

 Login
Login

 June 22, 2026
June 22, 2026|
Voiced by Amazon Polly |
Overview
Any cloud-native application today needs reliable, continuous network communication. From microservice applications and database connectivity to streaming applications and any form of API-driven application, TCP is an integral part of establishing consistent communication between components of an application. Improper TCP connection management on Amazon EC2 can lead to a variety of problems, such as connection drops, increased application latency, and timeouts.
AWS recently published best practices for managing TCP connections for applications running on Amazon EC2. These best practices are relevant to application architects, cloud administrators, DevOps practitioners, and other IT professionals who run complex distributed applications.
In this blog post, we will investigate the significance of proper TCP connection management on Amazon EC2 and how it affects applications.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Understanding TCP Connection Management on Amazon EC2
TCP is a connection-oriented protocol that establishes a reliable communication channel between systems. Applications deployed in an EC2 environment usually require establishing TCP connections for various purposes, including accessing databases, using HTTP, working with message queues, and connecting to other backends.
On the other hand, having idle TCP connections can be problematic in the cloud. The reason is that all AWS components responsible for networking, load balancing, NAT gateways, and ENIs monitor existing connections, which are terminated if they remain idle after their timeout.
According to AWS, Nitro v6 instances, introduced recently, have a reduced timeout of 350 seconds compared to older generations. This is why applications relying on such connections should handle timeouts appropriately and establish keepalives to keep them alive.
Otherwise, organizations can face:
- Unexplained disconnections
- Failed database connections
- Missing persistent HTTP connections
- Retransmitting packages due to exceeding the limit of active connections
Importance of Connection Tracking
Security groups in AWS use connection tracking to maintain the state of traffic across the network. Each connection uses tracking resources. When the number of connections being tracked exceeds the allowed limit on an instance, there may be packet drops and failures when establishing new connections.
Monitoring tools offered by AWS include:
|
1 2 |
conntrack_allowance_available conntrack_allowance_exceeded |
This information can help monitor connection tracking and take preventive action in case of failure.
Effective connection management helps optimize:
- Networking
- Availability of applications
- Scalability
- Performance of the infrastructure
- Resource efficiency
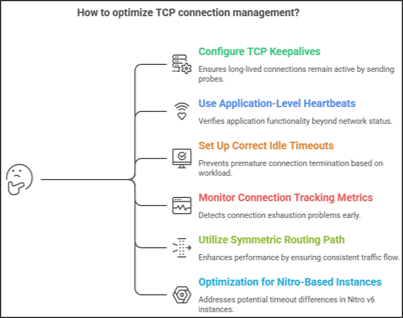
Best Practices for TCP Connection Management
- Configure TCP Keepalives
It is important to enable TCP keepalives when using long-lived TCP connections, as the probes help maintain the connection.
When TCP keepalive is not activated, the following will terminate connections after becoming idle:
For Linux environments, AWS recommends setting kernel parameters such as:
|
1 2 3 |
net.ipv4.tcp_keepalive_time = 240 net.ipv4.tcp_keepalive_intvl = 60 net.ipv4.tcp_keepalive_probes = 3 |
Such settings ensure that probes are sent before the connection is terminated due to idle timeouts.
Connection keepalive intervals should be set to values lower than the infrastructure timeouts. If the timeout is 350 seconds, it is best to trigger connection probes before 240 seconds.
- Use Application-Level Heartbeats
While TCP keepalives help check the network connection status, it cannot be guaranteed that the application operating over that network is functioning correctly.
Application-level heartbeat can be used to check whether the application is alive. As per AWS guidelines, it is necessary to implement both TCP and application-level heartbeats to manage the critical infrastructure.
Some examples are:
- Application health checks
- Messaging queue confirmation
- Heartbeat API endpoints
This can help increase the fault-tolerance capabilities of our system.
- Set Up Correct Idle Timeouts
Rather than leaving timeouts to the default AWS settings, it is always recommended to set idle timeout values based on the workload explicitly.
Idle timeout configurations can be achieved with the help of the following AWS features:
- AWS Command Line Interface (CLI)
- AWS Management Console
- CloudFormation
- Terraform
In cases of heavy connection usage, services like firewalls, streaming apps, and high-scale APIs require a timeout value to be set.
It may depend on the specific use case whether long or short timeouts are beneficial.
- Monitoring Connection Tracking Metrics
Monitoring network metrics is essential to detecting connection exhaustion issues before they affect the production environment.
As per AWS, the following metrics must be monitored regularly:
- Active number of connections
- Connection drops
- Timeout errors
- Utilization of network bandwidth
- Reconnection requests
Cloud services such as Amazon CloudWatch enable alerts and scaling based on the data generated.
- Utilization of Symmetric Routing Path
If traffic uses different paths for entry and exit from the instance, it is called asymmetric routing, and, as AWS notes, this impacts performance when using connection tracking.
The following measures should be taken to enhance performance:
- Use symmetric routing paths
- Maintain simplicity in network infrastructure
- Utilize Network ACLs where possible
- Limit unnecessary tracking of flows
- Optimization for Nitro-Based Instances
While migrating applications to Nitro v6 instances, care must be taken as there will be differences in default timeout settings.
Application teams handling applications with:
- Persistent database connections
- Streaming applications
- LONG running API calls
- Stateful communications
must test timeout behavior.
Real-World Impacts of Suboptimal TCP Connection Management
Suboptimal TCP connection management has both performance and cost impacts, leading to increased CPU and network usage and higher latency due to excessive reconnections.
Examples of real-world issues caused by poor TCP connection management include:
- Persistent database pool reconnections
- Inconsistent API service availability
- Random streaming session disconnections
- Service outage due to microservice failover
The effects may be exacerbated in high-scale production environments with many service dependencies.
Implementing TCP connection management best practices enables the development of a better-performing, scalable cloud architecture.
Conclusion
TCP connection management is an issue that only arises when networks experience unexplained connection timeouts or disruptions. As cloud application architectures become ever more complex and scaled out, good connection management will become more essential.
According to AWS, there are best practices for setting TCP connection timeouts, idle-time monitoring, and TCP keepalive settings. The recommended practices are especially relevant for AWS Nitro instances, which have short default timeouts.
Drop a query if you have any questions regarding TCP, and we will get back to you quickly.
Making IT Networks Enterprise-ready – Cloud Management Services
- Accelerated cloud migration
- End-to-end view of the cloud environment
About CloudThat
FAQs
1. How does the concept of keepalive work in Amazon EC2 for TCP?
ANS: – Keepalive involves sending probe packets across an idle TCP connection to prevent it from being closed due to inactivity.
2. Why are idle TCP connections closed on AWS?
ANS: – Idle timeout is used in AWS network components such as ENIs, NAT gateways, and load balancers to prevent unnecessary resource usage.
3. What are connection tracking metrics on AWS?
ANS: – Conntrack_allowance_available and conntrack_allowance_exceeded are examples of metrics that help you monitor connection tracking allowance limit usage and packet drops.

WRITTEN BY Akanksha Choudhary
Akanksha works as a Research Associate at CloudThat, specializing in data analysis and cloud-native solutions. She designs scalable data pipelines leveraging AWS services such as AWS Lambda, Amazon API Gateway, Amazon DynamoDB, and Amazon S3. She is skilled in Python and frontend technologies including React, HTML, CSS, and Tailwind CSS.











Comments