

 Login
Login

 September 4, 2025
September 4, 2025|
Voiced by Amazon Polly |
Introduction
Nowadays, businesses deal with an increasing number of documents that provide important business data. Traditional manual processing is often slow, error-prone, and resource-intensive, creating bottlenecks across insurance, healthcare, financial services, public sector, and child support industries. Intelligent Document Processing (IDP), powered by advanced machine learning (ML) and natural language processing (NLP), helps overcome these challenges by automating the extraction, analysis, and interpretation of both structured and unstructured data. With the addition of generative AI, IDP solutions become even more powerful, enabling greater adaptability to diverse document types, improved classification, and enhanced data accuracy. In this blog, we explore how Amazon Bedrock, combined with its Data Automation capabilities, empowers organizations to build scalable, efficient, and intelligent document workflows, driving productivity, reducing operational costs, and improving decision-making.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Amazon Bedrock Data Automation Advantages
- Amazon Bedrock Data Automation provides bounding box data and confidence scores, which improve the explainability and transparency of data. These features allow you to evaluate the accuracy of the information that has been retrieved, which leads to better decision-making. Low confidence scores, for example, may indicate that some data fields require more human review or verification.
- Rapid development blueprints: Amazon Bedrock Data Automation offers pre-made blueprints that make it easier to create document processing pipelines, enabling you to create and implement solutions more rapidly. Amazon Bedrock Data Automation offers flexible output options for various document processing needs. You may utilize predefined blueprints from our library as a starting point or start from scratch to create a bespoke extraction schema for customized output. You may alter your blueprint according to your unique document types and business needs for more precise and focused information retrieval.
- Support for automatic classification: Amazon Bedrock Data Automation precisely classifies documents by separating and matching them to the relevant blueprints. By eliminating the need for manual document sorting, this intelligent routing significantly lowers the amount of human interaction and speeds up processing.
- Normalization: By handling both value normalization (converting extracted data into consistent formats, units, and data types) and key normalization (mapping various field labels to standardized names), Amazon Bedrock Data Automation tackles a common IDP challenge. Organizations may automatically convert raw document extractions into standardized data that more easily fits with their current systems and processes by using this normalization technique, which helps to simplify data processing.
- Transformation: By automatically separating mixed data (such as names or addresses) into distinct, relevant components, the Amazon Bedrock Data Automation transformation tool turns complicated document fields into organized, business-ready data. By assisting teams in creating unique data types and field connections that complement their current database schemas and business applications, this feature streamlines how businesses manage a variety of document formats.
- Validation: By employing automatic validation rules for extracted data, which support date formats, string patterns, numeric ranges, and cross-field checks, Amazon Bedrock Data Automation improves the accuracy of document processing. To ensure that extracted information satisfies certain business rules and compliance requirements before entering downstream systems, this validation framework assists businesses in automatically identifying data quality concerns and initiating human reviews as necessary.
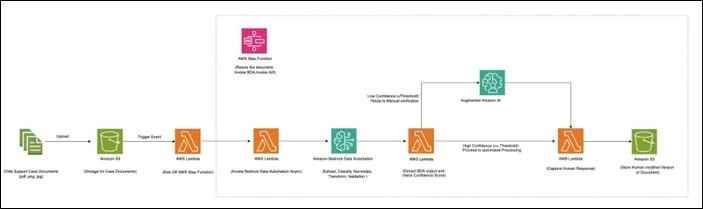
Automated Classification
As seen in the picture below, we specify the document class name for every custom blueprint generated in our implementation. The system automatically applies the relevant blueprint based on content analysis while processing numerous documents, such as driver’s licenses and child support enrollment forms, ensuring the right extraction logic is used for each document type.

Data Normalization
To ensure that downstream systems consistently get data, we employ data normalization. We employ implicit extractions (for information that requires transformation) and explicit extractions (for information that is explicitly expressed and apparent in the document).
Social Security numbers are now formatted as XXX-XX-XXXX.
Data Transformation
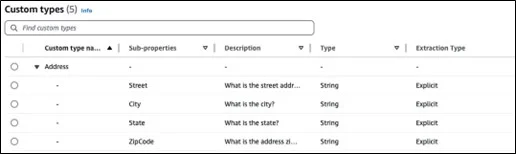
We have put in place bespoke data transformations for the child support enrollment application to match retrieved data with specifications. For instance, single-line addresses may be broken down into structured fields (Street, City, State, ZipCode) using our own data type for addresses. Consistent formatting and simple connection with current systems are achieved by reusing these structured fields across the registration form’s several address fields (employer address, home address, and other parent address).
Data Validation
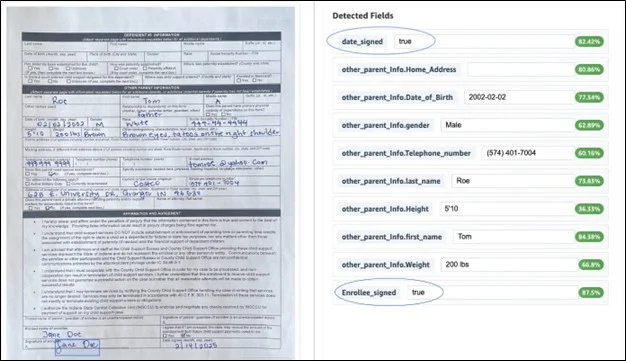
Validation rules are part of our implementation to ensure data compliance and correctness. Two validations have been put in place for our sample use case: to ensure that the enrollee’s signature is there and that the date they signed is not in the future.
The outcome of applying the validation rules to the document is displayed in the following snapshot.
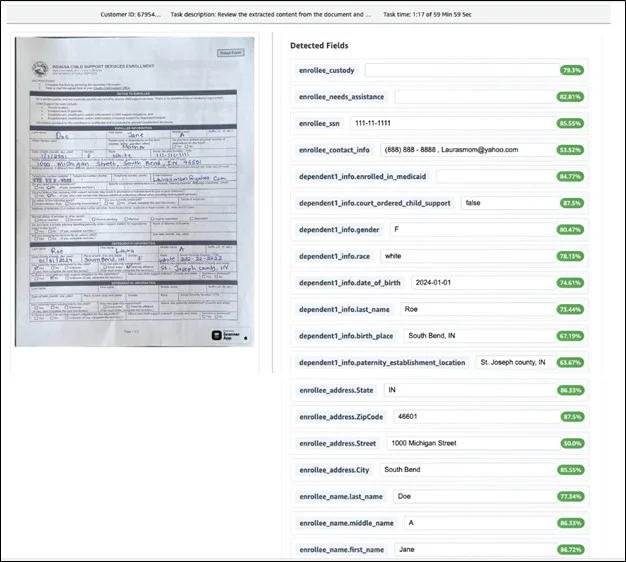
Human-in-the-loop validation
The extraction procedure, which incorporates a human-in-the-loop procedure and includes a confidence score, is depicted in the following screenshot. Additionally, it displays the date of birth in a normalized format.
Conclusion
This post showed how to utilize its sophisticated data transformation, validation, and normalization features. Organizations may enhance data quality, reduce development time, and create more reliable, scalable IDP solutions that work with human review procedures by switching to Amazon Bedrock Data Automation.
Drop a query if you have any questions regarding Amazon Bedrock Data Automation and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. How does Amazon Bedrock Data Automation enhance IDP?
ANS: – It adds features like confidence scores, classification, normalization, transformation, and validation to improve accuracy and reduce manual effort.
2. Can it process multiple document types automatically?
ANS: – Yes, it uses automatic classification to route documents to the right blueprint without manual sorting.
3. What business benefits does Amazon Bedrock Data Automation provide?
ANS: – It improves data quality, speeds up document processing, lowers costs, and boosts workflow efficiency.

WRITTEN BY Aayushi Khandelwal
Aayushi is a data and AIoT professional at CloudThat, specializing in generative AI technologies. She is passionate about building intelligent, data-driven solutions powered by advanced AI models. With a strong foundation in machine learning, natural language processing, and cloud services, Aayushi focuses on developing scalable systems that deliver meaningful insights and automation. Her expertise includes working with tools like Amazon Bedrock, AWS Lambda, and various open-source AI frameworks.











Comments