

 Login
Login

 June 16, 2025
June 16, 2025|
Voiced by Amazon Polly |
Overview
Large Language Models (LLMs) have revolutionized natural language processing by producing human-like text in various applications. However, they usually suffer from a critical issue known as “hallucination,” where the model produces plausible responses that end up being factually incorrect or nonsensical. This has been a significant issue in sensitive areas like healthcare, finance, and law, where high accuracy is welcome. Amazon Web Services (AWS) has developed a solution based on a proven semantic cache using Amazon Bedrock Knowledge Bases to assist in reducing hallucinations by LLM agents.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Challenge of Hallucinations Is Like for LLMs
Hallucinations for LLMs happen when models generate facts beyond their training data or empirical facts. This happens when the question or the task asked to the LLMs is not present in their training dataset, so it starts to give an answer that is not factually correct. Even with innovations like Retrieval Augmented Generation (RAG), in which additional data is added to LLMs at inference time, hallucinations persist. RAG enhances response correctness via the inclusion of context. However, LLMs can still produce non-deterministic responses that fabricate false information even when the correct source material is present. Such indeterminism is hazardous, especially where correctness and reliability are crucially necessary in applications.
Introduction to the Verified Semantic Cache Solution
The AWS-recommended solution involves the deployment of an authentic semantic cache as an intermediate layer between the LLM agent and the user. The cache has curated and authentic question-answer pairs, with answers generated from correct and pre-authenticated facts. Amazon Bedrock Knowledge Bases Retrieve API integration enables rapid semantic search in the cache, allowing retrieval of meaningful information with high accuracy. This will help the LLMs to avoid generating the wrong or factually incorrect information.
Solution Architecture and Workflow
Solution architecture has been designed to optimize the response precision, reduce the latency, and reduce the operational expense. The below steps have been implemented in the workflow:
- User Query Submission: An individual asks, for example, “When is re:Invent happening this year?” The Invoke Agent function calls the query.
- Semantic Cache Search: Send Invoking Agent operation sends an inquiry to the semantic cache through the Amazon Bedrock Knowledge Bases Retrieve API. A semantic search is done to find a corresponding question in the cache.
3. Determining Response Path: Based on the level of similarity between the questions in the cache and the question posed by the user, the system follows one of two courses:
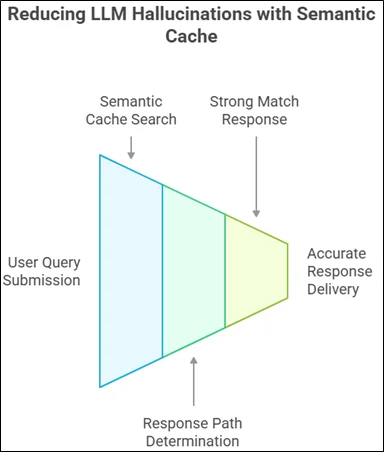
- Strong Match (Similarity Score > 80%): If a strong match exists, the Invoke Agent method provides the authenticated answer directly from the cache, providing a deterministic response without invoking the LLM. This allows for quick response, typically less than one second.
- Partial Match (60–80% Similarity Score): In the case of partial matches, the Invoke Agent action invokes the LLM agent and provides the cached answer as a few-shot example via Amazon Bedrock Agents promptSessionAttributes. This allows the LLM to generate more accurate answers, like the verified information.
Updating and Maintaining the Semantic Cache
The success of the semantic cache relies on regular updating and maintenance to maintain the data fresh and current. Authenticated question-answer pairs are stored in an Amazon Simple Storage Service (Amazon S3) bucket. The bucket is regularly updated with the Amazon Bedrock Knowledge Base in an offline batch update. The update keeps the semantic cache current with recent data without slowing real-time processing.
Benefits of the Verified Semantic Cache Solution
When such a solution is in place, numerous advantages include:
- Hallucination Reduction: Having an archive of approved data reduces the possibility of the LLM giving false or fictional responses.
- Improved Response Time: Quick retrieval of responses from the semantic cache enhances response time and, thus, user experience.
- Cost Saving: Refraining from redundant calls to the LLM saves computation costs, making the solution cost-effective.
- Enhanced Reliability: Given deterministic responses based on verified information improves the system’s reliability, which is particularly crucial for applications in sensitive areas.
Conclusion
The occasional user updating of the semantic cache also keeps the system current, hence making users access credible and up-to-date information.
Drop a query if you have any questions regarding Hallucinations and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. How does a verified semantic cache assist in reducing hallucinations in LLMs?
ANS: – A verified semantic cache stores pre-authenticated question-answer pairs, which are correct as a matter of fact. If the user queries with a question, the system will initially check in the cache for a semantically equivalent query. In the event of a good match, it returns the verified answer directly without passing through the LLM, preventing the risk of hallucinated answers.
2. If a user query lacks an exact match in cached entries?
ANS: – In the case of a partial match (60–80% similarity), the LLM is called but with a few-shot prompt via the cached response. This maintains the model near to verified information without lagging to create a dynamic response.

WRITTEN BY Akanksha Choudhary
Akanksha works as a Research Associate at CloudThat, specializing in data analysis and cloud-native solutions. She designs scalable data pipelines leveraging AWS services such as AWS Lambda, Amazon API Gateway, Amazon DynamoDB, and Amazon S3. She is skilled in Python and frontend technologies including React, HTML, CSS, and Tailwind CSS.











Comments