

 Login
Login- Consulting
- Training
- Partners
- About Us
x
AWS, Cloud Computing
 5 Mins Read
5 Mins Read

 April 11, 2022
April 11, 2022Disaster Recovery (DR) is a crucial aspect of any cloud deployment. In my previous blog, we discussed Understanding the Vitality of Data Backup and Disaster Recovery in an Organization.
Cloud providers like Amazon and Microsoft will readily suggest that you must have a Disaster Recovery and Business Continuity strategy. A Disaster Recovery Plan is part of the Business Continuity strategy. For example, you would place your production servers in a top-tier data center with no single point of failure on the power and network connections.
Thus, you are not hinged to a single location, data center, or network when connected to the Cloud. So even if one building loses power after a vicious storm, your operation can stay online and continue to roll.
Amazon Web Services (AWS), the leading cloud service provider today, has outlined four different techniques for disaster recovery preparation. Each technique can be exercised in specific scenarios. Previously we learned about AWS Pilot Light and AWS Warm Standby.
Among the four types of Disaster Recovery options provided by AWS, selecting a particular DR strategy could be based on the benefits of RTO (Recovery Time Objective) and RPO (Recovery Point Objective).
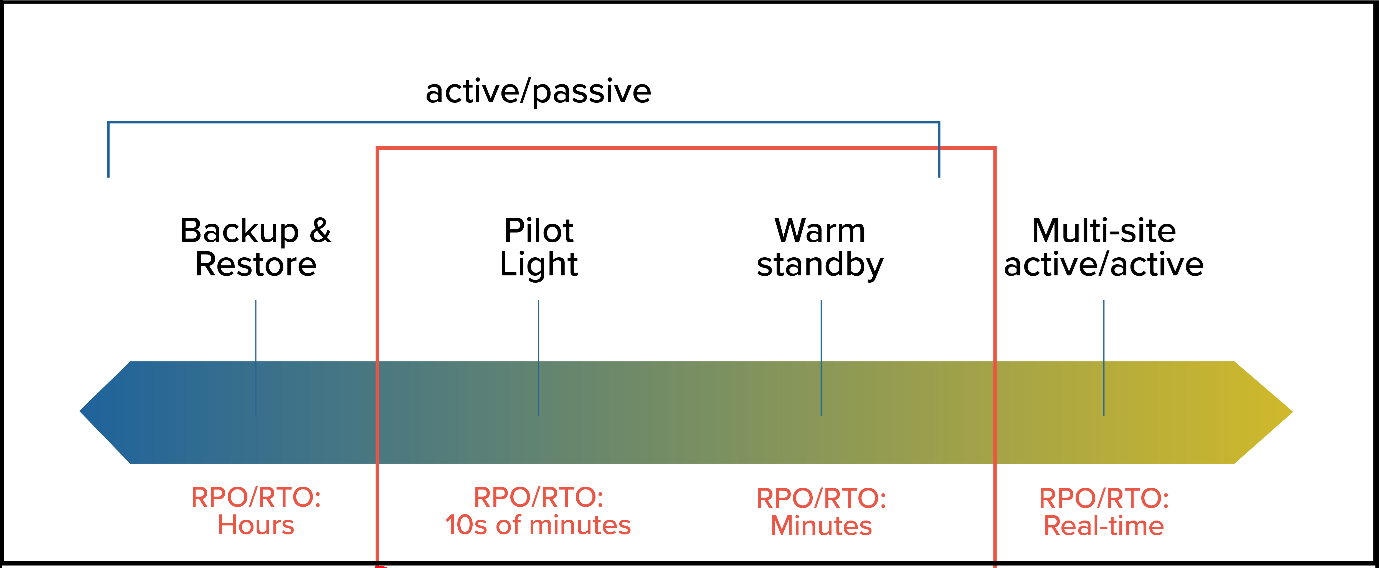
Compared to other strategies, Multisite Active/Active provides the most decisive advantages, and the RTO and RPO are the lowest. This means that the workloads that have Multisite Active/Active defined for them will be back in action in real-time if any disastrous events occur. However, the company must weigh the cost and the complexity of operating active stacks in multiple regions.
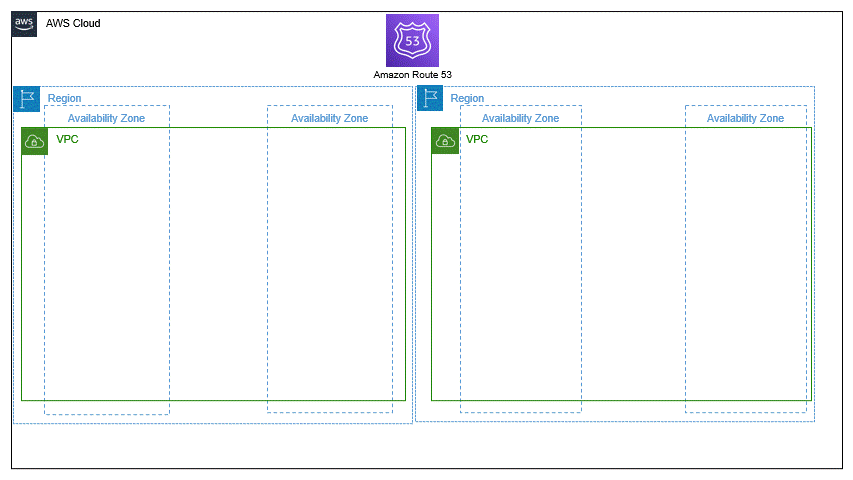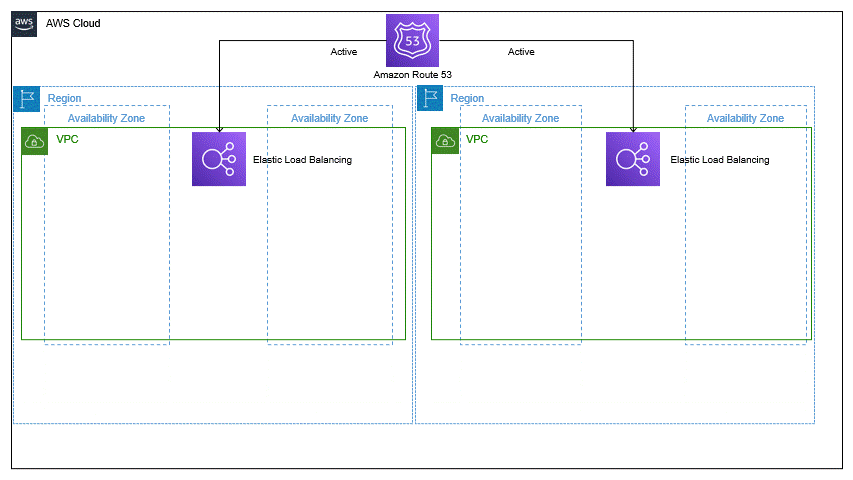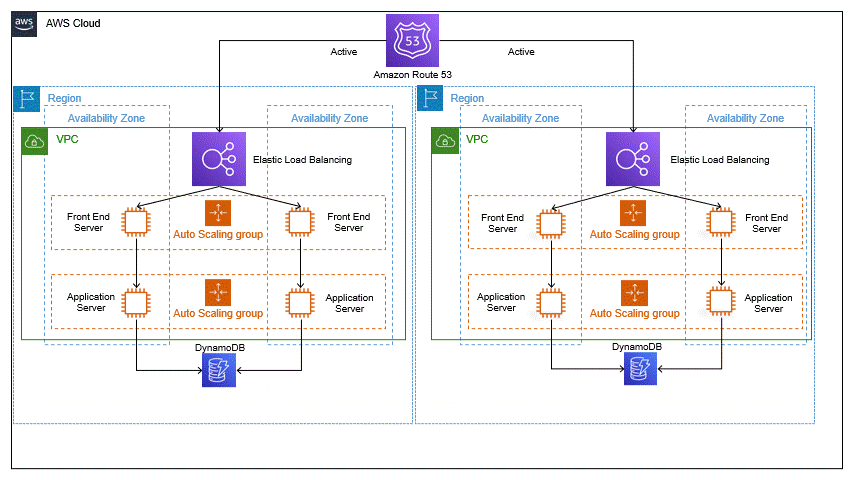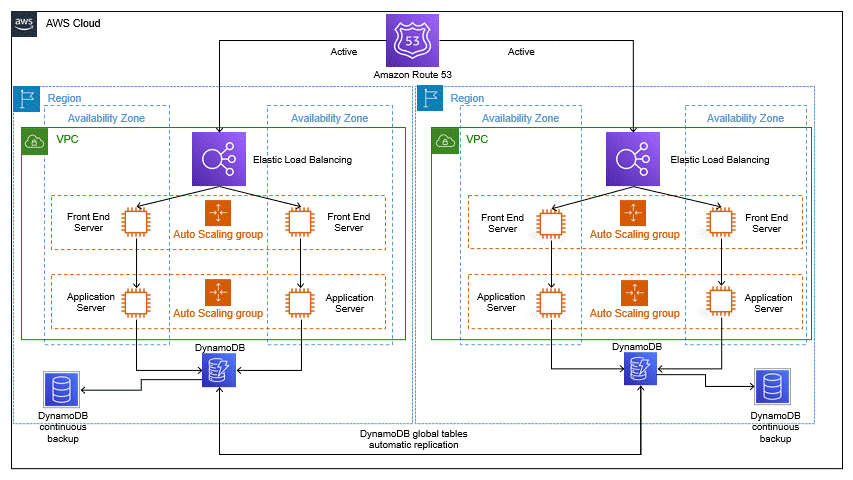
The above architecture diagram shows only two regions; however, multiple regions can be used. A highly available multiple Availability Zone (AZ) workload stack is hosted in every Region. The data in every Region is replicated live in the data stores and backed up. In any disastrous event such as data deletion or corruption, the data backup can be restored quickly and efficiently.
In the multi-region active/active strategy, if your application doesn’t work in one Region due to some failure, failover will route the traffic to another healthy Region. For every Region, data is replication is streamlined between the data stores and backed up. Moreover, it protects against data
In a Multisite Disaster recovery setup, we can have multiple Read/write patterns. These are the different ways to make read and write requests to your application databases.
“Local region” is the Region where a request is routed for a read or a write operation. We make sure that all the read and write requests are served from the Local Region in this pattern. It will not only help in reducing the latency but also reduce the potential for network error.
Amazon DynamoDB can be a great example to help us understand this pattern. If we use DynamoDB global tables, which replicate the tables to multiple regions, all the write operations to the table in any Region are replicated to other Regions within a second.
We choose a specific region as a global write region in this pattern. All the write operations will be performed in this Region, while read requests can be served from any region.
We can use Amazon Aurora as an example here. If we deploy an Aurora global database, a primary cluster is deployed to your global write region. Then, read-only instances, Aurora Replicas, are deployed to other AWS Regions. The replication continues to these read-only instances with a typical latency of under a second.
Sometimes your application may not be suited to incur the round trip to the global write Region with every write for a heavy workload. We can use a write partitioned pattern to mitigate this in such cases.
With this pattern, each item or record is assigned a home Region. This can be done based on the Region it was first written to, or found on a partition key in the record (such as user ID) by pre-assigning a home Region for each key value. Here, the motive is to map records to a home Region close to where most write requests will originate. We can utilize Amazon DynamoDB Global Tables in such use cases as DynamoDB global tables accept writes in all Regions.
While considering the multisite active/active strategy, ensure that you are ready for the complexity and cost of implementing it in multiple regions. This DR provides the quickest recovery time (lowest RTO) and minimal data loss (RPO). In addition, implementing this across various Regions can provide low latency to users, independence, and separation from each site globally.
A dedicated team of experts to move your existing workloads for a well-designed DR strategy can benefit your business and improve the security posture for your critical applications.
As a pioneer in the Cloud consulting realm, CloudThat is AWS (Amazon Web Services) Advanced Consulting Partner, AWS authorized Training Partner, Microsoft Gold Partner, and Winner of the Microsoft Asia Superstar Campaign for India: 2021. Our team has designed and delivered various Disaster Recovery strategies to our customers.
We are on a mission to build a robust cloud computing ecosystem by disseminating knowledge on technological intricacies within the cloud space. Our blogs, webinars, case studies, and white papers enable all the stakeholders in the cloud computing sphere to advance in their businesses.
To get started, go through our Expert Advisory page and Managed Services Package that is CloudThat’s offerings. Then, you can quickly get in touch with our highly accomplished team of experts to carry out your migration needs. Feel free to drop a comment or any queries that you have about Disaster Recovery Strategies, AWS services, or any other AWS services, and we will get back to you quickly.
The backup and restore strategy is the most cost-effective DR strategy that every team should have. It allows users to procure their data in case of a hardware failure easily. The RTO/RPO for this plan is up to 24hrs.
However, backup and restore may not be suitable as they will cause significant disruption. For this reason, Multisite Active/ Active is chosen, and it is a fault-tolerant system. It requires constant testing and configuration to ensure that all the operations are running seamlessly. The RTO/ RPO is a few seconds, and thus all the systems work in real-time, giving a smooth and seamless user experience. It could, however, be an expensive option.
|
Voiced by Amazon Polly |
Prarthit Mehta, CTO of CloudThat’s Cloud Consulting Services, brings over a decade of experience in driving digital transformation across industries. He leads technology strategy, cloud development, security compliance, and IT operations. An AWS Partner Ambassador and holder of multiple AWS and Microsoft Azure certifications, he brings deep expertise in cloud and big data platforms. Prarthit has delivered solutions across diverse industry domains and actively mentors aspiring technologists, enhancing innovation and growth in the tech community.
SHARE



AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AI/ML, Cloud Computing
By Livi Johari
Jul 20, 2026

AWS, Cloud Training
By Himisha Raval
Jul 14, 2026

AWS, DevOps
By Himisha Raval
Jul 14, 2026



Artificial Intelligence, Data science
By Himisha Raval
Jul 14, 2026
Our support doesn't end here. We have monthly newsletters, study guides, practice questions, and more to assist you in upgrading your cloud career. Subscribe to get them all!

Comments