

 Login
Login

 September 17, 2025
September 17, 2025|
Voiced by Amazon Polly |
Introduction
In today’s cloud-native DevOps landscape, downtime and manual firefighting remain the biggest obstacles to operational excellence. Even with monitoring and alerting systems in place, engineers often get pulled into repetitive, predictable incidents like disk pressure, pod evictions, or instance failures. This impacts Mean Time to Recovery (MTTR) and drains engineering focus from innovation.
This is where self-healing infrastructure powered by automation comes into play. By leveraging AWS EventBridge, AWS Lambda, and AWS Systems Manager, teams can build remediation playbooks that automatically detect, respond, and recover from failures without human intervention. In this extended blog, we explore the architecture of self-healing infrastructure, common challenges it addresses, and best practices for implementing automated remediation at scale.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Architecture Overview
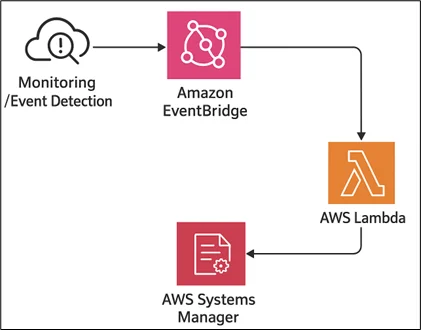
Architecture Explanation:
The architecture illustrates a self-healing pipeline in a cloud-native environment hosted on AWS. Telemetry and monitoring systems such as Amazon CloudWatch or Datadog raise events on anomalies, be it high CPU utilization, pod crash loops, or storage exhaustion.
These events are routed to Amazon EventBridge, where rules map specific patterns (e.g., “Amazon EBS volume at 90% utilization”) to automated remediation workflows. Amazon EventBridge then triggers AWS Lambda functions that execute predefined playbooks, such as scaling out Amazon EKS nodes, cleaning up disk space, restarting unhealthy pods, or attaching additional volumes.
AWS Lambda invokes AWS Systems Manager Automation Documents (SSM Documents) to orchestrate multi-step remediations for complex workflows. The result is a closed-loop system where issues are resolved automatically, reducing downtime and reliance on manual on-call intervention.
The Shift from Reactive Ops to Proactive Self-Healing
Traditional operations rely on human intervention, alerts trigger tickets, engineers investigate, and manual fixes are applied. While this ensures control, it slows down recovery and increases on-call fatigue.
Self-healing infrastructure changes this paradigm. By codifying remediation steps into automated workflows, teams move from reactive firefighting to proactive resilience. Infrastructure can detect, diagnose, and heal itself in real time.
Core Components of Self-Healing Infrastructure
- Event Detection
- Source: Amazon CloudWatch Alarms, Datadog alerts, Kubernetes events.
- Role: Identify the anomaly that requires remediation.
- Best Practice: Define actionable events with context to avoid false positives.
- Event Routing & Filtering
- Tool: Amazon EventBridge.
- Role: Route events to the right remediation workflow.
- Best Practice: Use fine-grained event patterns to map issues and correct playbooks.
- Automated Remediation Engine
- Tools: AWS Lambda, AWS Systems Manager Automation.
- Role: Execute self-healing actions such as restarting pods, attaching volumes, or scaling nodes.
- Best Practice: Modularize playbooks for reusability across multiple scenarios.
- Validation & Feedback Loop
- Tool: Amazon CloudWatch Logs, Datadog dashboards.
- Role: Verify whether remediation succeeded and log details for audit.
- Best Practice: Always include validation steps before closing incidents automatically.
Challenges in Implementing Self-Healing
Over-Automation Risks
- Blind automation may cause cascading failures.
- Solution: Implement guardrails with conditional checks and human approval for critical actions.
Complex Failure Scenarios
- Not all failures can be codified easily.
- Solution: Start with repetitive, predictable issues (e.g., restarting unhealthy nodes) and evolve playbooks gradually.
Noise vs. Signal
- Too many alerts may trigger unnecessary automation.
- Solution: Tune alert thresholds and ensure only actionable events invoke playbooks.
Best Practices for Building Self-Healing Infrastructure
- Start Small with High-Frequency Failures
Automate fixes for repetitive issues like pod restarts, disk cleanup, or scaling thresholds before tackling complex failures. - Build Modular Remediation Playbooks
Use AWS Lambda functions and SSM documents in reusable modules so workflows can be combined for more advanced scenarios. - Integrate with CI/CD
Test remediation scripts as part of pipelines to ensure they work reliably before production rollout. - Incorporate Safety Nets
Use rollback mechanisms and approval workflows for sensitive operations (like database failover). - Continuously Improve with Feedback Loops
Capture logs and outcomes of remediation actions to refine automation over time.
Outcome of Implementing Self-Healing
- 60% reduction in MTTR, incidents resolved automatically within minutes instead of hours.
- Significant decrease in on-call fatigue, fewer manual midnight interventions for routine issues.
- Improved system reliability, automated scaling, and healing ensure consistent availability.
- Higher developer productivity, engineers focus on innovation instead of firefighting.
- Enhanced stakeholder trust, resilience, and uptime SLAs consistently achieved.
Conclusion
As systems grow more complex, manual intervention becomes a bottleneck. Self-healing infrastructure shifts the focus from reactive recovery to proactive resilience. By combining AWS EventBridge, AWS Lambda, and AWS Systems Manager, organizations can create a robust remediation framework that keeps systems healthy, reduces downtime, and empowers teams to focus on building value.
Drop a query if you have any questions regarding Self-healing infrastructure and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. What’s the difference between auto-scaling and self-healing?
ANS: – Auto-scaling adjusts capacity based on demand. Self-healing detects and fixes failures automatically, like restarting failed pods or replacing unhealthy nodes.
2. Can all incidents be self-healed?
ANS: – No. Start with predictable, repetitive issues. Keep humans in the loop for complex, business-critical failures.

WRITTEN BY Sourabh Murgod
Sourabh Murgod works as a Research Associate at CloudThat, focusing on AWS, Kubernetes, and DevOps engineering. He is passionate about designing scalable cloud architectures, automating infrastructure, and optimizing production workloads.










Comments