

 Login
Login

 March 15, 2023
March 15, 2023|
Voiced by Amazon Polly |
Introduction
Amazon Redshift is a data warehouse service for large-scale data storage and analysis. Apache Spark is an open-source big data processing engine that processes large datasets quickly and efficiently. Combining these two powerful technologies can create a comprehensive solution for big data analytics.
The Apache Spark integration for Amazon Redshift builds on an already-existing open-source connector project. It improves it for speed and security, giving users access to up to 10x better application performance. We appreciate the help from the project’s initial contributors, who worked with us to make this possible. We will keep improving and giving back to the open-source project.
With the Amazon Redshift integration for Apache Spark, you can easily create Apache Spark applications in various languages, including Java, Scala, and Python, and get up and running in seconds.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Creating an Application
To get started, go to AWS analytics and ML services, connect to the Amazon Redshift data warehouse using a data frame or Spark SQL code in a Spark job or Notebook, and immediately begin performing queries.
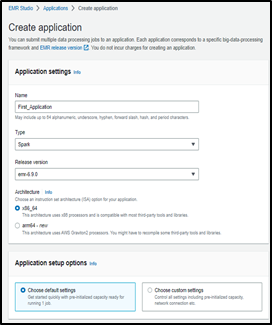
You can immediately begin developing code with the pre-packaged connector, and JDBC driver included with Amazon EMR 6.9, EMR Serverless, and AWS Glue 4.0. EMR Serverless and EMR 6.9 have sample Spark Jobs and notebooks, respectively.
With the emr-6.9.0 release, you can use EMR Serverless to build your Spark application and run your workload.
EMR Studio also provides a sample Jupyter Notebook configured to connect to an Amazon Redshift Serverless endpoint using test data.

AWS Glue
The spark-redshift connector is accessible as a source and target when using Amazon Glue 4.0. By choosing a Redshift connection within a built-in Redshift source or target node, you may use a visual ETL job in Glue Studio to read from or write to a Redshift data warehouse.
The Redshift connection contains information about how to connect to Redshift and the login information required to access Redshift with the right permissions.
- Choose Jobs from the Glue Studio console’s left menu.
- You may quickly add and change a source or target node and specify a variety of data transformations using any of the Visual modes without writing any code and click create.

- Once you select create, you may easily create and edit a source, target node, and transform node in the job diagram. At this time, you will choose Amazon Redshift as Source and Target.

- After it has been finished, the Apache Spark engine’s Glue job can be executed.
- When you set up the job detail, we can use the Glue 4.0 – Supports spark 3.3 Python 3 version for this integration.
- Once the job detail is updated, Hit the Run button to start the job.

Benefits of the Integration
Amazon Redshift Integration for Apache Spark is a powerful tool that allows users to analyze large data sets in a distributed computing environment. Here are some benefits of using this integration:
- Scalability: With Redshift Integration for Apache Spark, users can process large amounts of data in a scalable and distributed manner. This enables organizations to store and analyze large data sets without worrying about performance issues.
- Real-time data processing: The integration allows real-time data processing, which is essential for organizations making fast and accurate decisions. It enables Spark to interact with Redshift in real-time, making it possible to process data as it is generated.
- Improved performance: The integration enhances performance by allowing Spark to access data stored in Redshift directly. This reduces the time required to transfer data between systems and enables faster query processing.
- Cost-effective: The integration reduces infrastructure costs by allowing users to store data in Redshift, a cost-effective data warehousing solution. This reduces the need for expensive on-premises infrastructure and makes it easier to manage data.
- Easier data analysis: The integration simplifies data analysis by allowing users to use familiar Spark APIs to process data stored in Redshift. This makes it easier for organizations to analyze and derive insights from data.
The Amazon Redshift Integration for Apache Spark offers a cost-effective, scalable, and efficient solution for processing large data sets.
Conclusion
In conclusion, integrating Amazon Redshift with Apache Spark provides a powerful solution for big data analytics. The integration provides many benefits. Integrating these two technologies is a simple process that can be done in a few easy steps. Combining the power of Amazon Redshift and Apache Spark can create a comprehensive solution for big data analytics that can help you make better decisions and achieve better results.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. What data sources can I use with Amazon Redshift Integration for Apache Spark?
ANS: – You can use a variety of data sources with this integration, including:
- Amazon S3
- Amazon DynamoDB
- Apache Kafka
- Apache HBase
- Amazon EMR (Elastic MapReduce)
2. Can I use Amazon Redshift Spectrum with Amazon Redshift Integration for Apache Spark?
ANS: – Yes, you can use Amazon Redshift Spectrum with this integration. Amazon Redshift Spectrum allows you to query data stored in Amazon S3 using your Redshift cluster, and you can use Spark to process the data returned by Spectrum.

WRITTEN BY Abhilasha D
Abhilasha D works as a Research Associate-DevOps at CloudThat. She is focused on gaining knowledge of the cloud environment and DevOps tools. Abhilasha is interested in learning and researching emerging technologies and is skilled in dealing with problems in a resourceful manner.










Comments