

 Login
Login

 January 14, 2026
January 14, 2026|
Voiced by Amazon Polly |
Introduction
In modern data warehousing, tracking how data changes over time is crucial for ensuring compliance, facilitating auditing, and supporting analytics. Slowly Changing Dimensions (SCD) Type 2 is a proven methodology that preserves complete historical records while maintaining current data states. This blog examines the implementation of SCD Type 2 using AWS Glue, in conjunction with Delta Lake, to develop a solution for managing dimensional data changes in cloud-based architectures.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Understanding Slowly Changing Dimensions (SCD)
Slowly Changing Dimensions address how dimensional attributes evolve over time in data warehouses. SCD Type 2 maintains full historical records by creating a new row each time a dimension attribute changes.
Key Components of SCD Type 2:
- Surrogate Keys: Unique identifiers for each record version
- Natural Keys: Business identifiers that remain constant
- Effective Date: When the record became active
- End Date: When the record was superseded
- Current Flag: Boolean indicating the active version
Use Cases and Benefits
SCD Type 2 is valuable for:
- Customer Management: Tracking address or contact changes
- Product Catalogs: Monitoring price or category updates
- Employee Records: Maintaining salary history or role changes
- Compliance: Preserving audit trails for regulatory requirements
Benefits include complete historical accuracy, point-in-time reporting, and comprehensive audit trails supporting both analytical and compliance needs.
Overview of AWS Glue and Delta Lake
AWS Glue: Serverless ETL
AWS Glue is a fully managed ETL service that simplifies data preparation. Key features include a serverless architecture, Apache Spark foundation for distributed processing, an integrated data catalog, and cost efficiency through pay-per-use pricing.
Delta Lake: ACID for Data Lakes
Delta Lake brings reliability to data lakes through:
- ACID Transactions: Ensures data consistency
- Time Travel: Access historical data versions
- Schema Evolution: Flexible schema management
- Unified Processing: Single architecture for batch and streaming
- Scalable Metadata: Efficient large-scale dataset management
Why Delta Lake for SCD Type 2?
Delta Lake’s MERGE operation provides native upsert support, ideal for SCD implementations. Combined with ACID guarantees and time travel capabilities, it creates a perfect foundation for managing slowly changing dimensions at scale.
Implementing SCD Type 2 Using AWS Glue with Delta Lake
Architecture Overview
The implementation utilizes AWS Glue jobs that perform SCD Type 2 logic with Delta Lake’s MERGE capabilities, storing versioned records in Amazon S3.
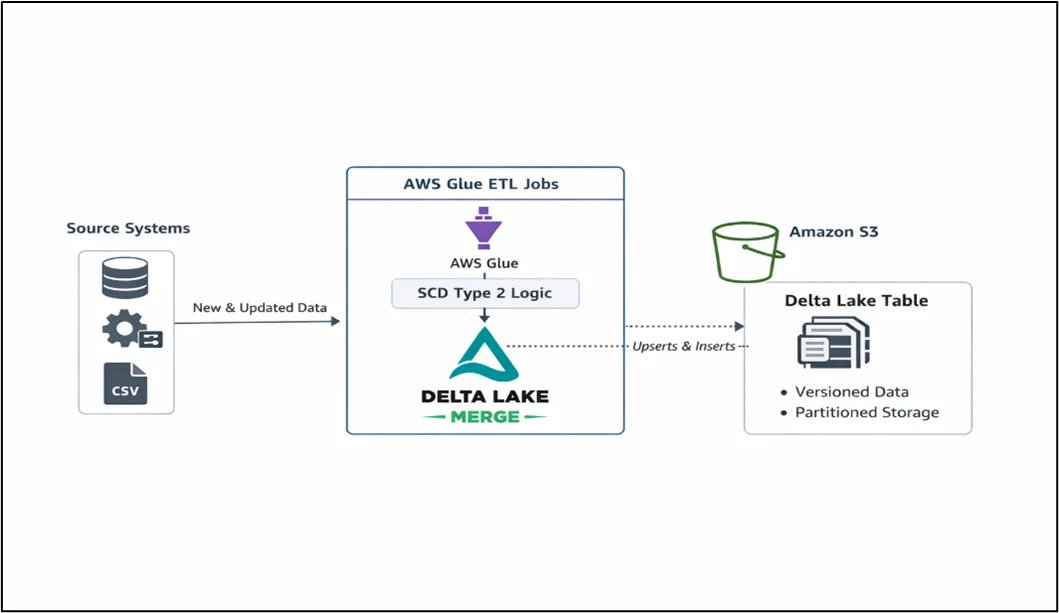
Step-by-Step Guide
Step 1: Schema Design
|
1 2 3 4 5 6 7 8 9 10 |
from pyspark.sql.types import * scd_schema = StructType([ StructField("surrogate_key", IntegerType(), False), StructField("customer_id", StringType(), False), StructField("customer_name", StringType(), True), StructField("email", StringType(), True), StructField("effective_date", TimestampType(), False), StructField("end_date", TimestampType(), True), StructField("is_current", BooleanType(), False) ]) |
Step 2: Core SCD Type 2 Logic
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
from delta.tables import DeltaTable from pyspark.sql.functions import current_timestamp, lit delta_table = DeltaTable.forPath(spark, "s3://bucket/delta/customer/") delta_table.alias("target").merge( source_df.alias("source"), "target.customer_id = source.customer_id AND target.is_current = true" ).whenMatchedUpdate( condition="target.customer_name != source.customer_name OR target.email != source.email", set={"is_current": lit(False), "end_date": current_timestamp()} ).whenNotMatchedInsert( values={ "customer_id": "source.customer_id", "customer_name": "source.customer_name", "effective_date": current_timestamp(), "is_current": lit(True) } ).execute() |
Step 3: AWS Glue Configuration
Configure AWS Glue job with Delta Lake support:
- Glue Version: 3.0+
- Job Parameters:
- –datalake-formats: delta
- –conf: spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension
Step 4: Time Travel Queries
|
1 2 3 4 |
# Query historical data historical_df = spark.read.format("delta")\ .option("timestampAsOf", "2024-01-01")\ .load("s3://bucket/delta/customer/") |
Best Practices and Common Challenges
Performance Considerations
- Partitioning: Partition by the is_current flag for optimized queries
- Z-Ordering: Use OPTIMIZE and ZORDER on frequently queried columns
- Compaction: Regularly compact small files
Data Consistency
- Idempotency: Design rerunnable jobs without duplicates
- ACID Transactions: Leverage Delta Lake for concurrent operations
- Validation: Implement quality checks before and after operations
- Key Management: Use monotonically increasing IDs or UUIDs
Cost and Scalability
- Incremental Processing: Process only changed records
- Lifecycle Policies: Archive old Delta log files
- Auto Scaling: Configure workers based on data volume
- Monitoring: Track performance with Amazon CloudWatch
Common Challenges
- Surrogate Key Generation: Use windowing functions for distributed key generation
- Late Arriving Data: Handle out-of-sequence records
- Schema Evolution: Plan for changes using Delta Lake features
- Testing: Create comprehensive test cases
Conclusion
Implementing SCD Type 2 using AWS Glue and Delta Lake offers a powerful and scalable solution for managing historical dimensional data. The combination of serverless ETL capabilities with ACID transactions creates a framework for tracking data changes over time.
Drop a query if you have any questions regarding SCD and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What's the difference between SCD Type 1, Type 2, and Type 3?
ANS: – Type 1 overwrites data, Type 2 preserves the full history, and Type 3 keeps a limited history. Type 2 is best for tracking changes.
2. Can AWS Glue handle large-scale SCD Type 2 implementations?
ANS: – Yes, Glue’s Spark engine with Delta Lake MERGE handles large-scale historical data efficiently.
3. How does Delta Lake improve upon traditional SCD implementations?
ANS: – Delta Lake adds ACID transactions, MERGE support, and time travel, unlike plain S3-based SCDs.

WRITTEN BY Anusha
Anusha works as a Subject Matter Expert at CloudThat. She handles AWS-based data engineering tasks such as building data pipelines, automating workflows, and creating dashboards. She focuses on developing efficient and reliable cloud solutions.











Comments