

 Login
Login
 March 17, 2026
March 17, 2026|
Voiced by Amazon Polly |
Overview
As organizations deploy AI agents for critical business operations, ensuring consistent quality becomes paramount. Amazon Bedrock AgentCore Evaluations addresses this challenge by providing a fully managed service that automates assessment tools to measure agent performance. Whether building customer service bots or complex multi-agent systems, Amazon Bedrock AgentCore Evaluations offers the monitoring capabilities essential for production-ready deployments.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
The rapid adoption of AI agents has created an urgent need for robust quality assurance mechanisms. While AI agents offer tremendous potential for automating complex tasks, their autonomous nature presents unique challenges. How do you ensure an agent consistently provides accurate information? How do you verify it selects the right tools for each task?
Amazon Bedrock AgentCore Evaluations answers these questions by providing a comprehensive evaluation framework that seamlessly integrates with popular agent frameworks, including Strands Agents and LangGraph. The service leverages OpenTelemetry and OpenInference instrumentation libraries to capture agent interactions, converting traces into a unified format scored using sophisticated LLM-as-a-Judge techniques.
Key Features and Capabilities
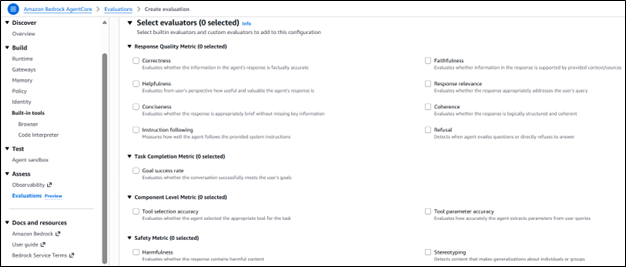
Built-in Evaluators
Amazon Bedrock AgentCore Evaluations provides 13 built-in evaluators that cover essential quality metrics. Session-level evaluators examine entire conversations to determine outcomes, such as goal completion. Trace-level evaluators assess individual responses for helpfulness, correctness, and faithfulness. Tool-call evaluators focus on whether agents choose appropriate tools and correctly interpret user queries.
The Helpfulness evaluator measures how useful each response is to the user. The Correctness evaluator verifies factual accuracy. Additional evaluators detect harmful content and stereotyping, ensuring agents maintain appropriate communication standards.
Custom Evaluators
While built-in evaluators cover common dimensions, every organization has unique requirements. Amazon Bedrock AgentCore Evaluations enables the creation of custom evaluators tailored to specific business needs. You define the judge model, configure inference parameters, and craft tailored prompts with judging instructions.
Custom evaluators support flexible rating scales, either numeric values or custom text labels. You can configure evaluations to run on single traces, full sessions, or individual tool calls, providing granular control over assessment scope.
Online Evaluation for Continuous Monitoring
Online evaluation enables continuous monitoring of live agent traffic. Rather than relying on periodic manual assessments, you configure automatic evaluation of interactions as they occur in production.
Configurations allow specifying sampling rates and determining the percentage of interactions to evaluate. Starting with a one to five percent sampling provides meaningful insights without excessive resource consumption. The service supports up to 1,000 evaluation configurations per AWS Region, with up to 100 active simultaneously.
On-Demand Evaluation
Before deploying agents to production, thorough testing is essential. On-demand evaluation allows running evaluations against specific sessions, checking performance against baseline expectations. This helps prevent faulty versions from reaching users by identifying quality issues during development.
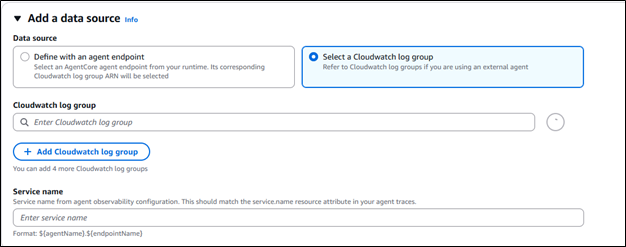
Amazon CloudWatch Integration
All evaluation results are visualized in Amazon CloudWatch alongside Amazon Bedrock AgentCore Observability insights, providing unified monitoring in a single location. You can set up alarms on evaluation scores to proactively monitor quality and respond when metrics fall outside acceptable thresholds.
For example, if a customer service agent’s satisfaction scores decline by more than 10% over 8 hours, the system triggers immediate alerts, enabling rapid response to quality degradation.
Framework Agnostic Design
Amazon Bedrock AgentCore Evaluations works with any open-source framework, including CrewAI, LangGraph, LlamaIndex, and Strands Agents. It supports any foundation model, providing flexibility regardless of existing technology choices.
How It Works?
The evaluation process begins with trace collection. As your agent handles interactions, traces are captured using OpenTelemetry or OpenInference instrumentation, which includes detailed information about agent reasoning, tool calls, and responses.
Amazon Bedrock AgentCore Evaluations converts traces into a unified format and applies LLM-as-a-Judge techniques, using sophisticated language models to assess performance against defined criteria. Each evaluator produces scores, labels, and explanations, providing actionable insights.
Each evaluator has a unique Amazon Resource Name (ARN). Built-in evaluators are publicly accessible, while custom evaluators remain private and require explicit access grants through AWS IAM policies.
Regional Availability and Pricing
Amazon Bedrock AgentCore Evaluations is available in preview in US East (N. Virginia), US West (Oregon), Asia Pacific (Sydney), and Europe (Frankfurt). Pricing follows a pay-as-you-use model with no upfront commitments. The service supports up to one million input and output tokens per minute per account. Amazon Bedrock AgentCore is included in the AWS Free Tier for new customers.
Conclusion
Amazon Bedrock AgentCore Evaluations represents a significant advancement in AI agent quality assurance. By providing automated, continuous evaluation capabilities integrated with comprehensive observability tools, organizations can deploy AI agents with confidence. The combination of built-in evaluators for common quality dimensions and custom evaluators for business-specific requirements ensures flexibility to meet diverse needs.
As AI agents become central to business operations, the ability to monitor and maintain quality at scale becomes essential. AgentCore Evaluations delivers this capability through a fully managed service working with existing frameworks and models. Organizations can move beyond hoping their agents perform well to knowing they do, backed by data-driven insights.
Drop a query if you have any questions regarding Amazon Bedrock AgentCore and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What agent frameworks does Amazon Bedrock AgentCore Evaluations support?
ANS: – It integrates with Strands Agents, LangGraph, CrewAI, and LlamaIndex using OpenTelemetry and OpenInference instrumentation libraries.
2. How many built-in evaluators are available?
ANS: – Thirteen built-in evaluators covering helpfulness, correctness, faithfulness, goal success rate, tool selection accuracy, harmfulness, and stereotyping detection.
3. Can I create custom evaluators?
ANS: – Yes, by specifying the judge model, inference parameters, evaluation prompts, and rating scales for single traces, sessions, or tool calls.

WRITTEN BY Yerraballi Suresh Kumar Reddy
Suresh is a highly skilled and results-driven Generative AI Engineer with over three years of experience and a proven track record in architecting, developing, and deploying end-to-end LLM-powered applications. His expertise covers the full project lifecycle, from foundational research and model fine-tuning to building scalable, production-grade RAG pipelines and enterprise-level GenAI platforms. Adept at leveraging state-of-the-art models, frameworks, and cloud technologies, Suresh specializes in creating innovative solutions to address complex business challenges.











Comments