

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Introduction
Generative AI is changing how companies use data, automate work, and personalize experiences. However, the success of any AI project depends less on the algorithm and more on the quality of the data behind it. Without strong data governance, even advanced AI systems can produce inaccurate, biased, or unreliable results.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Understanding Data Governance
Data governance refers to the policies, standards, and processes used to manage data across its lifecycle. It covers how data is created, stored, accessed, protected, maintained, and archived.
Key areas include data quality, ownership, security, compliance, metadata management, and data lineage. While governance was once mainly linked to analytics and regulation, it has become essential for Generative AI because AI systems depend on accurate, trusted, and well-managed data.
Why Generative AI Depends on High-Quality Data
Generative AI models respond based on the data and information that is fed into them. In an enterprise setting, AI models are connected to internal databases and other applications via the Retrieval-Augmented Generation (RAG) architecture. The quality of this connection is what determines the quality of the outputs generated by AI models.
Data quality issues can create real business risks. A customer support chatbot using outdated product data may give incorrect answers. An internal AI assistant connected to conflicting policy documents may confuse employees. In healthcare or finance, incomplete records or weak access controls can lead to wrong recommendations or exposure of sensitive information.
All these problems result from faulty connections between data and AI models. In essence, the AI itself is not flawed in each case. The poor quality of the data and its governance are at fault.
The Risks of Poor Data Governance in Generative AI
- Incorrect Outputs and Hallucinations
Poorly managed or untrusted data increases the chances of inaccurate AI responses.
- Security and Privacy Threats
Weak governance can allow AI systems to expose confidential business, customer, or financial data.
- Issues of Compliance and Regulatory Requirements
In regulated industries, poor governance can lead to unauthorized access, weak audit trails, and retention problems.
- Decreased Reliability of AI Tools
If AI tools produce inconsistent or incorrect answers, users quickly lose confidence in them.
Key Components of AI-Ready Data Governance
- Data Quality Management
Ensures data is accurate, complete, consistent, relevant, and timely.
- Metadata Management
Helps AI systems understand the source, purpose, ownership, and usage of data.
- Data Lineage
Tracks where data comes from, how it changes, and which systems influence it.
- Access Control and Security
Ensures AI retrieves only the data each user is authorized to access.
- Compliance Monitoring
Helps organizations track regulatory requirements, audits, and reporting needs.
Data Governance in Retrieval-Augmented Generation (RAG)
In many cases, RAG architecture powers Enterprise Generative AI products to deliver accurate responses. The RAG pipeline starts with a person entering a question, retrieving relevant data from enterprise knowledge stores, feeding it to the language model, and generating a response. This method depends significantly on proper data governance.
Improper governance will lead to duplicative documents, outdated information, inconsistent terminology, insufficient metadata, and unauthorized access. It leads to the AI obtaining irrelevant or even incorrect information, making its response inaccurate. Proper governance ensures that only trustworthy data can be obtained through the pipeline and that accurate responses are provided.
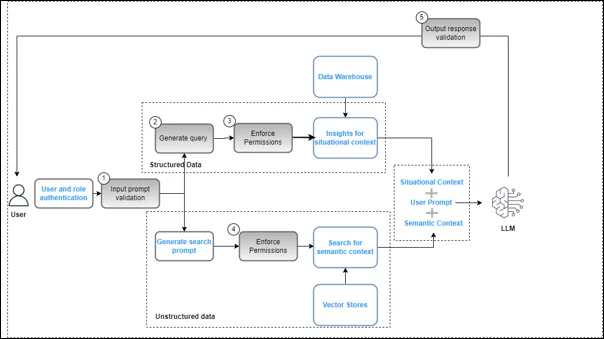
Data governance controls within a Generative AI and RAG workflow (Source: Data governance in the age of generative AI)
How Data Governance Improves AI Outcomes?
Organizations that invest in data governance experience measurable benefits across multiple dimensions:
- Improved Accuracy: High-quality data enables AI systems to generate more reliable and relevant responses, directly reducing costly errors and improving decision-making.
- Better Security: Governance frameworks prevent unauthorized access to sensitive information and establish clear permission hierarchies, reducing breach risk and protecting organizational assets.
- Increased Transparency: Data lineage and metadata management improve explainability and traceability, enabling organizations to understand how AI-generated outputs were derived and to identify and correct issues.
- Stronger Compliance: Governed data environments simplify regulatory compliance and audit readiness, reducing the burden of demonstrating adherence to industry standards and minimizing legal exposure.
- Greater User Confidence: Reliable, consistent outputs increase trust among employees, customers, and stakeholders, encouraging broader AI adoption and maximizing ROI on AI investments.
By treating data governance as a strategic priority, organizations can unlock the full potential of their Generative AI initiatives while mitigating risks.
Data Governance Practices for Generative AI Implementation
For successful and efficient implementations of Generative AI, businesses are recommended to use the following best practices:
- Identify roles and responsibilities for data governance.
- Create standards and guidelines for data quality, including validation processes.
- Maintain complete, up-to-date metadata/data catalogs to facilitate data management.
- Use role-based access control to restrict data access based on users’ permissions.
- Monitor the data lineage process to understand how datasets are transformed.
- Perform regular reviews of applicable compliance requirements.
- Ensure accuracy, consistency, and absence of bias in data provided by AIs.
- Purge old, duplicate, and personal information from the knowledge base.
- Enhance governance policies continuously due to changing circumstances by using Key AWS Services for Enabling Governance:
- Amazon Simple Storage Service (S3) – Scalable storage solution offering access control and lifecycle management capabilities for effective data management.
- AWS Lake Formation – Streamlined data lakes creation and governance through the implementation of central permissions management and strict access controls.
- AWS Glue Data Catalog – Automated metadata management for easier and faster data discovery, organization, and management.
- AWS Identity and Access Management (IAM) – Secure identification and authentication of users and applications, together with permissions management.
- Amazon Bedrock – The tool for building Generative AI applications with governance-enabled integration of enterprise data.
Conclusion
For Generative AI to succeed, there must be a lot more involved than simply choosing an appropriate model; good governance is needed. The most crucial aspect of any AI system is data.
Drop a query if you have any questions regarding GenAI, and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. What is data governance in Generative AI?
ANS: – Data governance refers to the policies, processes, and controls that ensure data accessed by AI systems is accurate, secure, compliant, and trustworthy.
2. Why is data quality important for Generative AI?
ANS: – Generative AI systems rely on data to generate responses. Poor-quality data leads to inaccurate, inconsistent, or misleading outputs, undermining user trust.
3. What AWS services can help implement data governance for AI?
ANS: – Services such as Amazon Simple Storage Service (S3), AWS Lake Formation, AWS Glue Data Catalog, AWS Identity and Access Management (IAM), and Amazon Bedrock help organizations implement effective data governance strategies for Generative AI applications.

WRITTEN BY Sujay Adityan
Sujay works as a Research Associate in the Data & AIoT team at CloudThat, with a background in Data Science. He is skilled in data analytics, machine learning, cloud computing, Python programming, and working with large-scale databases and networks. Sujay has contributed to multiple AI/ML and Generative AI projects for both internal teams and clients. Passionate about continuous learning, he aspires to become a proficient software developer, creating meaningful, technology-driven solutions that make a real impact.











Comments