

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Overview
Modern applications such as search engines, recommendation systems, image retrieval platforms, and embedding-based NLP pipelines rely heavily on similarity search. Instead of exact matches, these systems aim to find items that are closest to a given query in a high-dimensional vector space.
At the core of similarity search are two foundational approaches:
- The brute-force k-nearest neighbors (kNN) method
- A more scalable approach using the Inverted File Index (IVF)
This blog explains both techniques, their trade-offs, and how they are used in real-world large-scale systems.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Challenges in Similarity Search at Scale
While similarity search is conceptually simple, scaling it to large datasets introduces several challenges:
- High Computational Cost
Comparing a query vector against millions or billions of vectors requires significant computation, especially when vector dimensions are high. - Latency Constraints
Real-time applications such as recommendation systems and search platforms demand results in milliseconds, which is difficult with naive approaches. - Memory and Storage Requirements
Storing large volumes of high-dimensional vectors can strain memory and storage systems. - Accuracy vs Performance Trade-off
Improving speed often requires approximation, which may reduce the accuracy of results.
k-Nearest Neighbours (kNN): Brute-Force Approach
What it is
The kNN approach is the most straightforward method for similarity search:
- Given:
- A dataset of N vectors with dimension D
- A query vector q
- Compute the distance (or similarity) between q and every vector
- Return the top k closest vectors
This results in a computational complexity of O(N × D) per query.
Advantages
- Exact Results
Always returns the true nearest neighbours without approximation - Simple Implementation
No need for indexing, clustering, or training - Reliable for Small Datasets
Works efficiently when the data size is manageable
Disadvantages
- Poor Scalability
Performance degrades significantly as the dataset size grows - High Latency
Not suitable for real-time systems with large datasets - Resource Intensive
Requires storing and scanning the full dataset
When to Use kNN
- Small datasets (up to a few hundred thousand vectors)
- Low-dimensional data
- Applications requiring 100% accuracy
- Offline or batch processing scenarios
Inverted File Index (IVF): Scalable Similarity Search
The Inverted File Index (IVF) improves scalability by partitioning the dataset into clusters and returning only a subset of data for each query.
Instead of scanning all vectors, IVF narrows the search space using clustering.
How it works?
The IVF method consists of three main stages:
- Training (Clustering)
- Apply clustering (e.g., k-means) to divide data into nlist clusters
- Each cluster is represented by a centroid
- Indexing
- Assign each vector to its nearest centroid
- Store vectors in corresponding cluster “lists”
- Querying
- Compute the distance between the query vector and all centroids
- Select the top nprobe clusters closest to the query
- Search only within those clusters
- Return the top k nearest vectors
This significantly reduces the number of comparisons.
Advantages
- Improved Speed and Scalability
Searches only a fraction of the dataset - Reduced Latency
Suitable for real-time applications - Flexible Accuracy
Adjust parameters (nlist, nprobe) to balance speed and recall - Industry Adoption
Widely used in libraries such as FAISS
Disadvantages
- Approximate Results
May miss true nearest neighbours - Parameter Tuning Required
Need to carefully choose:- Number of clusters (nlist)
- Number of clusters searched (nprobe)
- Training Overhead
Clustering step adds complexity - Cluster Imbalance Issues
Uneven distribution can affect performance
Practical Considerations and Best Practices
To effectively implement similarity search using IVF, consider the following:
- Tune nlist and nprobe
- Higher nlist → smaller clusters → faster search
- Higher nprobe → better accuracy
- Monitor Recall vs Latency
- Balance performance with result quality
- Use Optimized Libraries
- FAISS (e.g., IndexIVFFlat, IndexIVFPQ)
- Handle High Dimensions
- Consider dimensionality reduction techniques
- Ensure Balanced Clustering
- Avoid highly skewed cluster sizes
- Scale for Production
- Combine IVF with compression or hierarchical indexing
Comparison: kNN vs IVF
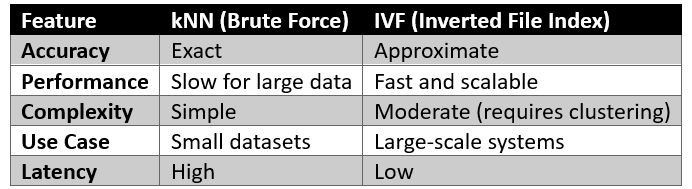
Figure: Comparison of kNN (brute-force) and IVF (scalable indexing) approaches for similarity search performance
When to Use Each Approach?
Use kNN when:
- The dataset is small
- Accuracy is critical
- Latency requirements are low
Use IVF when:
- The dataset is large (millions or more)
- Real-time performance is required
- Some approximation is acceptable
Conclusion
Similarity search is a critical component of modern data-driven applications. While the brute-force kNN approach provides exact results and simplicity, it does not scale well for large, high-dimensional datasets.
In real-world systems, IVF and its variants form the backbone of high-performance vector search architectures. Choosing the right approach depends on balancing dataset size, latency requirements, and acceptable accuracy levels.
Drop a query if you have any questions regarding kNN, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What does “nearest neighbour” mean in vector search?
ANS: – It refers to vectors that are closest to a query vector based on a similarity metric such as Euclidean distance or cosine similarity.
2. Why is brute-force kNN not always used?
ANS: – Its computational complexity (O(N × D)) becomes too expensive for large datasets and real-time applications.
3. What is the role of nlist and nprobe in IVF?
ANS: – nlist defines the number of clusters, while nprobe determines how many clusters are searched during a query.

WRITTEN BY Manjunath Raju S G
Manjunath Raju S G works as a Research Associate at CloudThat. He is passionate about exploring advanced technologies and emerging cloud services, with a strong focus on data analytics, machine learning, and cloud computing. In his free time, Manjunath enjoys learning new languages to expand his skill set and stays updated with the latest tech trends and innovations.











Comments