

 Login
Login

 June 26, 2026
June 26, 2026|
Voiced by Amazon Polly |
Introduction
Quick Answer: An LLM course for developers covers how large language models work, how to use them via APIs, how to fine-tune them for specific tasks, and how to deploy them reliably. Most good courses include transformer architecture basics, prompt engineering, RAG pipelines, agent frameworks, and inference optimization. If you already write code, expect 3 to 6 months of focused learning before you can ship a production-grade AI feature with confidence. The demand for engineers who can actually build with LLMs, not just prompt them, has significantly outpaced supply, according to the LinkedIn 2024 Jobs on the Rise report.
Most developers who search for an LLM course already know they need one.
What they do not know is what a good one actually looks like. Because the range is massive. You have GitHub repos that dump 200 links at you. You have Udemy courses that teach you how to make a chatbot in 2 hours. And you have rigorous, structured programs that take you from transformers to production deployment and actually prepare you to work on real AI systems.
This blog is about the third kind. What skills you need, what projects matter, and which tools you should be learning if you want to build AI applications that hold up in the real world.
No Job After Graduation? Cloud Engineering is Your Answer
- Beginner Friendly
- 92% Placement Rate
- Live Instructor-Led
What an LLM Actually Is (and Why Developers Often Get It Wrong)
An LLM is a transformer-based neural network trained on massive amounts of text data to predict the next token in a sequence.
That is it.
But developers often treat it like a magic black box. Feed it a prompt, get an output, ship it. That works fine for demos. It breaks down badly in production.
Understanding what is actually happening inside the model matters the moment you need to:
- Control output format reliably
- Reduce hallucinations
- Tune the model for a specific domain
- Handle edge cases in user input
- Optimize inference costs at scale
There are four broad categories of LLMs worth knowing:
- Base models (pre-trained, no instruction tuning) like GPT-3 base and LLaMA 3.1
- Instruction-tuned models (fine-tuned on task data) like GPT-4, Claude 3, and Gemini
- RLHF-aligned models (further trained with human feedback for safety and helpfulness)
- Domain-specific models (fine-tuned for medicine, law, or code)
Knowing the difference shapes every decision you make, from which model to use to how to structure your prompts to whether fine-tuning even makes sense for your use case.
According to Google’s official introduction to LLMs, understanding the statistical nature of language models is foundational before you try to apply them in production systems.

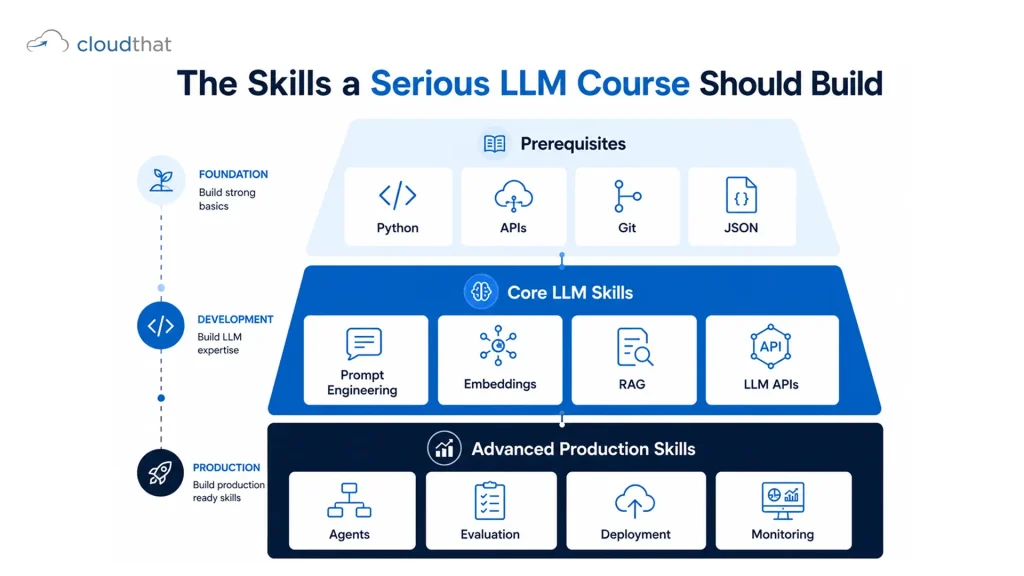
The Skills a Serious LLM Course Should Build
Not all skills weigh equally. Some are prerequisites. Some are core. Some come later.
Prerequisites (Before You Touch an LLM)
You do not need a PhD. But you do need:
- Python, comfortable with classes, async, file I/O, and virtual environments
- Linear algebra basics, enough to understand embeddings and attention
- A working mental model of neural networks, what a forward pass is and what loss means
If you are shaky on any of these, sort them first. An LLM course will not slow down to explain what a vector is.
Core LLM Skills
These are non-negotiable for anyone claiming to work with LLMs professionally:
- Transformer architecture: how attention works, what keys, queries, and values are
- Tokenization: why it matters and how models like GPT-4 handle text vs. numbers vs. code
- Prompt engineering: system prompts, few-shot examples, chain-of-thought
- RAG (Retrieval Augmented Generation): connecting LLMs to external knowledge bases with vector search
- Fine-tuning basics: when to fine-tune vs. when to use RAG, supervised fine-tuning, LoRA
- Evaluation: how to measure whether your LLM system is actually working
- Inference optimization: quantization, batching, latency vs. throughput tradeoffs
Advanced Skills (For Production Engineers)
- Agent frameworks: LangChain, LlamaIndex, OpenAI Agents SDK, Google ADK
- LLMOps: monitoring, observability, versioning, and A/B testing LLM outputs
- Security: prompt injection, jailbreaks, the OWASP LLM Top 10
- Deployment: containerizing models, serving with FastAPI or vLLM, managing GPU costs
Tools You Will Actually Use on the Job
The LLM tooling ecosystem moves fast. But the core stack has stabilized enough that knowing these well covers most production scenarios.
For working with models:
- Hugging Face Transformers, the standard library for loading and running open-source models
- LM Studio, for running models locally during development
- Ollama, for local LLM serving with a clean API
For building pipelines:
- LangChain is the most widely used framework for chaining LLM calls
- LlamaIndex, strong for document-heavy RAG applications
- DSPy, if you want to move beyond manual prompt engineering
For vector storage:
- Pinecone, Weaviate, or Chroma, depending on scale and cloud preference
For AWS-based LLM work specifically:
- Amazon Bedrock managed access to foundation models like Claude, Llama, and Titan
- Amazon SageMaker, for fine-tuning and deploying custom models
- AWS Lambda and API Gateway, for serverless LLM application backends
Knowing Bedrock matters especially if your work is AWS-oriented. CloudThat’s Generative AI with AWS consulting practice runs real production deployments on Bedrock, which means the engineers teaching these skills have shipped actual systems on the platform, not just run sandbox experiments.
The Projects That Separate Learners from Practitioners
Reading about RAG is easy. Building a RAG pipeline that handles 10,000 documents, returns consistent outputs, and degrades gracefully when the retrieval fails is where the skill actually lives.
Good LLM course projects are not just “build a chatbot.” They force you to solve real engineering problems:
- Document Q&A system: ingest PDFs, chunk them, embed them, store in a vector DB, query with context window management
- LLM-powered API: wrap a model in FastAPI, handle rate limits, log inputs and outputs, monitor for drift
- Fine-tuning a base model: take an open-source model, prepare a dataset, run supervised fine-tuning with LoRA, evaluate the result
- Multi-agent system: build agents that use tools (web search, code execution, database queries) and hand off tasks to each other
- Evaluation harness: build something that tests your LLM system against a set of golden examples automatically
If you are doing an LLM course and there are no projects in this territory, the course is preparing you for demos, not for work.
How Long Does LLM Training Actually Take?
Honest answer: longer than most courses claim.
If you already code well and have some ML background:
- Getting to “can build and deploy a working LLM feature”: 2 to 3 months of consistent effort
- Getting to “confident with fine-tuning and production LLMOps”: 4 to 6 months
- Getting to “AWS GenAI Engineer level with Bedrock, SageMaker, and agent workflows”: 5 to 8 months
The gap between “I finished the course” and “I can work on this in a team” is real. It closes faster when your course includes supervised hands-on labs where someone who has actually deployed these systems can course-correct you.
That is why the difference between a self-paced video library and an instructor-led LLM training program matters. Not because the video is bad. Because the hard parts of LLM engineering happen in the doing, not the watching.

Why CloudThat Is the Right Choice for Your LLM Training
Developers searching for a serious LLM course are not looking for another YouTube playlist. They need structured, practitioner-led training that bridges the gap between understanding LLMs and actually deploying them on cloud infrastructure.
CloudThat’s Generative AI with AWS training programs are built by the same engineers who run production GenAI engagements for enterprise clients. The curriculum covers Bedrock, SageMaker, RAG architectures, agent frameworks, and LLMOps, with 50 to 60% of time spent in hands-on labs, not slides.
The AWS GenAI Engineer program takes developers from LLM fundamentals through to production deployment on AWS, with labs on Bedrock agents, SageMaker fine-tuning, and real-world evaluation workflows. CloudThat holds the AWS GenAI competency, which means the instructors have demonstrated real expertise in this area, not just teaching credentials.
For teams looking to upskill engineers at scale, CloudThat’s corporate AI/ML training practice uses the Capability Development Framework to assess skills first, customize content by role, and validate project readiness through Experiential Learning simulations before engineers return to their teams.
Conclusion
An LLM course is only as good as what you can build after it.
The skills that matter are not the ones that help you pass a quiz. They are the ones that help you reason about a broken RAG pipeline at 11 PM, or explain to a CTO why fine-tuning is the wrong call for their use case, or optimise an inference endpoint that is costing the team $4,000 a month in GPU time.
That level of fluency takes a structured curriculum, real projects, and instructors who have been in those situations. Start there and the rest follows.
Explore CloudThat’s Generative AI with AWS training programs or speak to the team about how the GenAI consulting practice can accelerate your team’s AI roadmap.
Key Takeaways
- LLM engineering is a distinct discipline from prompt engineering. Production work involves architecture, deployment, and evaluation, not just crafting prompts
- Prerequisites matter. Python confidence and a basic neural network mental model save you weeks of confusion later
- The four LLM types (base, instruction-tuned, RLHF-aligned, domain-specific) shape every technical decision you make when building AI apps
- RAG, fine-tuning, and agent frameworks are the three skill clusters with the highest immediate employment value
- Tool fluency matters. LangChain, LlamaIndex, Hugging Face, and AWS Bedrock are the core production stack for most teams
- Projects reveal gaps that video courses hide. Build pipelines that fail so you learn how to fix them
- Self-paced video alone is a slow path to production readiness. Instructor-led programs with labs compress the timeline significantly
- Security awareness (OWASP LLM Top 10, prompt injection) is not optional for engineers putting LLMs in front of real users
- AWS-specific LLM skills (Bedrock, SageMaker, Lambda integration) are increasingly requested in enterprise engineering roles
- The gap between “finished a course” and “ready to work on a team” closes faster with supervised, hands-on training than with independent study
Already in IT? Switch to Cloud & Earn 55% More
- Weekend Batches
- Dedicated Career Support
- Official AWS Labs
About CloudThat
FAQs
1. Is an LLM course very difficult if you already know Python?
ANS: – Python fluency gives you a solid starting point. The learning curve is steepest around transformer internals and distributed training concepts. Most developers with 2 to 3 years of coding experience find the engineering side manageable. It is the ML theory that takes deliberate study.
2. What is the best LLM course for developers who want to work on AWS?
ANS: – A course that covers Amazon Bedrock, SageMaker, and agent frameworks built on AWS is the most directly applicable. Look for programs that include hands-on lab time with these services, not just conceptual walkthroughs.
3. How much time does LLM training take per week?
ANS: – Expect 8 to 12 hours per week minimum for meaningful progress. Trying to learn LLMs in 1-hour weekend sessions will stretch the timeline significantly. Intensive programs with structured labs compress the timeline more effectively than self-paced options.
4. Which LLM is most in demand for enterprise applications?
ANS: – Claude (via Bedrock), GPT-4 (via Azure OpenAI), and Llama 3 (open-source, fine-tunable) are the most commonly used in enterprise production. The ability to work across models matters more than being expert in one.
5. Do I need to know how to train an LLM from scratch?
ANS: – No. Pre-training a model from scratch requires infrastructure most teams do not have and budgets most companies will not approve. Focus on fine-tuning, RAG, and working with foundation models via APIs. That is where the practical engineering work is.
6. What are the 4 types of LLMs I should know?
ANS: – Base models (pre-trained, no instruction tuning), instruction-tuned models (trained on task examples), RLHF-aligned models (trained with human feedback for safety), and domain-specific models (fine-tuned for a particular field like medicine or law).
7. Is LLM engineering the same as prompt engineering?
ANS: – No. Prompt engineering is one skill within a much larger discipline. LLM engineering also covers model selection, RAG architecture, fine-tuning, evaluation, deployment, monitoring, and cost optimization. Prompt engineering is the entry point, not the destination.

WRITTEN BY Himisha Raval
Himisha Raval is a Digital Marketing Manager at CloudThat with a strong command of search engine optimization, web analytics, link building, and content strategy. She brings a data-driven approach to digital marketing, helping IT companies strengthen their online presence, improve search rankings, and generate consistent leads across channels. Beyond execution, she plays an active role in ideation, campaign strategy, and website performance optimization. Outside of work, she balances her analytical side with a love for travel, nature painting, and dancing.











Comments