

 Login
Login

 January 20, 2026
January 20, 2026|
Voiced by Amazon Polly |
Introduction
In the first blog of this series, we established that deterministic data lineage must originate at execution time, with pipeline scripts emitting structured lineage events through logging. That foundation solves the most critical problem: capturing what actually happened during data processing on Amazon Web Services.
However, raw lineage events, even when perfectly structured, are not sufficient to support real-world use cases such as impact analysis, root-cause investigation, regulatory audits, or platform-wide optimization. Execution logs are inherently event-oriented, while lineage questions are relationship-oriented. Engineers do not ask for logs, they ask questions like:
- Which upstream datasets contributed to this metric?
- What transformations derive this column?
- What changed between two executions of the same pipeline?
- Which downstream assets are impacted if this dataset changes?
Answering these questions requires lineage to be modeled, normalized, and queried as a graph. This is where the second layer of the platform becomes essential: converting deterministic lineage events into a structured lineage graph and enriching it with semantic understanding using controlled GenAI capabilities.
This blog focuses on how to design that layer using Amazon Neptune as the lineage graph store and Amazon Bedrock for GenAI-assisted enrichment, without compromising determinism, trust, or auditability.
Pioneers in Cloud Consulting & Migration Services
- Reduced infrastructural costs
- Accelerated application deployment
Problem Context: Why Raw Lineage Events Do Not Scale
Even with strict logging contracts, lineage events present several challenges when consumed directly.
- Event Streams Do Not Represent Relationships
Lineage events are temporal records. They capture when something happened, not how it relates to everything else. Without aggregation and normalization, reconstructing lineage requires repeatedly scanning large volumes of events.
- Naming and Semantic Drift
In real platforms, the same dataset may appear under different aliases:
- s3://raw/orders/
- raw_orders
- orders_raw_v2
Similarly, columns may be renamed, derived, or merged. Deterministic logs alone cannot always resolve these semantic relationships.
- Column-Level Lineage Is Often Implicit
While the source and target datasets are explicit, column-level derivations are often embedded within SQL expressions or Spark transformations. Capturing this level of detail deterministically would require intrusive instrumentation and complex parsing logic.
These gaps motivate the introduction of a lineage structuring and enrichment layer, built on top of the execution-grade lineage captured earlier.
High-Level Architecture Overview
This phase introduces a lineage modeling plane that sits between raw lineage events and downstream consumers.
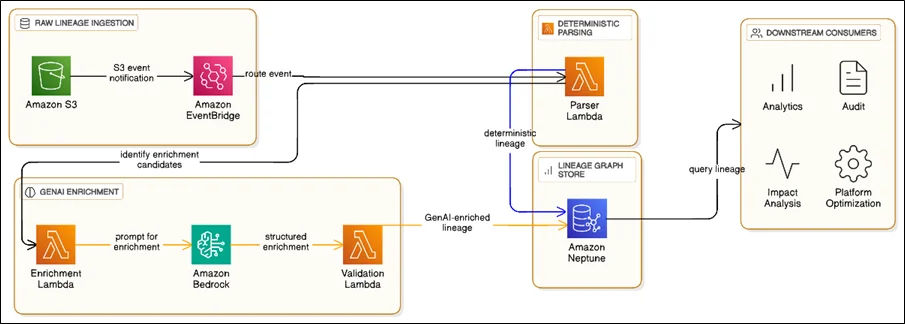
Core AWS Services Used
- Amazon EventBridge – Routing lineage events for processing
- AWS Lambda – Deterministic parsing and orchestration
- Amazon Bedrock – Controlled GenAI enrichment
- Amazon Neptune – Persistent lineage graph database
- Amazon S3 – Replayable source of lineage events
No third-party graph engines, AI services, or external parsers are involved.
Deterministic Lineage Parsing and Normalization
Event Ingestion Flow
- Validated lineage events stored in Amazon S3 (from Blog 1)
- Amazon S3 event notifications publish events to Amazon EventBridge
- Amazon EventBridge routes events to a deterministic parser AWS Lambda
This AWS Lambda function performs non-negotiable, rule-based processing:
- Normalizes dataset identifiers
- Resolves environment-specific aliases
- Creates or updates canonical dataset nodes
- Establishes execution-to-dataset edges
At this stage, no AI inference is applied. Everything is deterministic and traceable.
Why a Graph Database Is Mandatory?
Relational databases struggle with lineage because lineage is inherently recursive and multi-hop. Queries such as “find all downstream datasets impacted by this source” or “show the full upstream dependency chain” become prohibitively complex and slow.
Amazon Neptune is chosen because it:
- Natively supports relationship traversal
- Scales horizontally with large graphs
- Supports temporal and attribute-rich edges
- Integrates cleanly with AWS IAM and VPC security
Core Lineage Graph Model
Node Types
- Dataset – Physical or logical data assets
- Column – Individual attributes within datasets
- Pipeline – Logical ETL definitions
- Execution – A specific pipeline run
- SchemaVersion – Immutable schema snapshots
Edge Types
- READS_FROM – execution → dataset
- WRITES_TO – execution → dataset
- DERIVES_FROM – column → column
- EXECUTED_AS – pipeline → execution
Each edge carries metadata:
- event_time
- source_type (LOG, STATIC, GENAI)
- confidence_score
- valid_from / valid_to
This model supports time-aware lineage, which is critical for audits and historical comparisons.
Controlled Use of GenAI with Amazon Bedrock
Why GenAI Is Needed (and Why It Is Dangerous)
Certain lineage relationships cannot be reliably extracted through deterministic rules alone, particularly:
- Column-level derivations from SQL expressions
- Semantic meaning of transformations
- Alias resolution across heterogeneous pipelines
However, GenAI introduces risks, hallucinations, inconsistencies, and a lack of explainability. Therefore, the design follows a strict rule:
GenAI may enrich lineage, but it may never create authoritative lineage.
GenAI Enrichment Pipeline
- Deterministic parser identifies enrichment candidates
Examples:- Complex SQL transformations
- Ambiguous column mappings
- Non-standard naming conventions
- Candidate payloads are sent to Amazon Bedrock with tightly constrained prompts.
- The model returns structured JSON only, never free text.
- A validation AWS Lambda:
- Enforces schema compliance
- Assigns confidence scores
- Tags inference source as GENAI
- Enriched edges are written to Neptune alongside deterministic edges, never overwriting them.
Example GenAI Prompt Pattern
You are given a SQL transformation.
Identify column-level derivations.
Return JSON with:
– source_column
– target_column
– transformation_type
No explanation text.
This prompt design minimizes ambiguity and ensures repeatability.
Trust and Confidence Model
Every lineage edge in Neptune includes a confidence score:
- 1.0 – deterministic, execution-confirmed
- 0.7–0.9 – static or partially inferred
- < 0.7 – GenAI advisory inference
Downstream consumers can explicitly filter lineage paths based on confidence thresholds. This prevents inferred lineage from contaminating regulatory or production-critical use cases.
Failure Scenarios and Safety Guarantees

At no point does AI failure compromise deterministic lineage integrity.
Operational Considerations
Replay and Reprocessing
Because Amazon S3 stores all lineage events immutably, the entire lineage graph can be rebuilt or re-enriched without re-running pipelines. This is critical for:
- Model upgrades
- Prompt refinements
- Schema evolution
Cost Control
- Amazon Bedrock is invoked only for flagged candidates
- Batch enrichment minimizes token usage
- Amazon Neptune is used only for structured graph queries, not raw storage
Conclusion
Structuring lineage into a graph is the inflection point where lineage transitions from logging to intelligence. By combining deterministic parsing with carefully constrained GenAI enrichment, AWS-native services enable a lineage system that is both accurate and expressive.
Amazon Neptune provides the structural backbone for traversal, impact analysis, and historical comparison, while Amazon Bedrock fills semantic gaps that deterministic systems cannot reasonably address on their own.
In the final blog of this series, we will demonstrate how this lineage graph becomes a full-fledged operational product, powering support workflows, analytics, and platform-level optimization.
Check out for Part 1 and Part 3 here.
Drop a query if you have any questions regarding Structuring lineage and we will get back to you quickly.
Empowering organizations to become ‘data driven’ enterprises with our Cloud experts.
- Reduced infrastructure costs
- Timely data-driven decisions
About CloudThat
FAQs
1. Why not use GenAI to infer all lineages automatically?
ANS: – Because inferred lineage without deterministic grounding is not auditable or trustworthy for production and compliance use cases.
2. Can Neptune handle very large lineage graphs?
ANS: – Yes. Amazon Neptune is designed for large-scale graph workloads and supports horizontal scaling and low-latency traversals.
3. What happens if GenAI enrichment is disabled?
ANS: – The system continues to function with deterministic lineage only, without any loss of correctness.

WRITTEN BY Bineet Singh Kushwah
Bineet Singh Kushwah works as an Associate Architect at CloudThat. His work revolves around data engineering, analytics, and machine learning projects. He is passionate about providing analytical solutions for business problems and deriving insights to enhance productivity. In his quest to learn and work with recent technologies, he spends most of his time exploring upcoming data science trends and cloud platform services, staying up to date with the latest advancements.











Comments