

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Introduction
In evaluating a RAG model, assessing whether the output response is accurate is just one of many factors to consider. An effective evaluation approach should not only focus on measuring the relevance of the retrieved document, but also on how the ranker prioritized useful information and on the similarity of the output response to the answer. Metrics such as Answer Correctness will help determine the factual correctness and semantic equivalence of the output response. Meanwhile, Context Relevancy is used to assess the relevancy of the retrieved context to the input question of the user. On the other hand, Hit Rate checks whether a relevant document is among the top-k retrieved documents, while MRR assesses the ranking of the relevant document.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Metric 1: Answer Correctness
What It Measures
Answer Correctness evaluates how close the generated answer is to the ground truth answer. It combines both factual overlap and semantic similarity to provide an overall measure of answer quality.
Formulation
![]()
Where:
- F1 overlap measures the token-level similarity between the generated answer and the ground truth
- Semantic Similarity measures meaning-level similarity using embeddings
- w₁ and w₂ are weighting factors
Example
Ground Truth: “The boiling point of water is 100°C at standard atmospheric pressure.”
Generated Answer: “Water boils at 100 degrees Celsius under normal pressure conditions.”
Even though the wording is different, both sentences convey nearly the same meaning.
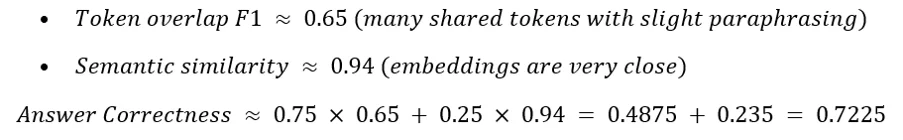
A higher score indicates the generated answer is both factually and semantically close to the correct answer.
Metric 2: Context Relevancy
What It Measures
Context Relevancy assesses the degree of relevance between the retrieved context and the question. Context Precision considers the relevancy of each chunk based on ground truth, while Context Relevancy assesses its relevancy to the question without any reference point.
Formulation
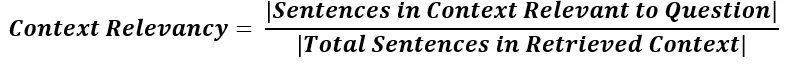
An LLM judges which sentences in the context are relevant to answering the given question.
Why This Matters
If your retriever pulls in long, multi-topic documents, a lot of the content is noise. High context relevancy means the retrieved passages are tightly focused, which generally leads to better generation because the LLM has less irrelevant content to navigate.
Metric 3: Hit Rate (Recall@k)
What It Measures
The Hit Rate measure tests if any relevant documents are present among the top k retrieved documents. This method is straightforward and quick for evaluating the efficiency of the retriever.
Formulation
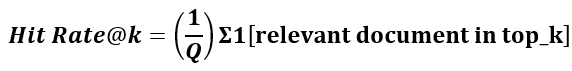
Where:
- Q = set of all questions in the evaluation set
- The indicator function equals 1 if at least one relevant document is in the top-k, 0 otherwise
Example: With , if 80 out of 100 questions had at least one relevant document in their top-5 results:
![]()
Hit Rate is a coarse but fast metric, useful for quick sanity checks on your retriever.
Metric 4: Mean Reciprocal Rank (MRR)
What It Measures
MRR is not just concerned with whether a document relevant to the query appears in the top-k positions, but also with its ranking within that range. A document relevant to the query that ranks #1 is far more useful than one that ranks #5.
Formulation
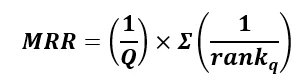
Where:
- the rank of the first relevant document retrieved for question q
- If no relevant document is found, the reciprocal rank for that query is 0
Example: For 3 questions, the first relevant document appears at ranks 1, 3, and 2:

Metric 5: Semantic Similarity (Embedding-Based)
What It Measures
Semantic Similarity refers to the degree of similarity between two texts in terms of meaning, despite differences in language. Embeddings are used instead of exact word matching. This metric is widely used in the assessment of Answer Correctness and Answer Relevancy.
Formulation
![]()
Where:
- embed(A) = embedding of generated answer
- embed (GT) = embedding of ground truth answer
Why Token Overlap Is Not Enough
Token overlap alone cannot accurately capture meaning.
Example
- Ground Truth: “The car is very fast.”
- Generated Answer: “The vehicle moves quickly.”
Even though the wording is different, both sentences convey nearly the same meaning. Semantic Similarity helps capture this meaning-level alignment.
RAGAS implementation
1. Import Required Libraries
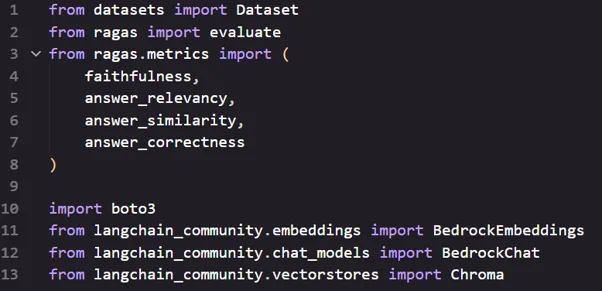
- Initialize Amazon Bedrock Client
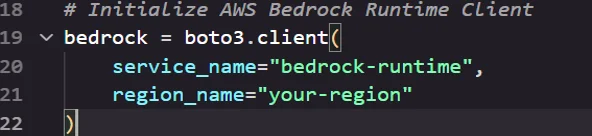
- Configure Embedding and LLM Models
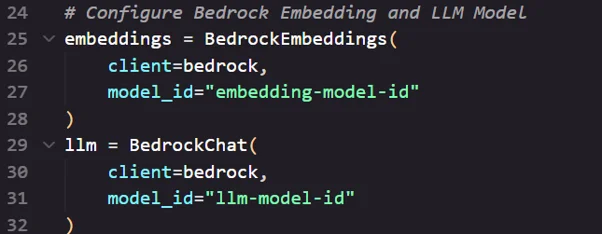
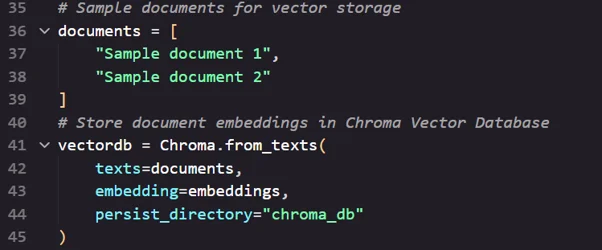
- Prepare and Store Documents in Vector Database
- Prepare Evaluation Dataset
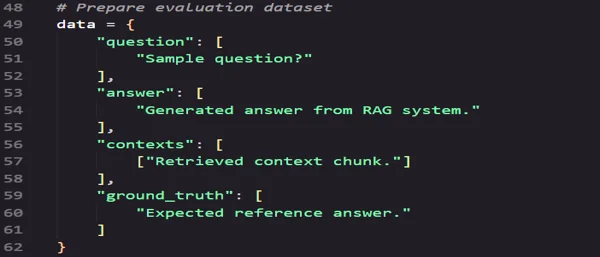
- Run RAGAS Evaluation
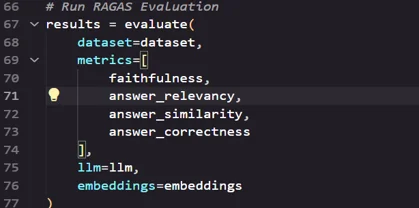
- Save and Analyze Results
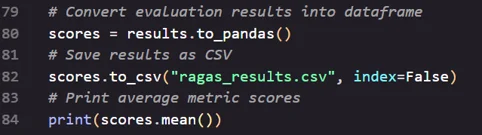
Conclusion
The improved evaluation techniques for RAG allow gaining a better understanding of the quality of the system, not only in terms of the correctness of retrieving data but also in regard to the correctness of the answer provided by the model.
Drop a query if you have any questions regarding RAG, and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. What is the purpose of answer correctness in RAG evaluation?
ANS: – The metric of Answer Correctness captures the resemblance between the generated answer and the ground truth answer using factual overlap and semantic similarity.
2. What is the importance of Context Relevancy in the RAG pipeline?
ANS: – The importance of Context Relevancy lies in helping determine whether the selected context is relevant to answering the user’s question.
3. What is the meaning of Hit Rate in retrieval metrics?
ANS: – This metric evaluates whether at least one relevant document exists among the top-k retrieved documents.

WRITTEN BY Aniket Bembale
Aniket Bembale is Senior Research Associate – Data & AIoT at CloudThat, focusing on Generative AI, Agentic AI solutions and Cloud Computing. He is involved in building scalable AI-driven applications and implementing modern data and AI technologies to solve real-world business challenges.











Comments