

 Login
Login

 January 29, 2026
January 29, 2026|
Voiced by Amazon Polly |
Overview
Amazon Bedrock now offers reinforcement fine-tuning (RFT), a new model customization capability that lets developers improve model accuracy using feedback rather than large, labelled datasets. RFT delivers an average accuracy gain of around 66% over base models, enabling smaller, cheaper models to perform like larger ones on your specific tasks. The capability is fully managed end-to-end in Amazon Bedrock, removing the need to build RL pipelines, orchestration, or custom training infrastructure. At launch, RFT is available for Amazon Nova 2 Lite, with support for additional models coming soon.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
Traditional fine-tuning requires teams to gather and tag large amounts of labelled, supervised data, a process that is time-consuming, costly, and hard to sustain in agile industries. Amazon Bedrock reinforcement learning for fine-tuning takes a different approach: models are trained based on rewards that indicate not only where they went wrong but also whether their responses are appropriate for the task at hand. Thus, the chasm between “good on benchmarks” and “good for my product” is bridged by advanced customization available to teams that lack expertise in ML algorithms. All operations stay within the regulated infrastructure of Amazon Bedrock.
How Reinforcement Fine-Tuning Works
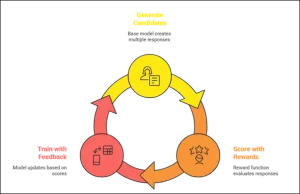
Key Benefits of Reinforcement Fine-Tuning
Reinforcement Fine-tuning in Amazon Bedrock aims to improve the power as well as viability for customization:
- Increased accuracy on smaller datasets
For instance, RFT is likely to achieve about a 66% improvement in accuracy over base models with a small number of prompts and feedback rather than large corpora. Therefore, this innovation enables rapid progress in domains where labelled datasets are either scarce or costly.
- Price-performance optimization
Since RFT increases task efficiency for models, you can use smaller, faster models such as Nova 2 Lite and still achieve the same, or even better, quality as the larger models on your task. This immediately benefits inference costs and latency.
- No MLOps heavy lifting
Amazon Bedrock handles the RL learning loop, checkpoints, scaling, and deployment. Developers are concerned only with specifying reward functions and writing prompts, not with GPU management, schedulers, or learning pipelines.
Two Reinforcement Approaches: RLVR and RLAIF
Amazon Bedrock offers two interconnected methods for model reinforcement so you can adjust the models for both objective and subjective tasks:
- Reinforcement Learning with Verifiable Rewards (RLVR)
RLVR employs rule-based graders that are deterministic checks written using AWS Lambda. It is appropriate for:
- Code generation (compilation, tests, linting).
- Math reasoning (accuracy of final numerical solutions).
- Structured results that can be verified programmatically.
- Reinforcement Learning from AI Feedback (RLAIF)
RLAIF employs AI judges that assess more subjective aspects, which regulations cannot readily quantify, such as:
- Helpfulness, politeness, and brand
- Following directions and the quality of conversation.
- Content moderation and safety alignment.
Amazon Bedrock also offers templates for common reward functions that you can start with, so you do not have to start from scratch to write an entire evaluator.
Typical Use Cases
Reinforcement fine-tuning becomes particularly useful in situations where just prompting the base model is not sufficient:
- Customer support assistants
Train your model to answer like your best agents, correctly, compassionately, on-brand, and policy-compliant, with rewards for correct responses and penalties for hallucinations and off-policy responses.
- CODE Generation and Review
Use RLVR with test suites and linter tools as graders, so the agent receives rewards for compilation, testing success, and adherence to team style guidelines.
- Domain-specific reasoning (finance, healthcare, legal)
Use both rule-based tests and AI-generated feedback to produce well-researched, conservative answers that satisfy regulatory requirements.
- Content and marketing creation
Reward by style, structure, and tone for outputs that are off topic or repetitive while focusing on a general model for a writing assistant that adopts awareness for brands.
Security, Privacy, and Governance
As the reinforcement fine-tuning process takes place only in the Amazon Bedrock environment, your sensitive data is not processed or transmitted outside the AWS-controlled environment. The training data and custom models are not used to enhance the publicly shared foundation models. This is to ensure your competitive advantage is maintained. RFT supports integration with VPC networking and AWS KMS encryption. This is to ensure the security alignment of the custom tasks. This is ideal for industries whose data cannot be transmitted to the training stacks.
Getting Started Workflow
At a high level, a typical RFT workflow in Amazon Bedrock looks like:
- Choose a Base model – Amazon Nova 2 Lite (Originally supported) or select another supported model.
- Prepare prompts – Collect a representative set of prompts from your real workloads (tickets, queries, tasks).
- Define reward functions – Start with a template from Amazon Bedrock and adapt rule-based or AI judge logic to your quality criteria.
- Create a fine-tuning job – Configure the job via Amazon Bedrock Console or API, attaching data in Amazon S3 or uploading it locally, and provide optional hyperparameters.
- Evaluate and deploy – Compare base vs. fine-tuned outputs in the Amazon Bedrock playground, then deploy the custom model into staging and production applications.
Because the RL pipeline is managed, it is a repeatable process that lets you refresh the model from time to time with new feedback as your product and policies evolve.
Conclusion
Reinforcement fine-tuning in Amazon Bedrock is a major step toward developing “truly customized” AI models. By learning from reward signals without requiring large amounts of labelled data, these models become smarter and better suited to your needs while remaining cost-effective.
With the combined strengths of the safety and evaluation features of the Amazon Bedrock platform, organizations can develop better-quality models with domain expertise and can perform well in real-world applications.
Drop a query if you have any questions regarding Reinforcement fine-tuning and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What are the differences between reinforcement fine-tuning and standard fine-tuning?
ANS: – Standard fine-tuning requires a lot of data in the form of labelled input-output pairs because it learns from them. For reinforcement fine-tuning, the model is trained on rewards that rate multiple possible responses, guiding it to understand what ‘better’ means.
2. Which models can support reinforcement fine-tuning?
ANS: – The models currently supported at launch for reinforcement fine-tuning run on Amazon Nova 2 Lite, though other foundation models will be added later. The supported model list is also available in the Amazon Bedrock documentation.
3. Do I need a large, labeled dataset to apply the RFT?
ANS: – No. One of the big pluses of RFTs is that they depend less on large, labelled datasets. The only requirement would essentially be to have a representative set of prompts to test, and to have tests scored by rules or AI judges.

WRITTEN BY Nekkanti Bindu
Nekkanti Bindu works as a Research Associate at CloudThat, where she channels her passion for cloud computing into meaningful work every day. Fascinated by the endless possibilities of the cloud, Bindu has established herself as an AWS consultant, helping organizations harness the full potential of AWS technologies. A firm believer in continuous learning, she stays at the forefront of industry trends and evolving cloud innovations. With a strong commitment to making a lasting impact, Bindu is driven to empower businesses to thrive in a cloud-first world.











Comments