

 Login
Login

 January 23, 2026
January 23, 2026|
Voiced by Amazon Polly |
Overview
In today’s data-driven world, organizations are collecting data from multiple sources, applications, sensors, customer interactions, third-party APIs, and more. This data then flows through complex pipelines before finally reaching dashboards, reports, or machine learning models. But one important question often gets ignored: where did this data actually come from, and how did it reach here?
This is where data lineage comes into the picture.
For data engineers, data lineage is not just a “nice-to-have” feature. It is a critical foundation for trust, governance, debugging, and compliance. In this blog, we will understand what data lineage is, why it matters so much in data engineering, and how it helps organizations make confident decisions.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Data Lineage
Simply put, data lineage describes the path a piece of data takes from its source to its destination. It tracks how data is created, transformed, moved, and consumed across systems.
For example:
- Data originates from a transactional database
- It gets ingested into a data lake
- It is cleaned and transformed using ETL/ELT jobs
- Aggregations are created in a data warehouse
- Finally, it appears in a BI dashboard
Data lineage answers questions like:
- Which source systems contributed to this report?
- What transformations were applied to this column?
- If a source field changes, which dashboards will break?
In technical terms, lineage can be:
- Table-level lineage – Tracking tables and datasets
- Column-level lineage – Tracking individual fields
- End-to-end lineage – From source to final consumer
Why Data Lineage Is Important in Data Engineering?
- Builds Trust in Data
One of the biggest challenges in organisations is a lack of trust in data. Business users often say, “These numbers don’t match” or “Which report is correct?”
With proper data lineage:
- Users can clearly see where the data came from
- Transformations are transparent
- Assumptions and logic are documented
When people understand the data journey, confidence automatically increases. This is extremely important for decision-making at the leadership level.
- Faster Debugging and Root Cause Analysis
Every data engineer has faced this situation: a dashboard suddenly shows wrong numbers, and everyone is asking questions.
Without lineage:
- You manually check pipelines
- You scan SQL scripts
- You guess where things might have gone wrong
With lineage:
- You trace the issue backwards
- You immediately identify the broken job or source
- You save hours (sometimes days) of effort
In production systems, this can be the difference between a minor incident and a major outage.
- Impact Analysis Becomes Easy
In real-world projects, changes are constant:
- A column is renamed
- A source table is deprecated
- A business rule is updated
Before making any change, data engineers must answer:
What will break if I change this?
Data lineage provides impact analysis, showing:
- Which downstream tables depend on this column
- Which dashboards or ML models will be affected
- Which teams need to be informed
This reduces risk and avoids unpleasant surprises after deployment.
- Essential for Data Governance and Compliance
With regulations like GDPR, DPDP Act (India), HIPAA, and SOX, organisations are required to know:
- Where sensitive data is stored
- How it is processed
- Who has access to it
Data lineage helps in:
- Tracking Personally Identifiable Information (PII)
- Auditing data flows
- Proving compliance during audits
For industries like banking, healthcare, and fintech, lineage is not optional, it is mandatory.
- Supports Scalable and Maintainable Pipelines
As data platforms grow, pipelines become more complex. New engineers join the team, old ones leave, and documentation becomes outdated.
Data lineage acts like living documentation:
- New team members understand pipelines faster
- Dependencies are visible instead of hidden
- Technical debt is easier to manage
This is especially useful in large Indian IT teams where projects are long-running and ownership changes frequently.
- Improves Collaboration Between Teams
Data engineering does not work in isolation. There are:
- Data analysts
- Data scientists
- Business users
- Compliance teams
With clear lineage:
- Analysts know which dataset to trust
- Data scientists understand feature origins
- Business teams get clarity on metrics
This reduces back-and-forth communication and improves overall productivity.
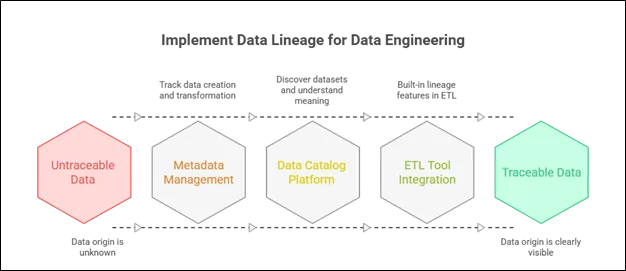
How Data Lineage Is Implemented in Practice?
In modern data stacks, lineage is usually implemented using:
- Metadata management tools
- Data catalog platforms
- Built-in lineage features in ETL tools
Popular tools include:
- Apache Atlas
- OpenLineage
- DataHub
- Collibra
- Alation
- dbt (for transformation lineage)
Many cloud platforms, such as AWS, Azure, and GCP, also provide partial lineage capabilities through their services.
Challenges in Implementing Data Lineage
While data lineage is powerful, it does come with challenges:
- High initial setup effort – Establishing data lineage requires significant time to understand existing data flows and dependencies. Initial configuration often involves coordination across teams and systems.
- Integrating multiple tools – Organizations use diverse platforms, making seamless integration complex. Ensuring consistent metadata across tools requires additional engineering effort.
- Keeping lineage updated with frequent changes – Frequent schema and pipeline changes can quickly make lineage outdated. Continuous monitoring and automation are needed to maintain accuracy.
- Handling custom scripts and legacy systems – Custom code and legacy platforms often lack built-in lineage support. Capturing lineage for these systems usually requires manual intervention or custom solutions.
However, the long-term benefits far outweigh these challenges.
Conclusion
In data engineering, building pipelines is only half the job. The other half is ensuring that data is understandable, reliable, and traceable. Data lineage plays a crucial role in achieving this.
Drop a query if you have any questions regarding Data Lineage and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Is Data Lineage only useful for large organizations?
ANS: – No, not at all. While large enterprises benefit the most, even small and mid-sized teams can gain value from data lineage. If you have multiple data sources, transformations, and consumers, lineage helps avoid confusion and future rework. Starting early is actually better.
2. What is the difference between data lineage and data catalog?
ANS: – A data catalog helps users discover datasets and understand their meaning.
Data lineage focuses on how data flows and transforms.
In simple terms:
- Catalog answers: What data do I have?
- Lineage answers: Where did this data come from, and how did it change?

WRITTEN BY Hridya Hari
Hridya Hari is a Subject Matter Expert in Data and AIoT at CloudThat. She is a passionate data science enthusiast with expertise in Python, SQL, AWS, and exploratory data analysis.











Comments