

 Login
Login

 May 7, 2026
May 7, 2026|
Voiced by Amazon Polly |
Overview
With Amazon Bedrock’s Reinforcement Fine-Tuning (RFT), users can tailor the behavior of the AI using reward functions rather than large amounts of labeled data. The AWS Lambda acts as the execution environment that runs your reward logic on the AI output to evaluate its performance. This system offers up to ~66% increases in average accuracy compared to the base AI models by showing them what good looks like in your application. There are two types of reward functions available: RLVR and RLAIF.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
The conventional approach to supervised fine-tuning requires thousands of labeled input-output pairs, which is costly and inefficient when responding to rapidly changing business needs. Reinforcement Fine-Tuning takes an opposite approach; instead of providing “right answers” to the model, you specify reward functions that indicate how accurate, safe, polite, or compliant the generated answer is. During the fine-tuning process, Amazon Bedrock generates several potential answers to your input prompts, you grade them using your Lambda function, and the model learns to generate high-reward answers.
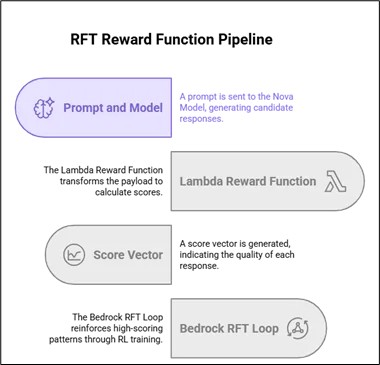
How AWS Lambda reward functions work in RFT?
The training feedback loop
- Prompt Generation: Amazon Bedrock generates 3-5 possible answers for your prompts using the Amazon Nova base model.
- AWS Lambda Function Call: Amazon Bedrock calls your AWS Lambda function after processing your inputs, adding response IDs, and the assistant turn.
- Scoring: The output includes a score ranging from 0.0 to 1.0 for each generated answer, along with additional metrics.
- Reinforcement Learning: Amazon Bedrock updates the RL loop based on these scores, thus favoring answers that are rewarded more.
AWS Lambda receives payloads in this format: {“id”: “unique_id”, “messages”: […], “reference_answer”: “…”} and must return: {“id”: “unique_id”, “aggregate_reward_score”: 0.85, “metrics_list”: [{“name”: “accuracy”, “value”: 0.9}]}.
AWS Lambda reward function workflow
Key insight: AWS Lambda doesn’t need to know the “right answer” it just needs to score responses relative to your quality criteria consistently. The RL algorithm handles convergence.
Building effective AWS Lambda reward functions
- Rule-based rewards (RLVR) – Objective tasks
Perfect for verifiable outcomes. Example for code generation:
Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
def evaluate_code_response(response: str, expected_output: str) -> float: score = 0.0 # Check syntax validity if is_valid_syntax(response): score += 0.3 # Check functional correctness if execute_safely(response) == expected_output: score += 0.5 # Check efficiency/readability if meets_style_guidelines(response): score += 0.2 return min(1.0, score) |
Use cases: math problems, API responses, structured data extraction, compliance checks.
2. LLM-as-judge rewards (RLAIF) – Subjective evaluation
Use another AWS Bedrock model (Claude 3.5 Sonnet, Amazon Nova) as an evaluator:
Python:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def llm_judge_response(candidate: str, reference: str) -> float: judge_prompt = f""" Rate how similar these responses are (0.0-1.0): Reference: {reference} Candidate: {candidate} Output ONLY the number. """ response = bedrock_runtime.converse( modelId="anthropic.claude-3-5-sonnet-20240620-v1:0", messages=[{"role": "user", "content": [{"text": judge_prompt}]}], inferenceConfig={"temperature": 0.0, "maxTokens": 10} ) return float(response['output']['message']['content'][0]['text'].strip()) |
Use cases: tone/brand alignment, helpfulness, instruction following, and creative writing quality.
Best practices for production reward functions
Game-resistance criterion definitions
- Specificity: “Be helpful” -> “Answer includes 3 actionable steps with estimated time.”
- Multi-dimensional: Accuracy (70%) + Format (20%) + Safety (10%)
- Troubleshooting: Verify your scorer against malicious test cases
AWS Lambda functions patterns that scale
- Batch scoring: Process many samples at once (usually an array as an event)
- Error recovery: In case of failure, always return 0.0 (no crash of the training job)
- Score clamping: Only return scores in the range of [0.0, 1.0]
- Timeout protection: Do not exceed 15 minutes of execution (the AWS Lambda time limit)
- Evaluation caching: Avoid duplicating work by memorization (during the development phase)
Scoring system testing process
- Unit tests: Mock Amazon Bedrock call, validate output score distributions
- Manual validation: Score 50 hand-picked samples, correlate with human assessment
- Small-scale real-time feedback: Execute 100-sample training job
- Live monitoring: Analyze scores, monitor training
Integration with Amazon Bedrock RFT recipes
After configuring your AWS Lambda:
- Deploy AWS Lambda → Retrieve ARN
- Construct RFT recipe → Include reward_lambda_arn field
- Submit training data → Store prompts and optional reference responses in Amazon S3
- Initiate job → Amazon Bedrock automates the RFT process using your reward function
- Evaluate → Assess base vs. fine-tuned models in Amazon Bedrock playground
Amazon Bedrock takes care of scaling, orchestration, and checkpointing. Your AWS Lambda evaluates the responses.
Common mistakes and remedies
- AWS Lambda complexity: Keep code under 1K lines, test locally before hand
- Problematic score distribution: Ensure scores fall between 20-80% (not all 1.0s)
- Model bias evaluation: Evaluate models at temperature=0.0, recruit additional judges if required
- “Cold start” problems: Allocate provisioned concurrency for large-scale RFT tasks.
- Cost overruns: Track AWS Lambda invocations during RFT processes.
Conclusion
Reward functions in AWS Lambda enable Reinforcement Fine-Tuning by enabling the specification of “what good is.”
Given that Amazon Bedrock manages the RFT infrastructure behind the scenes, all users need to specify the evaluation criteria. As a result, customers will be able to get Amazon Nova models adjusted precisely to their quality needs.
Drop a query if you have any questions regarding AWS Lambda and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. What is the distinction between RLVR and RLAIF rewards?
ANS: – RLVR uses determinism for objective attributes such as coding validation. RLAIF relies on an independent model to score subjective attributes such as tone or helpfulness.
2. How do I prevent training failures caused by AWS Lambda failures?
ANS: – Ensure the returned JSON is always valid, with scores between [0.0,1.0]. Wrap the entire script with try-catch and return 0.0 when an exception occurs.
3. Is there a way to test my reward function without doing full RFT?
ANS: – Yes, conduct small 100-sample RFT jobs initially. Test your AWS Lambda function with mock Amazon Bedrock data locally.

WRITTEN BY Nekkanti Bindu
Nekkanti Bindu works as a Research Associate at CloudThat, where she channels her passion for cloud computing into meaningful work every day. Fascinated by the endless possibilities of the cloud, Bindu has established herself as an AWS consultant, helping organizations harness the full potential of AWS technologies. A firm believer in continuous learning, she stays at the forefront of industry trends and evolving cloud innovations. With a strong commitment to making a lasting impact, Bindu is driven to empower businesses to thrive in a cloud-first world.











Comments