

 Login
Login

 January 22, 2026
January 22, 2026|
Voiced by Amazon Polly |
Introduction
The growth of Large Language Models has caused a paradigm shift in how developers program, review, and reason about their code. From basic code completion to comprehensive understanding of a code repository, the latest state-of-the-art AI-based coding assistants are increasingly used as essential tools for programming tasks. However, few models have effectively understood how real-world code changes over time.
In this blog, we will discuss what makes this model particularly distinctive, its training process, functionalities, benchmarks, and, finally, its role in contemporary developer culture.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
High-Level Overview
IQuest-Coder-V1-40B-Instruct is an open-source instruction-tuned large language model specialized for coding and software engineering tasks. It supports up to 128K tokens of context, enabling deep reasoning across large codebases and multi-file projects. Contrary to traditional code models, which are mostly trained on static snapshots of code, IQuest-Coder learns from the evolution of code, for instance, how developers fix bugs over time, refactor logic, and implement features.
At a high level, the model attempts to perform the following:
- Follow natural language coding instructions accurately.
- Understand complicated repositories and long-range dependencies.
- Create, refactor, and debug production-quality code.
- Perform real-world engineering tasks, rather than isolated snippets of assistance.
It is this abstraction that makes Semmler QL particularly well-suited to IDE assistants, independent coding agents, and enterprise-grade developer tools.
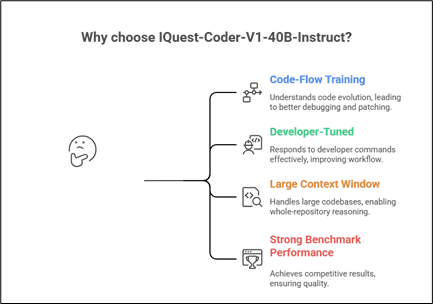
What Makes IQuest-Coder-V1-40B-Instruct Different?
- Code-Flow Training Paradigm
Code LLMs are typically trained on static data: code files scraped off code repositories or code examples along with their documentation. In contrast, IQuest-Coder learns from code flow that entails:
- Commit histories
- Code diffs
- Bug-fix patterns
- Refactoring sequences
This enables the model to understand why code modifications are needed, beyond simply knowing the final code. This leads to it performing well in tasks such as code debugging, code patching, and multi-step code changes.
- Developers-Tuned for Developers
The Instruct variant is specifically trained to comply with developer commands. No matter if the user requests:
- “Refactor for performance” in the given function
- “Fix the bug without changing the public API”
- “Explain this code to a junior developer”
The model is optimized to respond in a structured, actionable, and developer-friendly fashion.
- Large Context Window (128 K Tokens)
Among the most difficult problems in real-world programming is that of “context fragmentation.” Code can run across tens or hundreds of files. “IQuest-Coder-V1-40B-Instruct” addresses these problems by supporting 128K tokens natively, which allows for:
- Whole-repository reasoning
- Cross-file dependency understanding
- Large specification-to-implementation workflows
This is particularly valuable for monorepos, microservices architectures, and legacy codebases.
- Strong Benchmark Performance
The model has shown competitive results for coding benchmarks:
- SWE-Bench (Verified) – Benchmarks the ability to fix
- LiveCodeBench – Assisting in Interactive Coding Tasks
- BigCodeBench – Evaluating Code Generation Quality over Different Domains
The performance achieved by these models puts IQuest-Coder-V1-40B-Instruct amongst the best open-source coding.
Core Capabilities and Use Cases
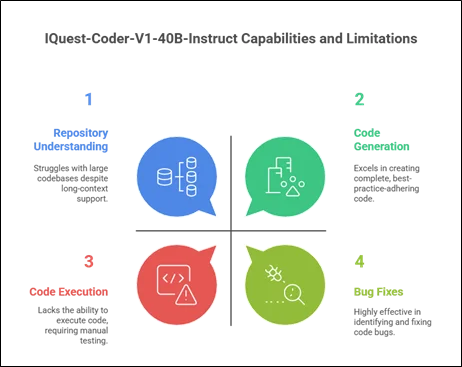
Code Generation and Completion
It can produce complete functions, classes, and modules of code written in a variety of programming languages. It follows the best practices and design patterns.
Bug Fixes and Debugging
Code flow training is very effective at pinpointing bugs in code and providing appropriate fixes.
Refactoring and Optimization
It might refactor code to improve understanding, optimize performance, or address uncertainty, while retaining its functionality.
Repository Understanding
A long-context model would enable it to handle large code bases, understand architecture, and make cross-module changes.
Developer Education and Documentation
It can interpret complex code, write comments, and assist in training new programmers by walking them through code logic step by step.
Deployment and Integration
The IQuest-Coder-V1-40B-Instruct model can be accessed using the Hugging Face Transformers library:
- Multi-GPU step-up configurations
- Inference engines such as vLLM
- On premises or private customer cloud
Thus, it is best for the organizations that require data privacy, customized tech, or controlled AIs.
Limitations to Keep in Mind
Despite its strengths, the model has weaknesses:
- It does not execute code; the outputs need to be tested manually
- Performance could be variable on highly proprietary or specialist frameworks
- “Like other LLMs, it can make ‘confident’ but ‘incorrect’ predictions.”
Proper validation, testing, and human oversight remain essential.
Conclusion
IQuest-Coder-V1-40B-Instruct is a major improvement over existing AI tools for software engineering. With this model, the AI goes beyond training from the actual code and takes a more code-flow-centric paradigm. This model has a large parameter count of 40 billion. Instruction tuning and support for a long context with strong benchmarks make it the most attractive open-source coding model available.
For teams developing intelligent IDEs, coding agents with AI capabilities, or enterprise developer platforms, this model can provide a robust starting point. Though the model cannot substitute for human intelligence, it can significantly improve productivity, comprehension, and code quality when used prudently.
Drop a query if you have any questions regarding IQuest-Coder-V1-40B-Instruct and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is the most significant advantage of IQuest-Coder-V1-40B-Instruct over other code LLMs?
ANS: – The code-flow training it gets enables a deeper understanding of real software evolution; hence, it will be stronger at tasks like debugging, refactoring, and multi-file reasoning.
2. Is this model already good to go for production?
ANS: – Yes, it can be deployed to production environments, mostly for internal tools, IDE assistants, and code analysis systems, provided outputs are appropriately validated.
3. How much context is the model able to handle?
ANS: – It supports 128K tokens, hence large repositories or large specifications can be processed in a single prompt.

WRITTEN BY Akanksha Choudhary
Akanksha works as a Research Associate at CloudThat, specializing in data analysis and cloud-native solutions. She designs scalable data pipelines leveraging AWS services such as AWS Lambda, Amazon API Gateway, Amazon DynamoDB, and Amazon S3. She is skilled in Python and frontend technologies including React, HTML, CSS, and Tailwind CSS.










Comments