrating edge devices with modern cloud systems.










Comments