

 Login
Login

 December 2, 2025
December 2, 2025|
Voiced by Amazon Polly |
Overview
Amazon Web Services (AWS) has introduced a new feature within Amazon Bedrock, the Tokenizer. This tool enables users to estimate the number of tokens in their input text before sending it to a foundation model, such as Claude Sonnet, Claude Haiku, or Amazon Titan. Since token usage directly impacts both cost and quota, this release is a significant upgrade for developers, solution architects, and data teams working on Generative AI workloads. The Tokenizer helps ensure prompt optimization, predictable billing, and improved performance across AI applications, all without requiring third-party tools.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
In Generative AI, every piece of text, whether input or output, is broken down into smaller fragments known as tokens. Models like Claude, Titan, or Command process data in these tokenized units. When you send a request to a model on Amazon Bedrock, you’re billed based on the number of tokens processed both for input and output.
Until now, estimating how many tokens your prompt would consume required either external APIs or manual guesswork. With the new Tokenizer feature, AWS now enables you to:
- Accurately calculate tokens before model inference,
- Control costs with precision, and
- Optimize your GenAI prompts directly inside the Amazon Bedrock Console.
This feature is part of the Test section in Amazon Bedrock, joining existing tools like the Chat/Text playground and Image/Video playground.
It’s designed to make developers’ lives easier by offering visibility into how text translates into tokens, the key metric behind both cost and efficiency.
Explanation
When you open the Tokenizer section in the Amazon Bedrock Console, you’ll see three main panels:
- Model Selection
Choose a foundation model such as Claude Sonnet v1. Each model uses a slightly different tokenization approach, so the same sentence may produce different token counts depending on the model you select.
- Input Section
Here, you can type or paste your prompt.
For instance:
“The quick brown fox jumps over the lazy dog”
This is a standard test sentence, and when you click ‘Count tokens,’ the system instantly calculates how many tokens this input uses.
- Token Result
On the right-hand panel, Amazon Bedrock displays the result.
In this example, the sentence consumes 17 tokens when processed with Claude Sonnet v1.
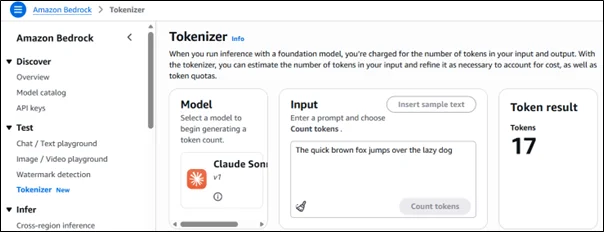
That’s it, in just a few clicks, you can see exactly how your text translates into tokens before you ever run a model query.
This visibility helps you fine-tune prompts, estimate costs, and stay within model quotas.
Key Features and Benefits
The Tokenizer may look simple, but it offers several important advantages for anyone building or maintaining Generative AI systems.
- Accurate Cost Estimation
Every foundation model on Amazon Bedrock charges per 1,000 tokens (for both input and output).
Knowing your token count upfront means you can forecast your costs with precision before running large workloads.
Example:
If the model rate is $0.003 per 1,000 tokens and your prompt is 2,000 tokens long, you’ll pay around $0.006 per inference for the input alone.
The Tokenizer helps you estimate this instantly.
- Prompt Optimization
Long prompts can lead to:
- Higher costs,
- Longer latency, and
- Context window overflow.
Using the Tokenizer, you can test shorter, more efficient prompts that still maintain context but consume fewer tokens. This is invaluable for prompt engineers and AI architects fine-tuning performance.
- Quota Management
Models have token limits for each request. By counting tokens in advance, you avoid exceeding these limits, preventing failed inferences or throttling.
This makes it easier to design prompts that fit within model constraints.
- Transparent Billing
For organizations running multiple projects or clients within the same AWS account, token visibility enables:
- Department-wise cost tracking,
- Usage-based internal billing, and
- Better financial governance for AI workloads.
- Integration Possibility
While the console tool is perfect for manual exploration, AWS SDKs and APIs can be used to integrate token counting into automated pipelines. Developers can calculate tokens programmatically before sending them to Amazon Bedrock, enabling real-time cost tracking via Amazon CloudWatch or AWS Cost Explorer.
Conclusion
The new Amazon Bedrock Tokenizer is a small yet impactful addition to the AWS AI toolkit. In Generative AI, where every token counts, literally understanding token usage is essential for both cost control and model efficiency. By offering token estimation directly inside the Amazon Bedrock Console, AWS empowers developers, architects, and prompt engineers to:
- Build smarter prompts,
- Forecast expenses accurately, and
- Deliver optimized user experiences.
This feature eliminates guesswork and improves operational clarity for teams deploying foundation models at scale.
Drop a query if you have any questions regarding Amazon Bedrock and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What exactly is a “token” in Amazon Bedrock?
ANS: – A token is a piece of text (like a word, part of a word, or punctuation) that a foundation model processes.
2. Can I use the Tokenizer outside the AWS Console?
ANS: – Currently, the Tokenizer is available in the Amazon Bedrock Console under the Test section.
However, developers can integrate similar logic using AWS SDKs and model-specific tokenization libraries to automate the token estimation process.
3. In which regions is this feature available?
ANS: – It is currently available in Mumbai, N.Virginia, Ohio, and more. For more information, please refer to the AWS documentation.

WRITTEN BY Yerraballi Suresh Kumar Reddy
Suresh is a highly skilled and results-driven Generative AI Engineer with over three years of experience and a proven track record in architecting, developing, and deploying end-to-end LLM-powered applications. His expertise covers the full project lifecycle, from foundational research and model fine-tuning to building scalable, production-grade RAG pipelines and enterprise-level GenAI platforms. Adept at leveraging state-of-the-art models, frameworks, and cloud technologies, Suresh specializes in creating innovative solutions to address complex business challenges.











Comments