

 Login
Login

 June 19, 2026
June 19, 2026|
Voiced by Amazon Polly |
Today, organizations generate huge amounts of data from applications, APIs, transactions, IoT devices, and customer systems. But there’s one major problem: raw data is rarely clean.
Some records may have missing values, invalid entries, suspicious transactions, or even sensitive customer information. If this bad data reaches analytics dashboards or AI models directly, the results can be inaccurate, misleading, and even risky for the business.
This is exactly why enterprises build automated data validation pipelines.
In this blog, we’ll build a smart, scalable AWS-based validation architecture using services such as Amazon S3, AWS Glue Data Quality, AWS Lambda, Amazon Comprehend, CloudWatch, SNS, and CloudTrail to ensure incoming data is reliable, compliant, and production-ready.
This demo architecture and validation workflow are also covered as part of the Advanced Generative AI Development on AWS program, where participants learn how to build real-world enterprise AI, data engineering, and scalable Generative AI solutions on AWS.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
Why Data Validation Is Important
Modern AI and analytics systems depend entirely on the quality of the data they receive.
Even the most powerful AI model can fail if the input data contains:
- Missing customer details
- Invalid age values
- Incorrect transaction amounts
- Duplicate records
- Sensitive PII information
This leads to a very important enterprise problem:
Bad Data – Bad Analytics – Bad AI
To avoid this, organizations validate data before it reaches downstream systems.
Solution Architecture
The architecture combines multiple AWS services, where each service handles a specific responsibility in the pipeline.
S3 (Raw Data) à Glue Data Quality à Lambda (Business Rules) à Comprehend (PII Detection)
CloudWatch (Monitoring) à SNS (Alerts) à CloudTrail (Audit)
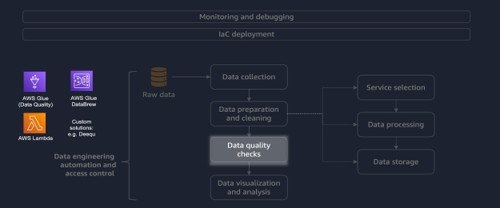
Source: Data quality checks – AWS Prescriptive Guidance
This architecture ensures that data is not only technically validated but also properly monitored, secured, and audited.
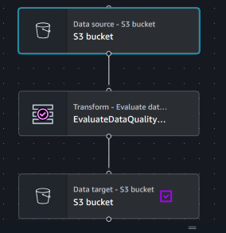
Fig 2: AWS pipeline validates and monitors data quality before storage.
Storing Raw Data in Amazon S3
The pipeline starts by uploading raw CSV files into Amazon S3, which acts as the centralized data lake.
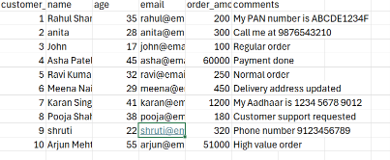
Fig 3: Raw data uploaded to Amazon S3 as the pipeline starting point.
The image above shows the csv dataset for the data quality evaluation job.
For this demo, the dataset intentionally contains:
- Invalid customer age
- High-value suspicious orders
- PAN and phone number information
The dataset is uploaded into an S3 bucket, and these will be the rules to evaluate the data:
, ColumnCount > 10
Rules = [
ColumnExists “customer_id”,
ColumnValues “age” between 18 and 80,
ColumnValues “order_amount” <= 50000
When we configure the data quality evaluation job with the above rules, it is configured and looks like the following:
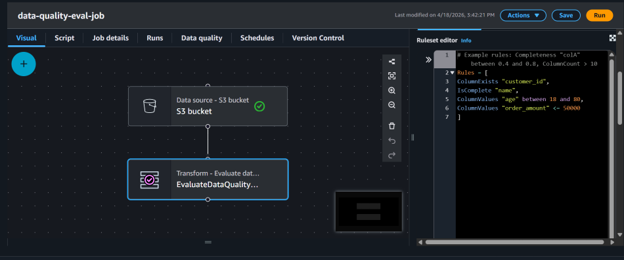
Fig 4: Configuring data quality rules in AWS Glue pipeline.
Discovering Schema and Validating Data
Once the file is uploaded, AWS Glue uses a Glue Crawler to scan the dataset and automatically discover the schema. This removes the need for manual schema creation.
After schema discovery, AWS Glue Data Quality validates the dataset against predefined quality rules.
Some sample validation checks include:

Fig 5: Data quality validation results highlighting failed rules in AWS Glue.
Glue identifies problematic records like:
- NULL customer names
- Underage customers
- Suspiciously high order values
It also generates a Data Quality Score that indicates how reliable the dataset is.
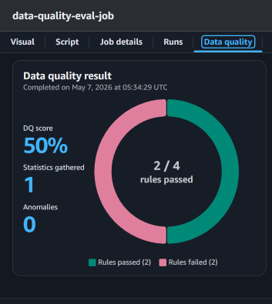
Fig 6: Data quality score highlights dataset reliability in AWS Glue.
This is extremely important because unreliable data should never be fed directly into analytics or AI systems.
“Glue helps organizations identify bad data before it creates bad business outcomes.”
Applying Business Rules Using AWS Lambda
Technical validation alone is not enough for enterprise systems. Organizations also need business-specific checks.
For example, suppose the company wants to reject any transaction above ₹50,000.
AWS Lambda can enforce this logic dynamically using serverless functions.
def lambda_handler(event, context):
order_amount = event[“order_amount”]
if order_amount > 50000:
return “Order rejected”
return “Order accepted”
If the input order amount is 60000, the response becomes:
Order rejected
This allows organizations to apply custom business policies in real time without managing servers.
Detecting Sensitive Information with Amazon Comprehend
Another major challenge in enterprise systems is securely handling sensitive customer information.
Amazon Comprehend helps detect Personally Identifiable Information (PII) such as:
- PAN numbers
- Phone numbers
- Email addresses
Using NLP capabilities, Comprehend automatically scans the dataset and identifies sensitive information.
This is especially useful for industries like banking, healthcare, insurance, and retail, where compliance requirements are critical.
Monitoring, Alerts, and Governance
Once the pipeline is running, monitoring becomes extremely important.
Amazon CloudWatch captures logs, execution details, and performance metrics across the workflow. If failures occur, Amazon SNS automatically sends alerts to the operations or data engineering teams.
At the governance level, AWS CloudTrail records important activities such as:
- RunJob
- InvokeFunction
- PutObject
This helps organizations maintain security, compliance, and audit visibility across the environment.
Building Trusted Data
As organizations increasingly adopt analytics, machine learning, and Generative AI, ensuring data quality has become more important than ever.
A reliable AI system can only be built on reliable data.
By combining Amazon S3, AWS Glue Data Quality, AWS Lambda, Amazon Comprehend, CloudWatch, SNS, and CloudTrail, organizations can build a complete validation framework that supports:
- Data quality validation
- Business rule enforcement
- PII detection
- Monitoring and alerting
- Governance and auditing
This serverless AWS architecture helps enterprises build scalable, secure, and trustworthy data pipelines for modern analytics and AI workloads.
“Enterprise pipelines are not just about processing data; they ensure data is clean, compliant, monitored, and trustworthy.”
And ultimately:
Bad Data leads to Bad Analytics, which in turn leads to Bad AI.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Priya Kanere
Priya Kanere is an AWS Subject Matter Expert and Champion AWS Authorized Instructor at CloudThat, specializing in cloud technologies, Python, data analytics, machine learning and generative AI. With extensive experience in training and mentoring, she has trained over 3,000 professionals to upskill in emerging technologies. Known for simplifying complex concepts through hands-on teaching and connecting theory with real-world applications, she brings deep technical knowledge and practical insights into every learning experience. Priya’s passion for empowering learners reflects in her unique approach to learning and development.










Comments