

 Login
Login

 January 22, 2026
January 22, 2026|
Voiced by Amazon Polly |
Introduction
You’ve built an AI agent that performs perfectly in testing. Demos look great, stakeholders are excited, and deployment feels close. But one critical question remains: how do you know it will work reliably in the real world?
For many teams, agent evaluation becomes the biggest bottleneck. It’s tedious, time-consuming, and requires deep expertise in both evaluation theory and engineering. One developer builds thorough test suites with edge cases and failure scenarios, while another tests only the happy path. Results vary across runs, making progress hard to measure. Months later, documentation is missing, and no one remembers why certain tests exist or how to reproduce past results.
Eval SOP changes this. It’s an AI-powered assistant that turns evaluation into a fast, structured, and repeatable workflow. What once took weeks now takes under an hour, delivering professional-grade results. Think of it as an expert evaluation engineer, consistent, thorough, and meticulously documented.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
The Real Cost of Poor Evaluation
Poor agent evaluation has consequences far beyond wasted time. Your agent may handle simple, happy-path scenarios flawlessly, only to fail catastrophically on edge cases your customers discover in production. These are situations you never thought to test. Meanwhile, different team members design inconsistent evaluations, turning your agent’s reliability into a guessing game. Six months later, no one remembers why certain tests exist, what criteria were used, or how past deployment decisions were justified.
Teams often sink weeks into building custom evaluation infrastructure, writing one-off scripts, debugging evaluation code more complex than the agent itself, and producing reports that are either too technical or too shallow to be useful. While this happens, competitors ship better agents faster because they have solved the evaluation problem.
The uncomfortable truth? Most AI agents ship with inadequate evaluation, not due to negligence, but because rigorous testing demands more time and expertise than teams can realistically afford.
How Eval SOP Works: Intelligence Meets Structure
Eval SOP follows a proven four-phase workflow that mirrors how expert evaluation engineers work, fully automated, accelerated, and enhanced with AI.
- Phase 1: Strategic Planning
Eval SOP begins by understanding your agent, not guessing metrics. It analyzes the agent’s architecture, tools, and core capabilities to design a comprehensive evaluation strategy. It selects the right evaluators, defines success criteria aligned with business goals, and identifies critical failure modes that require coverage.
- Phase 2: Intelligent Test Generation
Eval SOP generates purpose-driven test scenarios rather than random cases. A customer support agent is tested across simple FAQs, complex multi-turn complaints, and escalation scenarios. A code agent is evaluated on correctness, edge cases, security risks, and performance challenges. Every test includes expected outputs, difficulty levels, and metadata for structured analysis.
- Phase 3: Expert Execution
Eval SOP turns plans into production-grade evaluations. It generates clean evaluation scripts using Strands SDK best practices, configures evaluators with precise rubrics, handles execution with error recovery, and aggregates results into structured, queryable datasets.
- Phase 4: Actionable Intelligence
Finally, Eval SOP delivers clarity. It identifies what works, what fails, and why, surfacing patterns, root causes, and concrete improvement recommendations. Reports are tailored for engineers and executives alike, turning evaluation into confident decision-making.
Key Features
- True AI-Powered Automation – Eval SOP goes beyond templates and boilerplate. It uses advanced AI to deeply understand your agent’s architecture, capabilities, and real-world use cases, then generates a fully customized evaluation strategy tailored to your needs.
- Best Practices, Built In – Eval SOP automatically applies evaluation principles that usually take years to master, correct metric selection, robust test coverage, bias mitigation, and statistical rigor, without requiring you to become an evaluation expert.
- Production-Ready Code Generation – The evaluation scripts aren’t drafts or examples. Eval SOP generates clean, production-quality Python code that follows Strands SDK best practices, includes proper error handling, and runs immediately without rework.
- Comprehensive Coverage Without Overwhelm – Eval SOP systematically tests happy paths, edge cases, failure modes, and boundary conditions while keeping results clear and manageable, delivering depth without unnecessary complexity.
- Reproducible by Design – A standardized workflow ensures consistent results across teams and time. Evaluation artifacts are versionable and fully reproducible months or years later.
- Flexible Integration – Use Eval SOP via MCP servers for Claude Code, direct Python SDK integration, or Anthropic Skills for Claude.ai, fitting seamlessly into your existing workflow.
Installation and Setup
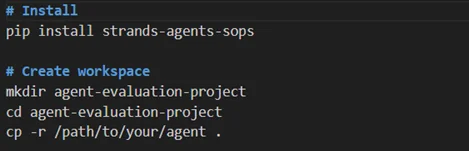
Integration with Strands(Direct Python Integration)

MCP Integration
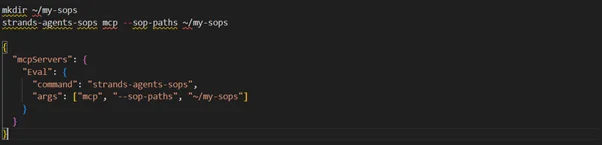
Use Cases
- E-Commerce Customer Support – A major retailer’s support agent showed inconsistent customer satisfaction, ranging from 65% to 95% depending on query complexity. Using the Eval SOP, the team generated 75 targeted test cases covering product inquiries, returns, complaint escalation, and edge cases, including out-of-stock items. The evaluation revealed strong performance on factual queries (95% accuracy) but weak empathetic handling in complaints (58% satisfaction). After refining tone and escalation logic based on these insights, satisfaction stabilized at 89% across all scenarios, and ticket resolution time dropped by 34%
- Legal Research Assistant – A law firm required absolute confidence in citation accuracy. Eval SOP evaluated case law research, statute interpretation, and cross-jurisdictional queries. While answer accuracy reached 92%, unnecessary database queries occurred in 43% of cases, increasing costs, and citation formatting errors appeared 12% of the time. Optimizing query logic and adding citation validators reduced costs by 47% and improved accuracy to 99.3%
- Code Generation Platform – A developer tools startup used Eval SOP to generate 200+ test cases across Python, JavaScript, Go, and Rust. The evaluation uncovered SQL injection risks in 8% of database code, poor edge-case handling (23% failure rate), and weaker performance in Go and Rust. Targeted improvements reduced security issues to 0.3% and increased error-handling coverage to 94%.
Conclusion
Most AI agents ship with weak evaluation, not because teams don’t care, but because rigorous testing demands time and expertise they can’t afford. So teams deploy cautiously and hope users don’t uncover critical failures. Eval SOP removes this trade-off.
Teams that win in AI don’t just build smarter models, they build more reliable agents. Eval SOP gives you the foundation to do exactly that.
Drop a query if you have any questions regarding Eval SOP and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Do I need Python or evaluation expertise?
ANS: – No. Eval SOP automatically generates all evaluation logic, Python is only needed for optional customization.
2. How long does an evaluation take?
ANS: – Typically under an hour end-to-end, including planning, execution, and reporting.
3. Can I use Eval SOP with non-Strands agents?
ANS: – Yes. The methodology and test cases are framework-agnostic and can be adapted to any setup.

WRITTEN BY Livi Johari
Livi Johari is a Research Associate at CloudThat with a keen interest in Data Science, Artificial Intelligence (AI), and the Internet of Things (IoT). She is passionate about building intelligent, data-driven solutions that integrate AI with connected devices to enable smarter automation and real-time decision-making. In her free time, she enjoys learning new programming languages and exploring emerging technologies to stay current with the latest innovations in AI, data analytics, and AIoT ecosystems.










Comments