

 Login
Login

 November 28, 2025
November 28, 2025|
Voiced by Amazon Polly |
In the era of big data, organizations are generating and consuming massive volumes of structured and unstructured data. Traditional data warehouses struggle with scalability and flexibility in managing this deluge of information. This is where data lakes come in – offering a centralized repository that allows you to store all your data at any scale, whether structured, semi-structured or unstructured.
Amazon Web Services (AWS) provides a robust suite of tools that simplify the implementation and management of a scalable, cost-effective and serverless data lake. This blog explores how to build a data lake architecture using Amazon S3, AWS Glue and Amazon Athena, detailing how these services work together to provide a seamless and powerful data analytics solution. Additionally, you can work on any cloud platform if you possess a basic understanding of data analysis.
Start Learning In-Demand Tech Skills with Expert-Led Training
- Industry-Authorized Curriculum
- Expert-led Training
What Is a Data Lake?
A data lake is a centralized storage repository that can hold a vast amount of raw data in its native format until it is needed. Unlike a data warehouse, a data lake can store all types of data, from relational databases to social media feeds to log files, without requiring data transformation or a predefined schema.
Key Benefits:
- Scalability: Handle petabytes of data with ease.
- Flexibility: Store any kind of data in any format.
- Cost-effectiveness: Pay only for the storage and compute you use.
- Advanced analytics: Run analytics and machine learning directly on raw data.
Core AWS Services for Data Lakes
To build a modern serverless data lake on AWS, three core services are commonly used:
- Amazon S3 – Storage Layer
Amazon S3 (Simple Storage Service) is a highly scalable, durable and secure object storage service offered by AWS. One of its key features is unlimited storage capacity, allowing users to store and retrieve any amount of data at anytime from anywhere on the web. S3 provides high durability, with 99.999999999% (11 9s) durability, ensuring that data is redundantly stored across multiple facilities.
Lifecycle management is another powerful feature, enabling users to automate the transition of objects between different storage classes or delete them after a specific period, reducing storage costs. S3 offers a range of storage classes (such as S3 Standard, S3 Intelligent-Tiering, S3 Glacier and S3 Glacier Deep Archive) to optimize cost based on data access patterns.
Best practice: Organize S3 buckets using a folder structure like:
s3://your-data-lake/raw/, s3://your-data-lake/processed/, s3://your-data-lake/curated/
- AWS Glue – ETL and Metadata Catalog
AWS Glue is a fully managed serverless data integration service that simplifies the process of discovering, preparing and transforming data for analytics and machine learning. One of its core features is the Glue Data Catalog, which acts as a centralized metadata repository, making your datasets easily searchable and queryable across services like Athena and Redshift Spectrum.
Glue offers automated schema discovery through crawlers that scan data stored in sources such as Amazon S3 and automatically infer the schema. It supports ETL (Extract, Transform, Load) jobs, allowing users to build transformation workflows using either a visual interface (Glue Studio) or custom scripts in PySpark or Scala.
Use case: Set up a crawler to scan raw S3 data daily and update your catalog tables, ensuring Athena always queries the latest data.
- Amazon Athena – Query Layer
Amazon Athena is a serverless interactive query service that allows users to analyze data directly in Amazon S3 using standard SQL. One of its key features is that it requires no infrastructure setup or management, enabling users to start querying data immediately without provisioning servers.
Athena is built on Presto, a high-performance distributed SQL engine that supports complex queries, including joins, window functions and subqueries. It integrates seamlessly with the AWS Glue Data Catalog, allowing users to query structured and semi-structured data with rich metadata support. Athena supports various file formats such as CSV, JSON, ORC, Avro and Parquet, optimizing performance and reducing query costs when using columnar formats.
Putting It All Together: Data Lake Architecture
Below is a reference architecture showing how these services combine in a modern, serverless data lake setup.
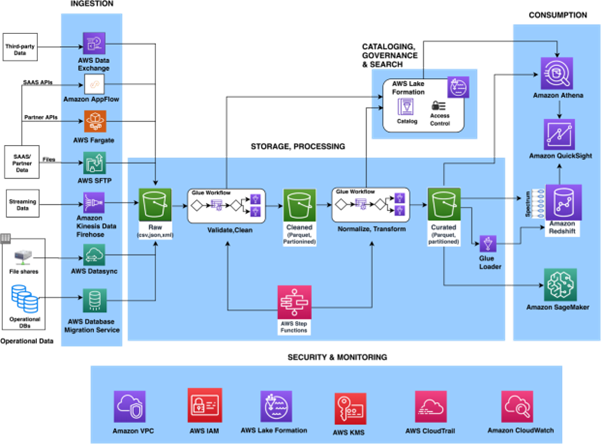
Source: Serverless data lake centric analytics architecture – AWS Serverless Data Analytics Pipeline
Example Flow with Images
Here’s how data flows through the architecture, in sync with the visuals:
- Ingestion → Raw Zone: Data is ingested (e.g. via Kinesis or batch) and stored in s3://datalake/raw/.
- Crawling & Cataloging: Glue Crawler runs, detects schemas and partitions, and updates Glue catalog.
- Transformation: Glue Jobs clean or enrich data, output to s3://datalake/processed/ or …/curated/.
- Querying: Using Athena, analysts run SQL queries against tables defined in the Data Catalog (pointing to S3 paths).
- Visualizing / Reporting: Finally, results are shown in dashboards or used in ML pipelines.
Sample Use Case: Log Analytics
Scenario:
A company wants to analyze SSH, RDP traffic to the EC2 instances to identify access IPs.
Steps:
- Enable VPC flow log on the subnet where the critical EC2 instances are running. Push to logs to S# bucket
- Logs are ingested into s3://my-VPC-logs/raw/.
- A Glue Crawler scans the logs and creates a table VPC_Flow_logs in the Data Catalog.
- Athena queries will help you monitor the SSH and RDP traffic.
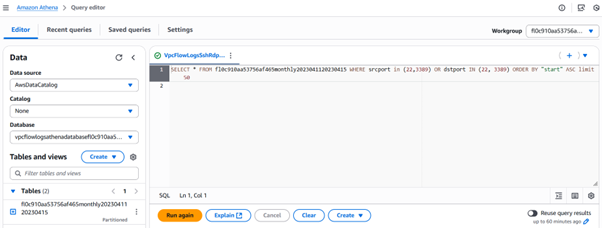
Athena query analyzing VPC Flow Logs to identify SSH and RDP access IPs from EC2 instances.
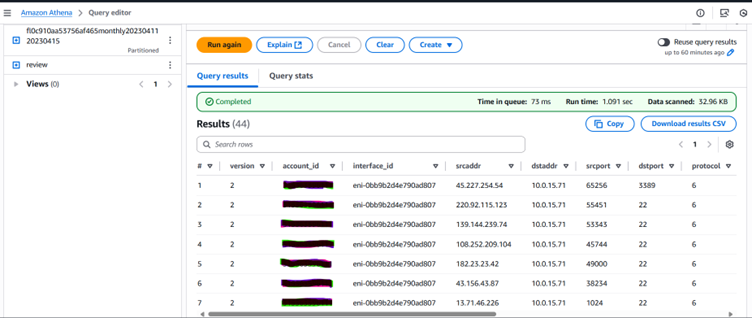
Athena query output listing IP addresses and ports from VPC Flow Logs to monitor SSH and RDP access to EC2 instances.
Best Practices for Data Lake on AWS
- Partition your data (e.g., by date or region) to speed up Athena queries.
- Use columnar formats like Parquet or ORC to reduce data scan size.
- Implement versioning and lifecycle policies in S3 for cost control.
- Secure your data using encryption (SSE-S3, SSE-KMS) and IAM policies.
- Automate workflows with AWS Step Functions or Glue Workflows.
Enhancing Your Skills with Comprehensive Data Analytics Courses
To further strengthen expertise in areas such as data analytics, AI professionals and organizations can benefit from structured training programs. Platforms like CloudThat, which offer AWS, GenAI, Azure and AI/ML courses, provide a blend of foundational learning and hands-on practice. Such training enables learners to apply modern analytics concepts effectively in real-world business scenarios.
Modern Data Lake
Building a data lake using Amazon S3, AWS Glue and Amazon Athena provides a powerful, flexible and cost-effective solution for managing and analyzing big data. With minimal setup, organizations can ingest diverse data types, catalog them automatically and run SQL-based queries, all without managing infrastructure. This architecture enables businesses to make data-driven decisions more quickly and at scale, unlocking the full potential of their data assets.
Upskill Your Teams with Enterprise-Ready Tech Training Programs
- Team-wide Customizable Programs
- Measurable Business Outcomes
About CloudThat

WRITTEN BY Mahek Tamboli
Mahek is a Senior Subject Matter Expert at CloudThat, specializing in AWS Architecting. With 13 years of experience in IT and education industry, she has trained over 2000 professionals/students to upskill in hardware, network, MCSA, RHCSA and multi cloud. She is an authorized trainer for AWS and GCP. Known for simplifying complex concepts and delivering interactive and hands-on sessions, she brings deep technical knowledge and practical application into every learning experience. Mahek passion for continuous learning reflects in her unique approach to learning and development.











Comments