

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Overview
Dolphin is a state-of-the-art multimodal Document Image Parsing (DIP) model from ByteDance that establishes a new “analyse-then-parse” paradigm. By decoupling structural layout analysis from parallelized content recognition, Dolphin overcomes the efficiency bottlenecks of end-to-end autoregressive models and the cascading errors of traditional fragmented OCR pipelines. Dolphin-v2 (3B) achieves an SOTA Overall Score of 89.78 on OmniDocBench v1.5, delivering a 91% error reduction on photographed documents while maintaining superior inference speeds (0.1729 FPS) compared to general-purpose VLMs like GPT-4o.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
In the field of Document AI, Document Image Parsing (DIP) is notoriously more difficult than standard Optical Character Recognition (OCR). While OCR merely identifies character strings, true parsing requires a holistic understanding of a document’s visual semantics: mapping multi-column layouts, nested tables, complex LaTeX formulas, and hierarchical headers into a machine-readable structure. Historically, we have relied on “The Fragile Pipeline” – a stack of independent expert models for detection, layout analysis, and recognition.
Dolphin
Dolphin introduces a strategically decoupled architecture that follows an “analyze-then-parse” workflow. Central to this innovation is Heterogeneous Anchor Prompting, which acts as a “GPS for the model.” Instead of forcing the model to generate the entire document string in one pass, Dolphin uses Stage 1 to identify layout elements as “anchors.” In Stage 2, these anchors provide the model with a specific task-context (e.g., “this bounding box is a table”). By applying a task-specific “lens” to each anchor, Dolphin ensures high-fidelity extraction without the hallucinations or structural loss typical of standard VLMs.
Deep Dive: The Two-Stage Architecture
Stage 1: Page-Level Layout Analysis and Classification
Dolphin encodes the document image to identify layout elements in their natural reading order.
- Architectural Evolution: Dolphin-v1 (0.3B) utilized a Swin Transformer backbone. Dolphin-v2 (3B) upgrades to NaViT (Native Resolution Vision Transformer), enabling the model to process variable-length patch sequences at their native resolution. This avoids the information loss and text distortion inherent in fixed-size resizing.
- Reading Order & Optimization: The model generates a JSON-like sequence of elements (coordinates and types). To train this effectively, Dolphin utilizes a bipartite matching objective to align predicted layout elements with ground truth:
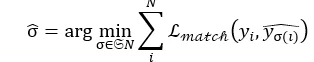
This stage is critical for downstream Retrieval-Augmented Generation (RAG), as it ensures that text from sidebars or multi-column reports is extracted in the correct semantic order.
Stage 2: Hybrid Content Parsing Strategy
Stage 2 utilizes the anchors from Stage 1 to perform content extraction. In Dolphin-v2, the model employs a Qwen2.5-VL-3B autoregressive decoder (upgraded from the mBart decoder in v1).
- Parallel Element-Wise Parsing (Digital): For clean, digital-born documents, Dolphin crops the element regions and parses them in parallel. This leverages multi-core GPU nodes for massive efficiency gains.
- Holistic Page-Level Parsing (Photographed): Dolphin-v2 introduces a specialized strategy for photographed documents. Because physical distortions (curls, folds, and skew) make axis-aligned bounding boxes unreliable, photographed pages are parsed holistically to allow the model to resolve geometric skew globally.
- Scalable Prompting: Dedicated prompts guide the parsing of distinct elements: P_table for HTML, P_formula for LaTeX, P_code for programming syntax, and P_paragraph for standard text.
Key Innovations: Finer-Grained Understanding
Dolphin-v2 expands the model’s capabilities to handle 21 distinct categories, providing a level of structural nuance that generic OCR systems cannot match:
- Hierarchical Structural Mapping: Includes tags for six levels of headings (sec_0-sec_5), enabling automated TOC generation.
- Complex Text Handling: Distinguishes between standard paragraphs (para) and column-broken text (half_para), while preserving elements like footnotes (fnote), watermarks, and hand-written annotations (anno).
- Code Block Integrity: Unlike most DIP models that strip whitespace, Dolphin is explicitly trained to preserve exact indentation – a prerequisite for turning document screenshots into executable code.
- Attribute Extraction: Beyond simple text, Dolphin-v2 can extract semantic metadata, such as author names or the parent-child relationship between a figure and its caption.
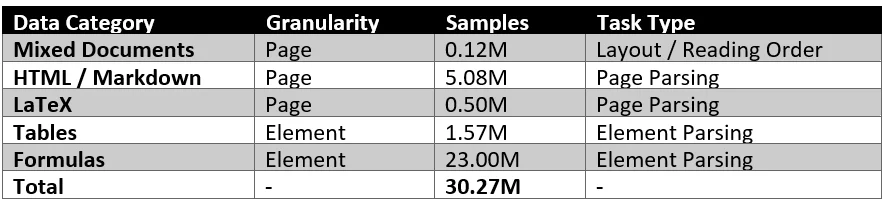
Training at Scale: The 30 Million Sample Advantage
Dolphin’s “element-decoupled” strategy provides a significant advantage in data collection. It is far easier to acquire millions of isolated formulas or tables than it is to find high-quality, fully annotated complex pages.
Performance Benchmarks: How Dolphin Leads
On the OmniDocBench v1.5 and FoxPage benchmarks, Dolphin-v2 (3B) sets a new standard for Document AI performance.
Competitive Audit
- Expert VLMs: Dolphin-v2 (3B) delivers a +14.78 overall score improvement over v1. It achieves an Edit Distance of just 0.054, significantly outperforming specialized models like Nougat and GOT.
- General VLMs: While models like GPT-4o and Claude 3.5 Sonnet have strong zero-shot capabilities, they struggle with dense document structures. Dolphin-v2 outperforms GPT-4o on OmniDocBench while maintaining a much higher FPS (0.1729 vs 0.0368).
- Photographed Robustness: Thanks to its holistic parsing strategy, Dolphin-v2 achieves a 91% error reduction on photographed documents compared to traditional element-cropping methods.
Why This Matters: Real-World Applications
- High-Fidelity RAG: By providing the correct reading order and preserving table hierarchies, Dolphin eliminates “garbage in” problems for LLM-based retrieval systems.
- Enterprise Automation: Dolphin’s robustness against perspective skew and shadows makes it viable for processing real-world, photographed business reports that typically break standard OCR.
- Scientific Digitization: The ability to convert complex scientific PDFs into “live” LaTeX and correctly indented code blocks allows researchers to index and interact with technical literature programmatically.
Key Takeaways for the Technical Architect
- Paradigm Shift: The analyze-then-parse model solves the “black box” efficiency problem by allowing for parallel element-wise decoding.
- Structural Precision: With 21 granular categories and attribute extraction, Dolphin understands document hierarchy (headings, captions, metadata) better than any general-purpose VLM.
- Physical Robustness: The NaViT-powered encoder and holistic parsing strategy effectively “solve” the geometric distortions and information loss common in photographed or scanned documents.
Dolphin represents a move toward Multimodal Foundation Models that treat document structure as a first-class citizen, enabling a future where AI agents can interact with the world’s “dead” PDF data with the same nuance as a human reader.
Drop a query if you have any questions regarding Dolphin, and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What is Dolphin?
ANS: – Dolphin is a multimodal Document Image Parsing (DIP) model developed by ByteDance that extracts and structures content from complex documents, including text, tables, formulas, code blocks, and images. It follows an innovative “analyze-then-parse” architecture to improve both accuracy and efficiency.
2. How is Dolphin different from traditional OCR?
ANS: – Traditional OCR focuses primarily on recognizing text characters, while Dolphin understands the entire document structure, including:
- Multi-column layouts
- Tables
- Mathematical formulas
- Code snippets
- Headers and sections
- Figures and captions
3. What is the "Analyze-then-Parse" paradigm?
ANS: – The “analyze-then-parse” approach separates document understanding into two stages: Stage 1: Analyze
- Detects document layout.
- Identifies document elements such as paragraphs, tables, formulas, and images.
- Extracts content from each identified element.
- Uses specialized prompts and parsing strategies for different content types.
- This separation improves accuracy while enabling parallel processing.

WRITTEN BY Abhishek Mishra
Abhishek Mishra works as an Associate Architect at CloudThat. He is a 4X AWS-certified professional, focusing on NLP and data science. Abhishek is pursuing a Master’s in Artificial Intelligence at IU International University of Applied Sciences. At AutomationEdge, he has worked on NLP models using BERT, GPT, and Rasa, and has contributed to computer vision projects with YOLO and TensorFlow. He is skilled in Python, Django, Streamlit, and PostgreSQL, and he builds data pipelines and tools.











Comments