

 Login
Login

 June 8, 2022
June 8, 2022|
Voiced by Amazon Polly |
1. Introduction
To regularly examine its performance and stay ahead of its competition, every firm requires business intelligence. A powerful BI system is always supported by massive volumes of raw data, which is filtered into valuable information utilizing Extract Transform and Load techniques (ETL). The valuable data is then evaluated, passed via Machine Learning pipelines, and fed into a BI reporting system that gives significant insights to a company’s decision-makers. Although the raw data is initially kept in large database systems, it must be refined through numerous data pipelines. The data must be kept in a different mode during the procedure to be updated and processed later.
Though there are various options for storing high-volume, high-velocity data, such as Data Warehouses and Data Lakes, each has its own restrictions. So enter the Data Lakehouse, which combines the capabilities of a warehouse with a data lake to store massive amounts of data. This article will learn about Data Lakehouse and what Databricks has to offer with its Delta Lake.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
2. What is a Data Lakehouse?
Before we get into the Lakehouse, let us go through some of the constraints of a Data Warehouse and a Data Lake.
Limitations of a Data Warehouse: Even though a data warehouse can store massive amounts of data for BI reporting,
- It’s not very scalable when it comes to raw data storage.
- Involves high maintenance costs
- It does not support ML use cases.
Limitations of a Data Lake: Though Data Lake is a cost-efficient way to store large volumes of data,
- It does not facilitate data transactions.
- It is challenging to store constantly changing data, which causes data to become isolated and stale.
- Poor performance on big data.
- Not well-organized, and data versioning comes at a considerable expense.
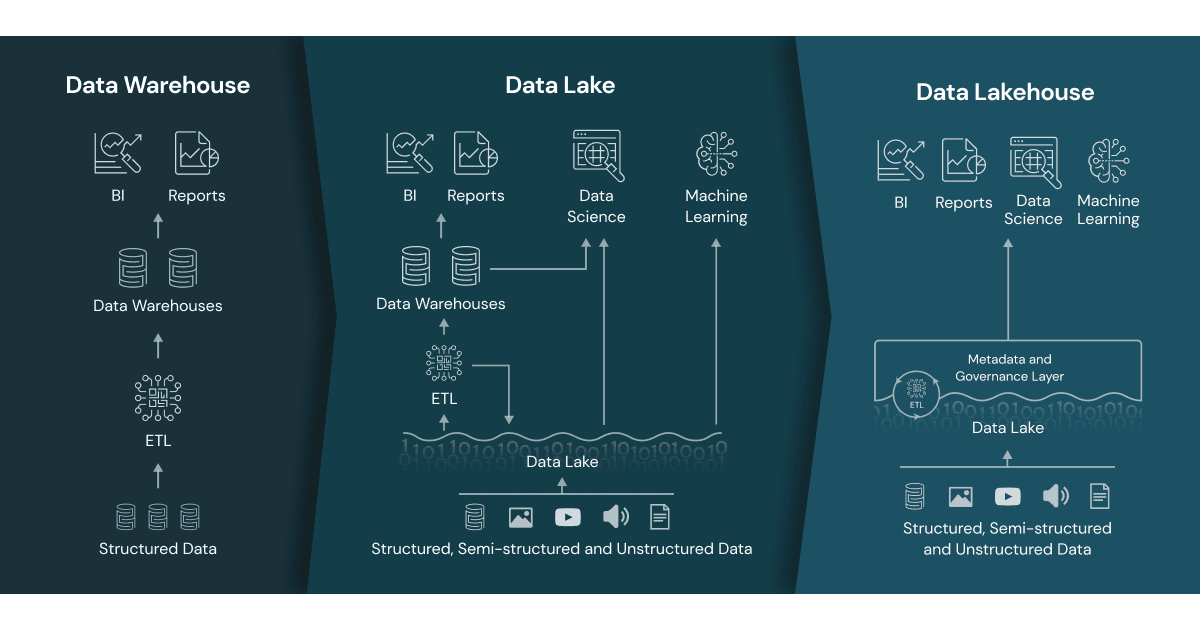
Image 1: Differences between a Data warehouse, Data Lake, and a Lakehouse
Data Lakehouse is an architectural paradigm that combines a data warehouse and a data lake, allowing for flexible and cost-effective storage and access to massive volumes of raw data in multiple formats. It enables the development of reliable data pipelines with the support of ACID (Atomicity, Consistency, Isolation, Durability) transactions.
3. What is Databricks Data Lakehouse?
Databricks Data Lakehouse is a Data storage Platform powered by Delta Lake, an independent open-source project. Delta Lake provides ACID transactions, handles metadata, and unifies streaming and batch data processing for ML and Analytics workloads.
Databricks tightly integrates the Lakehouse and compute platform to provide a unified, adaptable, and secure platform for Data Engineering, Analytics, Business Intelligence, Data Science, and Machine Learning applications. Unlike other data warehousing solutions, Databricks Lakehouse offers a low-cost, dependable data solution that can be managed across different clouds.
4. Data Lakehouse Architecture for Unified Analytics Platform
Databricks offers an analytics platform linked with the Lakehouse and gives users tools for BI and non-BI workloads such as data science and machine learning. The diagram depicts multiple levels of the Lakehouse architecture utilized by the analytics platform.
- Data Lake Layer: The storage layer is where all the structured, semi-structured, and unstructured data is stored. Databricks can integrate with your existing delta lake and can connect to various cloud storages on AWS, Azure, and GCP.
- Structural Transactional Layer: This consists of the Delta Lake. It connects with the data lake layer providing ACID transactions on Spark, Schema Enforcement, Upserts, Deletes, and Time travel on data. Delta Lake stores data as versioned parquet files and a delta log file that keeps track of the transactional logs of the data.
- Delta Engine: Delta Engine is a High-Performance Query Engine that runs on Delta Lake’s top. It consists of a Caching Layer, Execution Engine, and Query Optimizer, which work together to accelerate the performance of Delta Lake on SQL and Data Frame workloads. Delta Engine leverages the power of modern CPU architectures and Apache Spark APIs to deliver significantly accelerated data operations
- Workspace Environment: The Lakehouse is integrated with a workspace that provides access to various tools required for Data Engineering, ML, and BI workloads.

Image 2: Databricks Lakehouse Platform. Source Databricks
5. Advantages of Databricks Data Lakehouse Platform

- Unified Cloud Platform for all Data operations: Databricks incorporates all the essential data tools into a single platform providing a one-stop solution for Data Storage, Engineering, analytics, and BI workloads. It includes features like AutoML, MLflow, feature store, and model registry, which aid in developing efficient ML solutions.
- Simplifies Data Management: The Lakehouse architecture eliminates multiple tools for managing data and helps the consumers know about their data. After understanding essential statistical insights and the raw data quality, users can use Databricks to build their transformation logic and cleaning techniques.
- Optimized for Real-Time Applications: Eliminates redundancy on data by maintaining reliable data pipelines for ETL and BI workloads. Features like Auto-loader and Delta Engine optimize the jobs by efficiently handling continuous data streams and Big Data queries.
- Multi-Cloud Compatibility: Databricks platform can be hosted on multiple clouds like AWS, AZURE, and GCP. Across all clouds, the Databricks Lakehouse Platform provides you with a unified administration, security, and governance experience.
- Easy Integrations with External Services: Databricks provides Partner Connect, which directly connects with various partner solutions. Check here about all the Databricks Integrations, Databricks partners | and Databricks on AWS
- Secure, reliable, and cost-effective: With a simplified data flow and a single source of truth approach, data security issues on Databricks are easier to manage. Databricks can fully integrate with cheap object stores like Amazon S3, Azure Blob Storage, etc., as underlying data lakes, which would reduce the storage costs.
6. Conclusion
Databricks serves as a unified cloud Lakehouse service that encapsulates tons of built-in tools and features to handle data at various levels. It is unarguably one of the best solutions for handling Big Data workloads on the cloud.
CloudThat assists businesses in developing effective BI solutions by using the capabilities of Databricks on multiple cloud platforms. Across platforms, we provide an end-to-end solution for diverse Data Science, ML, and BI reporting applications.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat
FAQs
1. Is Databricks Managed Service?
ANS: – Databricks currently offers 2 types of deployment options. One is Databricks-Managed in which the whole infrastructure is managed by Databricks, and the other one is Customer-Managed where the customer has the freedom to control the infrastructure.
2. How is Databricks deployed on the cloud?
ANS: – Databricks supports deployment on multiple cloud platforms. It is currently deployable on AWS, Azure, and GCP.
3. Is Databricks a Data Warehouse?
ANS: – Databricks combines the powers of a Data Lake and a Data Warehouse, harnessed with the power of Apache Spark to run ML, Analytic, and BI Workloads. Databricks offers way more features than a Warehouse.
4. Who should use Databricks?
ANS: – Any company/firm who wants to find powerful insights from their data using ML and Analytics could use Databricks because of its wide range of offerings. Databricks with its interactive workspace and pre-built solutions, aid Data Engineers, Analysts, and Scientists in developing efficient Big Data and ML solutions.
5. What Programming Languages are supported by Databricks Workspace?
ANS: – Databricks supports Python, Scala, R, and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch, scikit-learn, etc. Users can also download their custom Python, R, or Scala Packages from the repository.
6. What is the pricing of Databricks?
ANS: – While using Databricks customers encounter 2 types of prices, The Infrastructure price, and the Databricks pricing. The Infrastructure cost is for the back-end resources which are deployed on the cloud for Databricks like Virtual Networks, Virtual Machines, storage services like S3, Blob Storage, etc. The Databricks cost is for the software usage. Databricks charges its customer based on the DBU Consumption(Databricks Unit), which is a normalized unit of processing power on the Databricks. Similar to cloud services, Databricks offers to Pay as you go as well as Committed use models. For more information on pricing, visit Databricks Pricing. Can Databricks be integrated with other Cloud Services? Ans: Databricks provides a wide range of integrations with other cloud services. =]CloudThat has partnered with Databricks where we offer combined solutions on advanced cloud infrastructure and help organizations solve complex data problems. Learn more about Databricks offerings here.

WRITTEN BY Sai Pratheek











Comments