

 Login
Login

 May 22, 2026
May 22, 2026|
Voiced by Amazon Polly |
Overview
Manual ETL pipelines struggle with the unpredictable nature of real-world enterprise data, schema drift, inconsistent formats, missing values, and constantly changing source systems. Intelligent data preparation agents built using Amazon Bedrock Agents introduce a reasoning layer that can autonomously profile, cleanse, transform, and validate data before it reaches analytics or AI workloads. This article covers the architecture, action group design, orchestration patterns, escalation handling, and cost considerations involved in building scalable agentic data preparation pipelines on AWS.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Introduction
60-80% of a data scientist’s time goes to preparation, not modeling, not analysis, not generating insights. Anaconda has reported this consistently since 2020. The bottleneck isn’t that data prep is technically hard. It’s contextual, repetitive, and full of edge cases that break rigid ETL pipelines. A date column that’s usually YYYY-MM-DD but occasionally arrives as DD/MM/YYYY. A vendor feed that adds columns without notice.
Traditional ETL handles the expected. An intelligent agent handles both because it reasons about data rather than just processing it.
The Data Preparation Bottleneck
Data scientists spend 60-80% of their time on data preparation, not modeling, not analysis, not insight generation. This figure, consistently reported by Anaconda’s State of Data Science surveys from 2020 through 2025, represents the single largest productivity drain in data-driven organizations.
The challenge isn’t that data preparation is technically difficult. It’s contextual, repetitive, and full of edge cases that break rigid ETL pipelines. A date column that’s usually YYYY-MM-DD but occasionally arrives as DD/MM/YYYY. A vendor feed that adds new columns without notice. Customer records with 47 different spellings of “United States.”
Traditional ETL handles the expected. It fails on the unexpected. An intelligent agent handles both because it reasons about data rather than just processing it.
What Makes Data Preparation “Agentic”?
The distinction between automated ETL and agentic data preparation:
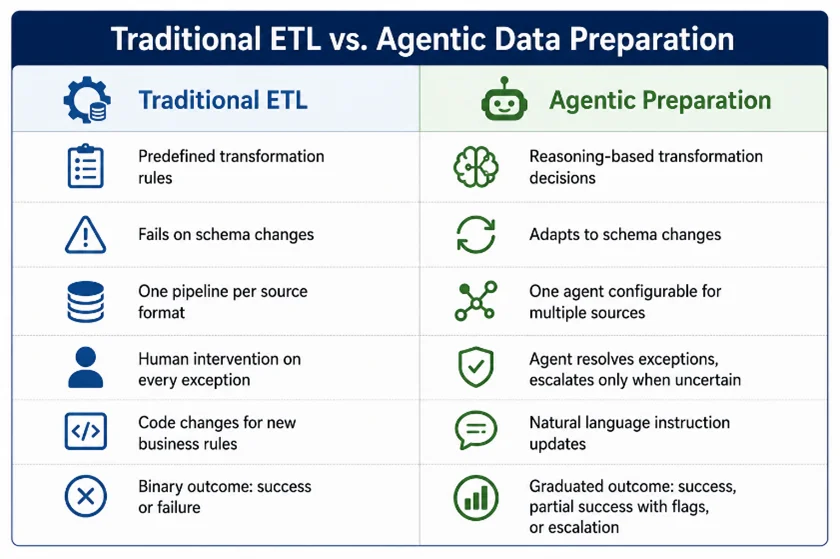
An agentic approach doesn’t eliminate rules, it adds a reasoning layer that handles situations rules don’t cover.
Architecture on Amazon Bedrock
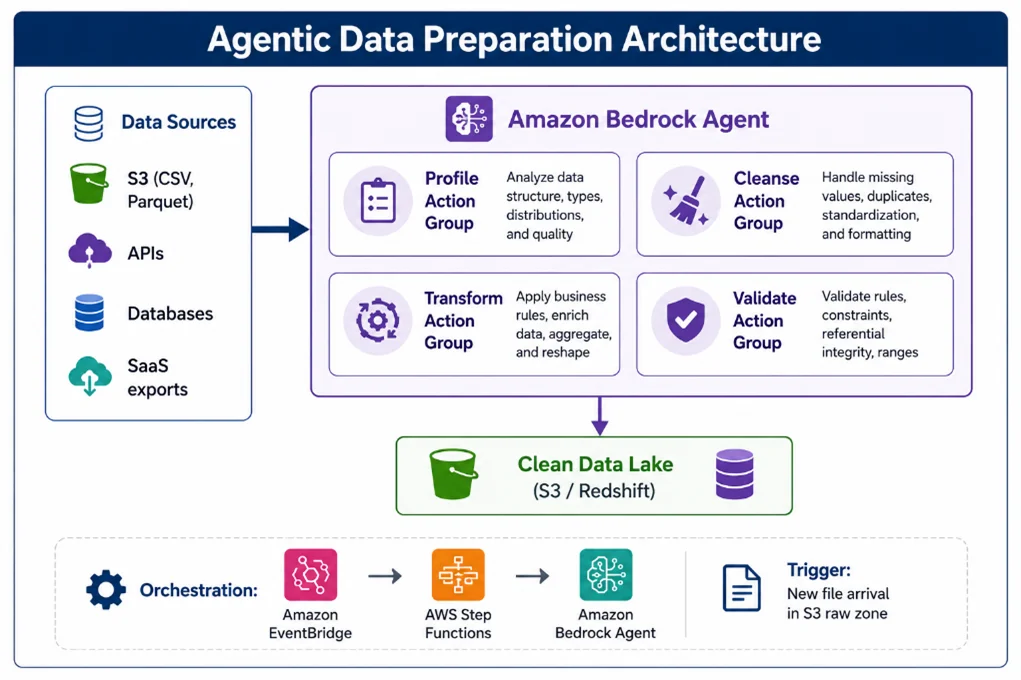
Building the Agent: Four Action Groups
Amazon Bedrock Agents operate through Action Groups, defined capabilities that agents can invoke during their reasoning process. For data preparation, four action groups cover the complete workflow:
- Profile Action Group
Purpose: Understand what the data contains before transforming it.
Capabilities:
- Row count, column count, data type inference
- Null percentage per column
- Unique value distribution and cardinality
- Statistical outlier detection
- Schema comparison against the expected target format
Implementation: AWS Lambda function that reads the source file from Amazon S3, runs profiling using pandas or AWS Glue DataBrew APIs, and returns a structured assessment.
- Cleanse Action Group
Purpose: Fix quality issues identified during profiling.
Capabilities:
- Date format standardization (detect source format, convert to ISO 8601)
- Text normalization (trim whitespace, fix encoding, standardize casing)
- Missing value handling (impute from lookup tables, flag for review, or apply business defaults)
- Deduplication using configurable matching rules (exact, fuzzy, or composite key)
Implementation: AWS Lambda function executing transformation logic. The agent decides which cleansing operations to apply based on the profiling results, not a hardcoded sequence.
- Transform Action Group
Purpose: Reshape data to match the target schema.
Capabilities:
- Column mapping (source → target with type conversion)
- Business rule application (currency conversion, unit standardization)
- Enrichment via reference data joins (lookup tables in Amazon DynamoDB or Amazon S3)
- Aggregation, pivoting, or flattening as required by the target format
- Validate Action Group
Purpose: Confirm the output meets quality thresholds before loading.
Capabilities:
- Completeness checks (required fields populated)
- Referential integrity (foreign keys resolve)
- Business rule validation (amounts within expected ranges, dates logical)
- Quality score generation (0-100 composite metric)
- Comparison against historical baselines (flag anomalies)
Agent Instructions: Defining Behavior
The agent’s system prompt controls its decision-making. This is where domain expertise gets encoded:
Operating principles:
1. Always profile before cleansing.
2. Preserve original data.
3. Log every transformation decision with reasoning.
4. Minimum quality score for auto-load: 85/100.
5. Below threshold: escalate with findings summary.
6. Unknown columns: quarantine and notify.
7. Missing values:
– Impute if confidence >90%
– Otherwise, flag as requires_review
8. Never silently drop records.
Orchestration Pattern
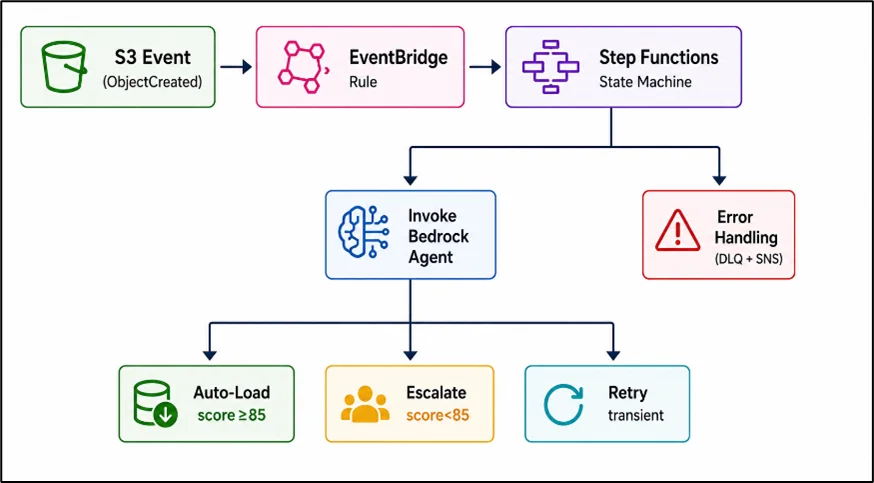
When a file arrives in the Amazon S3 raw zone, EventBridge triggers an AWS Step Functions workflow. The workflow invokes the Amazon Bedrock Agent, which autonomously profiles, cleanses, transforms, and validates. Based on the quality score, the workflow routes to auto-load, escalation, or retry.
Practical Results
Organizations implementing this pattern report:
- Processing time reduction: 4-6 hours of manual preparation reduced to 10-15 minutes of agent execution
- Quality improvement: Average quality scores increase from 75-80 (manual, inconsistent) to 90-95 (agent, consistent)
- Exception handling: 85-90% of data quality exceptions resolved autonomously; only novel or ambiguous cases escalate
- Engineer reallocation: Data engineers shift from preparation tasks to pipeline optimization, data modeling, and analytics development
Cost Considerations
For a typical daily data preparation workload (50,000 rows, 20 columns, 5 source files):
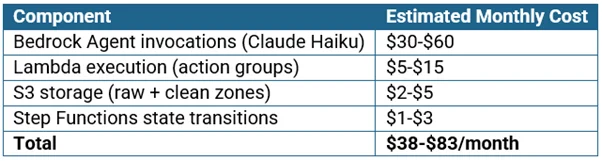
Compare this to the engineering time it replaces: even at conservative estimates, 10 hours/week of data engineer time at $70/hour represents $2,800/month. The ROI is immediate.
When to Escalate, Not Automate
The agent should escalate (not attempt resolution) when:
- A completely new file format appears with no matching schema
- Quality score drops below threshold for three consecutive runs (systemic issue)
- Data volume deviates more than 10x from the historical baseline
- PII is detected in fields not designated for sensitive data
- Business rule conflicts arise (two valid rules produce contradictory results)
The goal is to handle the predictable 90% autonomously, with reliable escalation for the unpredictable 10%.
Conclusion
Start with one data feed, prove the pattern, and scale from there. The ROI is immediate: $38- $83/month in agent costs, replacing thousands of engineering hours.
Drop a query if you have any questions regarding Agentic data preparation and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Does this approach require training a custom model?
ANS: – No. Amazon Bedrock Agents use foundation models (Claude, Nova) with tool-use capabilities. You configure the agent’s behavior through instructions and action groups, no model training or fine-tuning required. The intelligence comes from the model’s reasoning and your domain-specific tools.
2. How does the agent handle data it has never seen before?
ANS: – The profiling action group analyzes structure and content regardless of whether the agent has seen that format before. For known schemas, it applies established transformation rules. For unknown schemas, it attempts to infer mappings based on column names and data patterns. If confidence is low, it quarantines and escalates rather than guessing.
3. Can this integrate with existing AWS Glue or DataBrew pipelines?
ANS: – Yes. The action groups can invoke AWS Glue jobs or DataBrew recipes as part of their execution. The agent adds a reasoning layer on top of existing transformation infrastructure, it decides which Glue job to run and with what parameters, rather than replacing the transformation engine itself.
4. What about data governance and lineage tracking?
ANS: – Every agent decision is logged with full reasoning. Integrate with AWS Glue Data Catalog for metadata management and AWS CloudTrail for audit trails. The agent’s action logs provide transformation lineage, documenting what changed, why, and when, which satisfies data governance requirements for regulated industries.

WRITTEN BY Vignesh J
Vignesh Jagadeesan is the Head of Presales at CloudThat with 12+ years of experience driving digital transformation for Public Sector, SMB, and Enterprise customers across India and the USA. He specializes in Cloud Consulting, Data Management, MDM, Analytics, and enterprise modernization. Vignesh has led transformation engagements spanning cloud adoption, analytics, managed services, and enterprise solutioning across government, BFSI, healthcare, retail, manufacturing, and energy sectors, partnering with business stakeholders and cloud partners to deliver scalable, outcome-driven solutions.










Comments