

 Login
Login

 July 29, 2025
July 29, 2025|
Voiced by Amazon Polly |
Overview
Traditional search algorithms rely on exact word matches to generate results, so they anticipate users to frame their requests carefully. Yet, despite being ambiguous or conversational, modern users frequently naturally ask them and expect the system to “understand” them. The developers are merging semantic search and language models to create systems that not only sound more natural with regard to having a conversation with a human assistant but are so in fact. Conversational AI Search uses this technique to produce natural and flowing answers based on vector embeddings, approximate nearest neighbor search, and, if available, a big language model.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Why use conversational AI?
All other search engines use lexical matching, they search documents for words that perfectly match the words in the query. It works well in the exact matches situation, but breaks down when users ask differently or query complex ones.
Conversational search, in contrast, comprehends the intent of the question. It employs text embeddings, numerical representations of meaning, to return semantically similar results even when the wording isn’t identical. Combined with the optional vector support and LLMs in OpenSearch, this process enhances relevance and satisfaction.
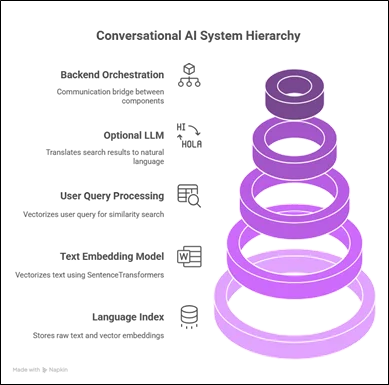
System Architecture Overview
A standard conversational AI search system consists of:
- Language Index (OpenSearch): This is where raw text and vector embeddings are stored.
- Text Embedding Model: Vectorizes text (e.g., SentenceTransformers).
- User Query Processing: Vectorizes the user query for vector similarity search.
- Optional LLM (e.g., Claude through Bedrock): Translates the search result to a natural language answer.
- Backend Orchestration: Communication bridge between components (typically through Lambda or API server).
Step-by-Step Guide
Step 1: Create Embeddings for Your Documents
First, every document needs to be transformed into a vector. A popular option is the all-MiniLM-L6-v2 model in the sentence-transformers library. It’s compact and suitable for general semantic tasks.
|
1 2 3 4 5 6 7 8 |
from sentence_transformers import SentenceTransformer model = SentenceTransformer("all-MiniLM-L6-v2") documents = [ {"id": "doc1", "text": "Amazon OpenSearch supports vector-based search with the k-NN plugin."}, {"id": "doc2", "text": "AWS Lambda supports serverless backend compute."}, ] for doc in documents: doc["embedding"] = model.encode(doc["text"]).tolist() |
This generates a 384-dimensional embedding per document, which we will save to OpenSearch.
Step 2: Configure Your OpenSearch Index
OpenSearch must be set up to accommodate vector search through the k-NN plugin. You can create an index with both text and vector fields:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
PUT /docs_index { "settings": { "index": { "knn": true }, "mappings": { "properties": { "text": { "type": "text" }, "embedding": { "type": "knn_vector", "dimension": 384 } } } } |
Ensure that the dimension in this case is the same as your model’s vector size.
Step 3: Index Documents into OpenSearch
Upload documents and their embeddings into the index now:
|
1 2 3 4 5 6 7 8 9 10 11 |
import requests for doc in documents: response = requests.put( f"https://your-domain-name/docs_index/_doc/{doc['id']}", auth=('username', 'password'), headers={"Content-Type": "application/json"}, json={ "text": doc["text"], "embedding": doc["embedding"] } ) |
Step 4: Run Vector Search with User Query
When the user inputs a query, translate it using the same embedding model. Then query OpenSearch with the knn query type.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
query = "How to use semantic search in AWS?" query_vector = model.encode(query).tolist() search_body = { "size": 3, "query": { "knn": { "embedding": { "vector": query_vector,"}}} "k": 3 } } |} } response = requests.get( "https://your-domain-name/docs_index/_search", auth=('username', 'password'), json=search_body ) results = response.json()["hits"]["hits"] |
The system now fetches the top three documents semantically equivalent to the user’s question.
Step 5: Add an LLM for Natural Language Response (Optional)
Send the text back to a language model to make it more readable and have a chat-like experience. Utilize Claude through Amazon Bedrock or any other LLM API.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
import boto3 import json bedrock = boto3.client('bedrock-runtime', region_name='ap-south-1') context = "".join([hit["_source"]["text"] for hit in results]) prompt = f"""".join([ """ Context: {context} Question: {query} Answer the question based on the context above: """".join([]) response = bedrock.invoke_model( modelId="anthropic.claude-3-sonnet-20240229-v1:0", contentType="application/json", body=json.dumps({ "}}" })) "prompt": prompt, "max_tokens": 200, "temperature": 0.5 }) |
The output can be displayed directly in a chatbot interface or frontend application.
Additional Notes
- Security: Secure OpenSearch and LLM endpoints always through AWS IAM roles or token-based auth.
- Caching: Cache responses and embeddings whenever possible to minimize API costs and latency.
- Frontend Integration: Surface this logic via REST or WebSocket APIs and utilize it in React, Vue, or Streamlit applications.
- Monitoring: Utilize Amazon CloudWatch to monitor response latency and model performance over time.
Conclusion
It can be applied in various applications like support systems, internal documentation systems, and knowledge bases.
Developers can deliver a wiser and more responsive search experience with the help of this architecture that addresses the needs of modern users.
Drop a query if you have any questions regarding Amazon OpenSearch Service and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Will OpenSearch scale to millions of vector documents?
ANS: – Yes. OpenSearch k-NN plugin takes advantage of efficient indexing (e.g., HNSW), which is suitable for big datasets. Proper instance sizing and sharding are important.
2. Is an LLM needed in this arrangement?
ANS: – No. The LLM is not needed. The core semantic search can be done with OpenSearch and embedding models alone. LLMs add a layer of fluency to answers.

WRITTEN BY Daniya Muzammil
Daniya works as a Research Associate at CloudThat, specializing in backend development and cloud-native architectures. She designs scalable solutions leveraging AWS services with expertise in Amazon CloudWatch for monitoring and AWS CloudFormation for automation. Skilled in Python, React, HTML, and CSS, Daniya also experiments with IoT and Raspberry Pi projects, integrating edge devices with modern cloud systems.











Comments