

 Login
Login

 March 18, 2026
March 18, 2026|
Voiced by Amazon Polly |
Microsoft Fabric introduces a new way to think about operational data by embedding a relational SQL database directly into an analytics-first platform. SQL Database in Microsoft Fabric combines the familiarity of the Azure SQL engine with Fabric’s unified data, analytics, and AI ecosystem, enabling teams to reduce data movement while accelerating insights.
This blog explores the architecture, use cases, and Fabric-specific best practices for SQL Database in Microsoft Fabric.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Understanding SQL Database in Microsoft Fabric
SQL Database in Fabric is a fully managed, developer-friendly relational database that uses the same SQL engine as Azure SQL Database, while being delivered as a native Fabric workload. Unlike standalone databases, it is designed to participate directly in analytics, reporting, and AI workflows.
SQL Database on Microsoft Fabric automatically mirrors data to OneLake in near real time, enabling analytical workloads without complex ETL pipelines or data duplication. This design makes transactional data immediately available for analytics across Fabric experiences, such as notebooks, pipelines, and Power BI.
Architecture and Fabric Integration
From an architectural perspective, SQL Database in Fabric sits within the unified Fabric platform, rather than operating as an isolated service.
At a high level:
- Data is written to the SQL database using familiar T-SQL and client tools.
- The data is automatically replicated into OneLake in open formats.
- The SQL analytics endpoint allows querying data across SQL databases, lakehouses, and warehouses using three-part naming.
- Security, governance, and capacity are managed at the Fabric workspace level.
Microsoft’s official Fabric architecture diagram illustrates how SQL Database integrates seamlessly with OneLake, data engineering workloads, and analytics services, reinforcing its role as an operational layer within an analytics platform rather than a standalone OLTP system.

Source: Microsoft Fabric Fundamental Documentation
Core Use Cases for SQL Database in Fabric
Operational Analytics
One of the primary use cases for SQL Database in Fabric is operational analytics. It enables teams to analyze fresh transactional data with minimal latency, supporting dashboards and reports that reflect near-real-time business activity without the need for separate ingestion pipelines.
Power BI Serving Layer
SQL Database in Fabric serves as an effective layer for Power BI, especially for curated relational datasets. Its integration with Fabric semantic models and workspace security simplifies governance while supporting self-service analytics.
Application Support and Metadata Management
While not intended for heavy OLTP, SQL Database in Fabric is well-suited for:
- Application metadata
- Configuration tables
- Reference and master data
- Business rules that benefit from relational modeling
These scenarios align well with Fabric’s capacity-based execution model.
Fabric-Specific Best Practices and Optimization
Optimizing SQL Database in Fabric requires a platform-first mindset, rather than traditional database tuning.
Design for Analytics-Aware Workloads
Although it uses the same SQL engine as Azure SQL Database, SQL Database in Fabric is delivered as an analytics-first service. Batch-oriented operations and set-based queries perform better than high-frequency transactional patterns.
Minimize Data Movement
One of Fabric’s key advantages is reduced ETL complexity. Since data is automatically mirrored to OneLake, avoid unnecessary duplication into other Fabric storage layers unless required for large-scale analytics or historical processing.
Align Schema Design with Consumption
Over-normalized schemas designed for OLTP applications may introduce unnecessary complexity. Designing tables with reporting and analytical access patterns in mind improves performance and usability.
Be Capacity Conscious
SQL Database in Fabric shares capacity with other Fabric workloads. Long-running queries or poorly optimized operations can impact overall workspace performance. Scheduling heavy operations during off-peak usage is a practical optimization strategy.
Common Anti-Patterns to Avoid
When adopting SQL Database in Fabric, teams should avoid:
- Treating it as a drop-in replacement for Azure SQL Database
- Running high-frequency, write-heavy application backends
- Over-indexing without understanding workload patterns
- Using it as a full-scale data warehouse
- Ignoring Fabric capacity and concurrency considerations
These patterns often lead to unpredictable performance and architectural complexity.
When to Use Alternatives Instead
Choosing the right Fabric component is essential:
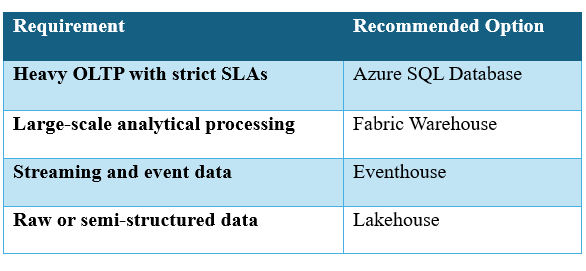
SQL Database in Fabric is most effective when used as a relational operational layer that feeds analytics, not as a traditional application database.
Fabric SQL Advantages
SQL Database in Microsoft Fabric bridges the gap between transactional data and analytics by embedding a familiar SQL engine into a unified data platform. Its strength lies not in replacing traditional OLTP systems, but in enabling operational analytics, simplified architecture, and faster insights within Fabric.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY G R Deeba Lakshmi
G. R. Deeba Lakshmi is a Tech Lead in Azure Data at CloudThat, specializing in AI/ML, Data and Networking. With 15 years of experience in training, software and academics, she has trained over 3000 professionals/students to upskill in Azure AI/ML services, Azure Data services and Azure Databricks. Known for her trainings where she aims in bridging the gap between technology and business outcomes, ensuring seamless adoption of cloud-based solutions to drive innovation and efficiency. Deeba's passion for teaching and socializing reflects in her unique approach to learning and development.











Comments