

 Login
Login

 March 16, 2026
March 16, 2026|
Voiced by Amazon Polly |
Overview
Humans have always interacted most naturally through voice. Before writing, we had a conversation. In ways that text can only approximate, we use our voices to command, comfort, and negotiate. The expectation was straightforward when AI promised to introduce voice into digital experiences: it should feel like speaking to a real listener.
For the most part, that expectation has not been fulfilled. Under the surface, the voice AI systems that drive today’s smart home appliances and customer support lines are incredibly ungainly structures. Your voice is converted to text, then to thought, then to a response, and finally back to speech. The conversation ceases to feel like a conversation somewhere along those four steps.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
Both approaches are trying to do the same thing, let users speak naturally to a machine and get a timely, human-sounding response. The gap is in the method.
The Amazon Nova Sonic adopts a different strategy, with a single model that bypasses the text middleman completely and directly generates audio output after receiving audio input. Barge-in detection, tool usage, multilingual support for English, French, Italian, German, Spanish, Portuguese, and Hindi, as well as a bidirectional streaming API via HTTP/2, are among the built-in features.
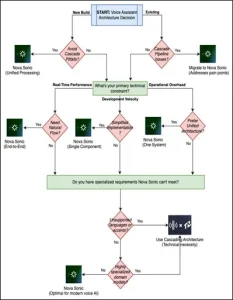
Neither is always better. The remainder of this article explores your constraints, which are the only factor that will determine the best option.
What a Cascading Pipeline Actually Costs You?
In a cascading pipeline, latency is added at each stage; it doesn’t cancel out; it stacks. You are battling the physics of sequential inference even with contemporary async frameworks like Pipecat or LiveKit. As a result, the rhythm sounds a little strange, like a bad video call. Unconsciously changing their behavior to fit the machine, users adjust by speaking more slowly and avoiding interruptions.
Errors are also compound. The LLM receives a different question and produces a confident, entirely incorrect response if the STT model interprets “flight” as “fright.” The TTS then delivers this response with complete conviction. Tracing failures across four systems, each with its own logs and failure modes, is known as debugging.
Every handoff in a cascading pipeline is a place where the meaning of how you spoke disappears.
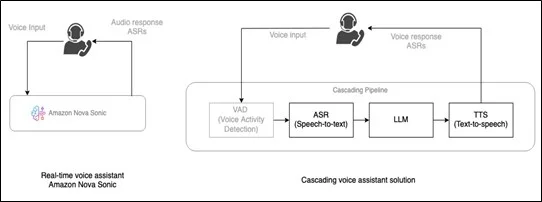
One Model to Replace Four
The Amazon Nova Sonic pipeline isn’t superior. It’s a completely different concept. Nova Sonic processes speech directly, comprehending not only the words you say but also the prosody, tone, and style of how you say them, rather than translating your voice into text and losing acoustic context in the process.
According to Amazon, this model “adapts the intonation, prosody, and style of the generated speech response to align with the context and content of the speech input.” Simply put, it listens the same way a human does.
On latency, third-party benchmarking by Artificial Analysis places Nova Sonic’s Time to First Audio (TTFA) at 1.09 seconds, compared to 1.18 seconds for OpenAI’s GPT-4o Realtime API and 1.41 seconds for Google’s Gemini Flash 2.0. Small in absolute terms, significant in conversational ones. Amazon also positions Amazon Nova Sonic as nearly 80% less expensive than GPT-4o Realtime API, a meaningful delta at scale.
Native barge-in detection means users can interrupt mid-sentence, and the model maintains context rather than ploughing through a pre-generated answer nobody asked for.
When the Old Way Still Wins?
Amazon Nova Sonic does not solve every problem. If your use case requires a fine-tuned ASR model trained on medical terminology, a TTS system built on your specific brand voice, or a language outside Nova Sonic’s current support, cascading still wins. Modularity has real value when individual components are genuinely best-in-class for your domain.
Voice AI Is Finally Growing Up
The cascading architecture was a practical solution built from the components available at the time. That composability came at a cost of latency, error propagation, and engineering overhead that users absorbed by adjusting their behavior to suit the machine.
Amazon Nova Sonic represents a different contract: meet users where natural conversation already lives. Whether it delivers fully depends on your use case and constraints. But the direction is clear. The question for any team building voice applications today is no longer whether unified speech-to-speech is the future, it is whether your specific needs make that future available to you right now.
Conclusion
Match the architecture to your actual constraints. If Amazon Nova Sonic’s capabilities cover your use case, the unified model wins on simplicity, cost, and conversational quality. If you need specialized domain models or languages that it does not yet support, cascading still earns its place.
Either way, the bar has moved. Users know when a system is making them work harder than they should. Building something that clears that bar is no longer optional it is the entry point.
Drop a query if you have any questions regarding Amazon Nova Sonic and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. What's the difference between cascading pipelines and Amazon Nova Sonic?
ANS: – Cascading pipelines chain four separate models with compounding latency. Amazon Nova Sonic uses a single unified model that processes voice directly, preserving tone and emotion lost in text-to-speech conversion.
2. What are Amazon Nova Sonic's advantages?
ANS: – Faster response (1.09s), 80% lower cost, native interruption handling, and preservation of vocal nuance. Supports seven languages, including English, French, German, Spanish, Italian, Portuguese, and Hindi.

WRITTEN BY Dharyatra Chauhan











Comments