

 Login
Login- Consulting
- Training
- Partners
- About Us
x
Cloud Computing, Cloud Native Application Development
 8 Mins Read
8 Mins Read

 May 27, 2022
May 27, 2022A Web Rendering Engine brings the requested web pages to your computing device screen. It has the ability to interpret HTML and XML pages with CSS code. My previous blog post introduced readers to the fundamentals of Web Browsers and this post deciphers the working of Browser’s Rendering Engine in a lucid style.
A web browser’s rendering engine renders or displays the requested material on the canvas/window of the browser. The networking engine provides the desired content.

Pictorial Representation: Rendering Engine for Web Browsers
Although the networking engine can acquire a variety of stuff, not all of it is given to the rendering engine. For example,.JS, .JSON, .CSV, .PDF, etc. The PDF viewer plug-in is used to show PDF documents. For the sake of simplicity, we will just discuss the main content types provided to the rendering engine, namely HTML(.html), CSS(.css), and Images.
Let us have a look at what’s going on within the rendering engine. The rendering engine, like the networking engine, is implemented differently by different manufacturers. The essential flow, though, is the same for all. It consists of three important steps: Parse, Layout, and Publish.

The rendering engine processes the HTML and CSS files received from the networking engine before painting them to the browser’s window. The HTML and CSS raw data are parsed using HTML and CSS parsers, respectively, to produce two tree models for completely distinct purposes: Document Object Model (DOM) and CSS Object Model (CSS Object Model) (CSSOM). The browser then constructs a Render Tree by combining the two trees (DOM and CSSOM). This tree provides the information about all the visible elements to render on the screen. However, the element’s actual size and position are missing from this render tree. The Layout stage in the rendering engine is in charge of this. After estimating the dimensions and position, the actual painting process begins. The Paint phase does not do any calculations. Its only job is to print/render/paint on the browser’s screen.
If you’re a frontend developer, you’ve probably come across the word WebKit while troubleshooting CSS bugs. WebKit is nothing more than a rendering engine. The following are some examples of rendering engines utilised by various browsers:
We’ll stick with WebKit, the most popular and open-source rendering engine, for the purpose of consistency in this post.
The following standards specify the parsing step of the rendering process in any browser:
whatwg.org is an HTML parser.
w3.org CSS Parser
Because the core steps in both the HTML and CSS parsers are the same, we combined them into a single diagram below:

Pre-Processing
The input stream is initially processed to make it appropriate for tokenization before being sent on to the tokenization stage. For the sake of this article, we shall only skim the surface of HTML/CSS parsers. Visit the links above for further information on the parsing methods. The raw input stream is first transformed to code points. The Unicode representation of these code points begins with “U+” and is followed by four/six hex codes. For instance, “🤔” is written as “U+1F914”. Second, in the pre-processing stage, normalizing newlines is another step. In HTML DOMs, newlines are represented by “U+000A LF” (Line Feed) characters rather than “U+000D CR” (Carriage Return). Finally, any “U+0000 NULL” is replaced.
Tokenization
The stage of tokenization is a two-step procedure. Making a token and sending a token are two different things. Each and every entity in the code is represented by a token, which is a node. Aside from representation, a token also carries all of the data associated with that node. A name, a public identifier, a system identifier, and a force-quirks flag are all included in DOCTYPE tokens, for example. The tree construction step takes care of a token as soon as it is emitted. The state of the tokenization stage can be influenced by the tree construction stage, and additional characters can be inserted into the stream. (For example, the script element can cause scripts to run and inject characters into the tokenized stream using the DOM insertion APIs.)
Tree Construction
This step receives the tokens from the tokenization stage and builds a dynamically updating DOM/CCSOM tree. The user agent can use the tree built in this phase for rendering purposes. There are a set of rules called a tree construction dispatcher specific to the token received from the stream, according to the specifications defined by whatwg.org.
Subresource loading
If “image” or “link” tokens are received when receiving HTML tokens, a request is sent to the browser’s network engine. To speed things up, the browser performs a “preload scanner” at the same time. This scanner looks at the tokens created by the HTML parser and performs the necessary actions in a thread separate from the parser. This pauses the HTML parser until the JS file is done with its duty.
Blocking Parser
If “script” tokens are obtained when receiving HTML tokens, it signifies there is a Javascript file that needs to be downloaded and executed. Because the javascript can contain statements that affect the DOM/CSSOM structure, this step can be a blocker. In the previous diagram, this stage is depicted as a feedback loop.
Conclusion of Parser
If the code is:
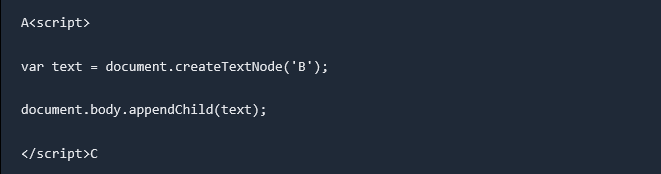
The HTML parser will generate the following tree:

Rendering Engine Step 2: Creation of Render Tree
The previous phase of creating separate DOM and CSSOM trees resulted in well-defined parent-child relationships between various nodes, as well as rich meta-information regarding structure and style. Both, however, lack the complete information required for the browser to appear on the screen. The browser builds another tree, the Render Tree, while the DOM and CSSOM trees are being built.

The render tree is the document’s visual representation. The goal of this tree is to allow you to paint the components in the proper sequence. Each node/element in the render tree is referred to as a render object. If you come up a different name for it somewhere else, don’t be alarmed. Firefox, for example, refers to the items in the render tree as “frames.” The phrase renderer or render object is used by WebKit.

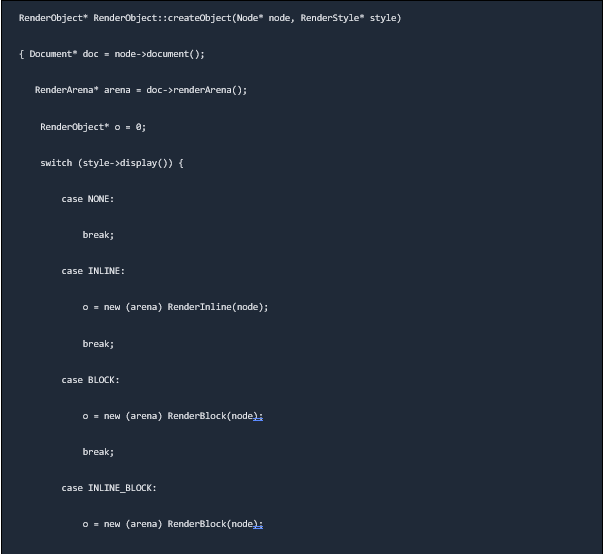
The rendered object has all the visual data and knows how to position itself and its children on the screen. WebKit’s render object base class, for example, is defined as follows:


Each render object represents a rectangular region that corresponds to the CSS box of a node, as defined by the CSS specification. It contains geometric data such as width, height, and position. The “display” value of the style attribute that is relevant to the node has an impact on the box type. According to the display attribute, WebKit code determines what type of render object should be built for a DOM node:
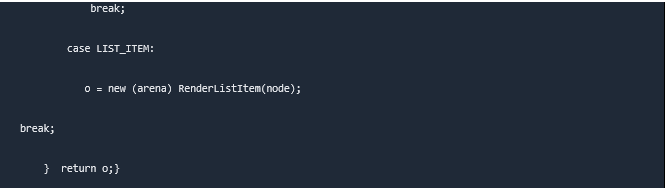
The render tree does not have a location or size when nodes are added. The goal of this Layout stage is to calculate these values. The render object provides the base for size, whereas the browser’s view port provides the base for the position (visible part of a browser). The position is always related to the view port’s top-left coordinates.
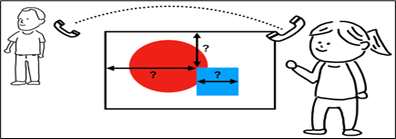
Google Developers is the source of this image. The document’s arrangement is done from left to right, top to bottom. With a few exceptions, the position and size are determined in a single pass most of the time (HTML tables may require more than one pass). Every render object has a “layout” method defined in it. The layout method of each render object’s children is called the required layout.
The Layout Process
The basic steps involved in the layout stage are listed below, though they may vary slightly depending on the browser (rendering engine):
1. The width of the parent render object is calculated by itself.
2. The render object for the parent goes over the children and:
a) Set the coordinates of the child render object (x, y).
b) If necessary, calls the layout function of the child render object, which calculates the child’s height.
3. The parent render object’s parent will utilize the accumulative heights of the children, as well as the heights of margins and padding, to set its own height.
4. Sets the dirty bit’s value to false.
CloudThat is the official AWS Advanced Consulting Partner, Microsoft Gold Partner, and Google Cloud Partner, helping people develop knowledge on the cloud and help their businesses aim for higher goals using best in industry cloud computing practices and expertise. We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Our blogs, webinars, case studies, and white papers enable all the stakeholders in the cloud computing sphere.
Feel free to drop a comment or any queries that you have regarding AWS services, Kubernetes Engine, or consulting requirements and we will get back to you quickly. To get started, go through our Expert Advisory page and Managed Services Package that is CloudThat’s offerings.
Finally, we’ve got the rendering engine up and running. Here are some crucial considerations to keep in mind:
It is a web component that renders a specific web page requested by the user on their screen. It interprets HTML and XML pages along with images formatted using CSS, and generates a final layout displayed on your user interface.
2. What is the difference between a rendering engine and a browser engine?
The rendering engine is used to display the requested content on the user interface and the browser engine marshals actions between the UI and the rendering engine.
|
Voiced by Amazon Polly |
Rahul works as a Senior Backend Developer at CloudThat, focused on building scalable systems using Java, Python, and Node.js. He works with AWS and Azure to deliver reliable backend solutions, emphasizing performance, clean architecture, and system reliability.
SHARE

AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AWS, Cloud Training
By Himisha Raval
Jul 14, 2026

AWS, DevOps
By Himisha Raval
Jul 14, 2026



Artificial Intelligence, Data science
By Himisha Raval
Jul 14, 2026

AI, Data Analytics
By Himisha Raval
Jul 14, 2026

Agentic AI, Prompt Engineering
By Himisha Raval
Jul 14, 2026
Our support doesn't end here. We have monthly newsletters, study guides, practice questions, and more to assist you in upgrading your cloud career. Subscribe to get them all!

Comments